你好,TensorFlow!
作者:Aaron Schumacher
TensorFlow作为一个项目比你能想象到的更大。事实上,它是深度学习的一个库。这个项目与谷歌之间的关系帮助它获得了很多的关注。但是在这些喧哗的表面下,这个项目还是有些独特的元素值得仔细的关注,包括:
TensorFlow的核心库不仅仅只用于深度学习,它也适用于更广范围的机器学习技术。
线性代数和其他内部核心也明确地开放出来
除了核心的机器学习功能,TensorFlow还包括它自己的日志系统,自己的交互式日志可视化工具,甚至是它自己深度工程化的服务架构
TensorFlow的执行模式和Python的scikit-learn包以及大部分R语言的工具都不一样
这些都是很酷的东西。但是特别是对于那些第一次接触机器学习的人,TensorFlow有更多可以学习使用的东西。
TensorFlow是如何工作的?让我们把它拆开,来仔细看看并理解它的内部情况。我们会探索数据流图(这些图定义了你的数据会经历的计算),了解如何使用TensorFlow的梯度下降法训练模型,以及如何用TensorBoard可视化你的TensorFlow工作。后面的例子不会解决工业级的机器学习问题,但是它会帮助你理解构成TensorFlow的所有基础组成部分,包括今后你想要构建的。
Python和TensorFlow里的命名和执行
TensorFlow管理计算的方法和Python通常的管理方法并不是完全不同。借用哈德利·威科姆的话,对于两者,需要谨记是对象并没有名字(参见图1)。为了理解Python和TensorFlow的工作的异同点,让我们先看看他们是怎么引用对象和处理运行的。
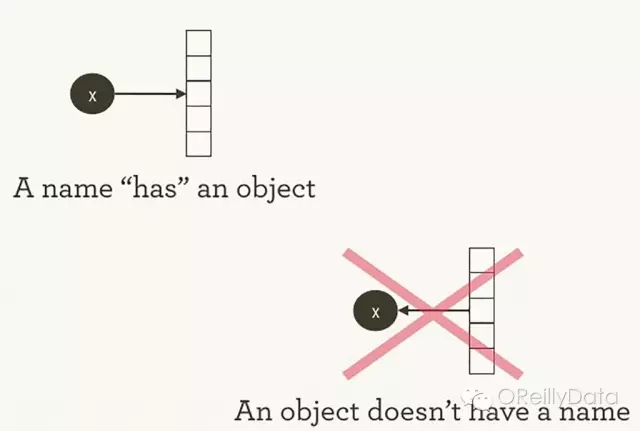
图1:名字对应着对象,但反之则不是。哈德利·威科姆授权使用
变量名在Python代码里并不是它们所指代的东西;它们仅仅是对象的指针。因此当你在Python里面写下foo = []和bar = foo时,这并不仅仅表明foo等于bar,实际上foo就是bar,它们都是对于同一个列表对象的指针。
>>> foo = []
>>> bar = foo
>>> foo == bar
## True
>>> foo is bar
## True
如果你执行id(foo)和id(bar),就会看到结果是一样的。如果没有正确地理解这种一致性就可能会导致出人意料的程序漏洞,特别是对于像列表这样的可变数据结构。
Python内部会管理所有的对象,并跟踪所有的变量名以及他们所指代的对象。TensorFlow的图则是代表了这种管理的另一层。如我们将看到的,
当你在交互式解释器内或Shell环境内输入了一段Python表达式,它就立刻被执行了。Python总是立刻去做你要它做的事。所以如果我告诉Python运行foo.append(bar),Python就立刻append了,即便我永远也不会再用foo。
一个相比“懒”点的方法就是,当我输入foo.append(bar)后,Python在未来的某个时间去运行,并把bar给添加到foo里面。这种方式就和TensorFlow的运行方式差不多。即定义关系的动作和实际去运行产生结果的动作是完全分离的。
TensorFlow更进一步地把运算的定义和具体的执行分离开,并放到不同的地方。用一个图定义多个操作,但这些操作仅仅在一个会话里真正运行。图和会话的建立是相互独立的。图更像一个蓝图,而会话则是建筑工地。
回头看看里那个简单的Python例子,foo和bar都指向同一个列表。把bar添加到foo里面,我们把一个列表放到了它自己里面。你可以把这个数据结构想象成一个只有一个节点的图,这个节点的边指向了它自己。嵌套列表是一种图形式的表现,这与TensorFlow的运算图类似。
>>> foo.append(bar)
>>> foo
## [[…]]
而真正的TensorFlow的运算图会比这个更有趣!
最简单的TensorFlow图
为了能得到实战经验,让我们先从零开始建一个最简单的TensorFlow图。相比于一些其他的框架,TensorFlow的安装是极度简单的。这里的例子在Python 2.7版和3.3以上版本都可以运行,这用的TensorFlow版本是0.8。
>>> import tensorflow as tf
这句运行后,TensorFlow已经为我们开始管理了很多的状态。例如,已经有一个隐含的默认图存在。TensorFlow内部的默认图是存在_default_graph_stack里了,但是我们不能直接使用。我们使用tf.get_default_graph()来使用它。
>>> graph = tf.get_default_graph()
TensorFlow图里的节点被称为“运算”(operation)或“ops”。我们可以通过graph.get_operations()来得到图里的所有的运算。
>>> graph.get_operations()
## []
现在图里什么都没有。我们需要往图里放入一些我们希望TensorFlow的图里计算的东西。让我们从一个简单的常量输入开始。
>>> input_value = tf.constant(1.0)
现在这个常量已经作为图里的一个节点(一个运算)存在了。这个Python变量input_value间接地指向了这个运算,但是我们也能在这个默认图里面找到。
>>> operations = graph.get_operations()
>>> operations
## []
>>> operations[0].node_def
## name: “Const”
## op: “Const”
## attr {
## key: “dtype”
## value {
## type: DT_FLOAT
## }
## }
## attr {
## key: “value”
## value {
## tensor {
## dtype: DT_FLOAT
## tensor_shape {
## }
## float_val: 1.0
## }
## }
## }
TensorFlow内部使用protocol buffer(来存储数据)。Protocol buffer是谷歌推广的类似JSON的东西。上面打印常量运算的node_def的结果显示出TensorFlow用protocol buffer表示的列表里第一个常量的内容。
刚刚接触TensorFlow的人有时会问干嘛要弄这些TensorFlow版本的对象。为什么不能直接用Python的对象而非要定义TensorFlow的对象?TensorFlow的一个教程是这样解释的:
在Python里,为了更有效地进行数值计算,我们通常会使用例如NumPy这样的包来进行复杂的计算,比如矩阵相乘。这些包可能是用非Python的其他语言写的,从而使得效率更高。不幸的是,每个计算转换回Python后都会带来很多的开销。这些开销对于使用GPU计算或是分布式计算来说是太糟了,因为这些运算模式下的数据传输的代价很高。
TensorFlow也替Python做了一些“脏活”,但是它设法避免了这些开销。不是在Python之外独立的去运行一个个复杂的计算,TensorFlow让我们去定义一个图来描述这些交互的计算,并完全在Python之外独立地运行。这和Theano或Torch的方式比较类似。
如果仔细看看我们的input_value,就会发现这个是一个无维度的32位浮点张量:就是一个数字。
>>> input_value
##<tf.tensor ‘const:0’=”” shape=”()” dtype=”float32″>
值得注意的是,这个结果并没有说明这个数字是多少?为了执行input_value这句话,并给出这个数字的值,我们需要创造一个“会话”。让图里的计算在其中执行并明确地要执行input_value并给出结果(会话会默认地去找那个默认图)
>>> sess = tf.Session()
>>> sess.run(input_value)
## 1.0
“执行”一个常量可能会让人觉得有点怪。但是这与在Python里执行一个表达式并没有什么区别。这就是TensorFlow管理它自己的对象空间(计算图)和它自己的执行的方式。
最简单的TensorFlow神经元
现在已经有了一个会话,其中有一个简单的图。下面让我们构建仅有一个参数的神经元,或者叫权重。通常即使是简单的神经元也都会有偏置项和非一致的启动函数,但我们先不管这些。
神经元的权重不必须是常量,我们会期望这个值能改变从而学习训练数据里的输入和输出。这里我们定义权重是一个TensorFlow的变量,并给它一个初值0.8。
>>> weight = tf.Variable(0.8)
你可能会以为加一个变量是向图里加一个运算,但这一行其实是加入了四个运算。我们可以查看所有的这些运算的名字。
>>> for op in graph.get_operations(): print(op.name)
## Const
## Variable/initial_value
## Variable
## Variable/Assign
## Variable/read
我们不会每个运算都仔细看看,但很有必要至少看一个像真正运算的例子。
>>> output_value = weight * input_value
现在图里有六个运算,最后一个是相乘。
>>> op = graph.get_operations()[-1]
>>> op.name
## ‘mul’
>>> for op_input in op.inputs: print(op_input)
## Tensor(“Variable/read:0”, shape=(), dtype=float32)
## Tensor(“Const:0”, shape=(), dtype=float32)
上面的代码展示了乘运算以及它的输入:来自图里的其他运算。为了更好地理解整个图而去查看这些引用很快就会变的极度繁琐。用TensorBoard的图可视化就是可以帮助查看的。
怎么才能看到乘积是多少?我们必须“运行”这个output_value运算。但是这个运算依赖于一个变量:权重。我们告诉TensorFlow这个权重的初始值是0.8,但在这个会话里,这个值还没有被设置。tf.initialize_all_variables()函数生成了一个运算,来初始化所有的变量(我们的情况是只有一个变量)。随后我们就可以运行这个运算了。
>>> init = tf.initialize_all_variables()
>>> sess.run(init)
tf.initialize_all_variables()的结果会包括现在图里所有变量的初始化器。所以如果你后续加入了新的变量,你就需要再次使用tf.initialize_all_variables()。一个旧的init是不会包括新的变量的。
现在我们已经准备好运行output_value运算了。
>>> sess.run(output_value)
## 0.80000001
0.8 * 1.0是一个32位的浮点数,而32位浮点数一般不会是0.8。0.80000001是系统可以获得的一个近似值。
在TensorBoard里查看你的图
到目前为止,我们的图是很简单的,但是能看到她的图形表现形式也是很好的。我们用TensorBoard来生成这个图形。TensorBoard读取存在每个运算里面的名字字段,这和Python里的变量名是很不一样的。我们可以使用这些TensorFlow的名字,并转成更方便的Python变量名。这里tf.mul和我前面使用*来做乘运算是等价的,但这个操作可以让我们设置运算的名字。
>>> x = tf.constant(1.0, name=’input’)
>>> w = tf.Variable(0.8, name=’weight’)
>>> y = tf.mul(w, x, name=’output’)
TensorBoard是通过查看一个TensorFlow会话创建的输出的目录来工作的。我们可以先用一个SummaryWriter来写这个输出。如果我们只是创建一个图的输出,它就将图写出来。
构建SummaryWriter的第一个参数是一个输出目录的名字。如果此目录不存在,则在构建SummaryWriter时会被建出来。
>>> summary_writer = tf.train.SummaryWriter(‘log_simple_graph’, sess.graph)
现在我们可以通过命令行来启动TensorBoard了。
$ tensorboard –logdir=log_simple_graph
TensorBoard会运行一个本地的Web应用,端口6006(6006是goog这个次倒过的对应)。在你本机的浏览器里登陆localhost:6006/#graphs,你就可以看到在TensorFlow里面创建的图,类似于图2。
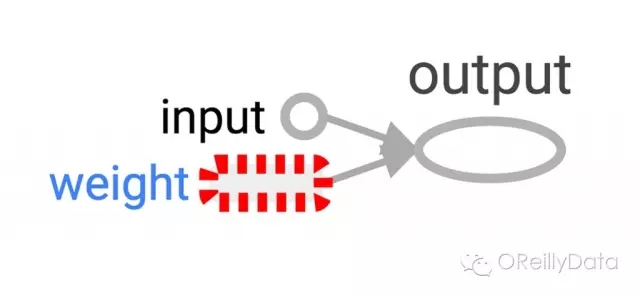
图2. 在TensorBoard里可视化的一个最简单的TensorFlow的神经元
让神经元进行学习
我们已经有了一个神经元,但如何才能让它学习?假定我们让输入为1,而正确的输出应该是0。也就是说我们有了一个仅有一条记录且记录只有一个特征(值为1)和一个结果(值为0)的训练数据集。我们现在希望这个神经元能学习这个1->0的函数。
目前的这个系统是输入1而输出0.8。但不是我们想要的。我们需要一个方法来测量系统错了多少。我们把对错误的测量称为“损失”,并把损失最小化设定为系统的目标。损失是可以为负值的,而对负值进行最小化是毫无意思的。所以我们用实际输出和期望输出之差的平方来作为损失的测量值。
>>> y_ = tf.constant(0.0)
>>> loss = (y – y_)**2
对此,现有的图还不能做什么事情。所以我们需要一个优化器。这里我们使用梯度下降优化器来基于损失值的导数去更新权重。这个优化器采用一个学习比例来调整每一步更新的大小。这里我们设为0.025。
>>> optim = tf.train.GradientDescentOptimizer(learning_rate=0.025)
这个优化器很聪明。它自动地运行,并在整个网络里恰当地设定梯度,完成后向的学习过程。
让我们看看我们的简单例子里的梯度是什么样子的。
>>> grads_and_vars = optim.compute_gradients(loss)
>>> sess.run(tf.initialize_all_variables())
>>> sess.run(grads_and_vars[1][0])
## 1.6
为什么梯度的值是1.6?我们的损失函数是错误的平方,因此它的导数就是这个错误乘2。现在系统的输出是0.8而不是0,所以这个错误就是0.8,乘2就是1.6。优化器是对的!
对于更复杂的系统,TensorFlow可以自动地计算并应用这些梯度值。
让我们运用这个梯度来完成反向传播。
>>> sess.run(optim.apply_gradients(grads_and_vars))
>>> sess.run(w)
## 0.75999999 # about 0.76
现在权重减少了0.04,这是因为优化器减去了梯度乘以学习比例(1.6*0.025)。权重向着正确的方向在变化。
其实我们不必像这样调用优化器。我们可以形成一个运算,自动地计算和使用梯度:train_step。
>>> train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
>>> for i in range(100):
>>> sess.run(train_step)
>>>
>>> sess.run(y)
## 0.0044996012
多次运行训练步骤后,权重和输出值已经非常接近0了。这个神经元已经学会了!
在TensorBoard里显示训练过程的分析
你可能对训练过程中发生了什么感兴趣,比如我们想知道每次训练步骤后,系统都是怎么去预测输出的。为此,我们可以在训练循环里面打印输出值。
>>> sess.run(tf.initialize_all_variables())
>>> for i in range(100):
>>> print(‘before step {}, y is {}’.format(i, sess.run(y)))
>>> sess.run(train_step)
>>>
## before step 0, y is 0.800000011921
## before step 1, y is 0.759999990463
## …
## before step 98, y is 0.00524811353534
## before step 99, y is 0.00498570781201
这种方法可行,但是有些问题。看懂一串数字是比较难的,能用一个图来展示就好了。仅仅就这一个需要观察的值,就有很多输出要看。而且我们希望能观察多个值。如果能用一个一致统一的方法来记录所有值就好了。
幸运的是,上面我们用来可视化图的工具也有我们需要的这个功能。
我们通过加入能总结图自己状态的运算来提交给计算图。这里我们会创建一个运算,它能报告y的当前值,即神经元的输出。
>>> summary_y = tf.scalar_summary(‘output’, y)
当你运行一个总结运算,它会返回给一个protocal buffer文本的字符串。用SummaryWriter可以把这个字符串写入一个日志目录。
>>> summary_writer = tf.train.SummaryWriter(‘log_simple_stats’)
>>> sess.run(tf.initialize_all_variables())
>>> for i in range(100):
>>> summary_str = sess.run(summary_y)
>>> summary_writer.add_summary(summary_str, i)
>>> sess.run(train_step)
>>>
在运行命令 tensorboard –logdir=log_simple_stats后,你就可以在localhost:6006/#events里面看到一个可交互的图形(如图3所示)。
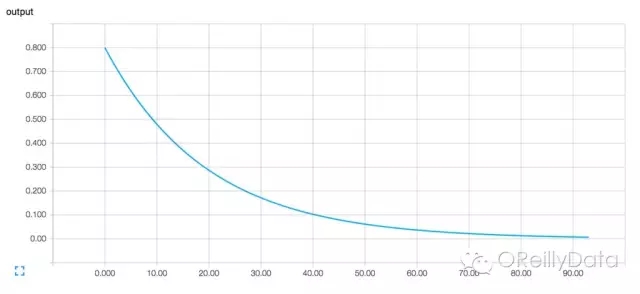
图3. TensorBoard里的可视化图,显示了一个神经元的输出和训练循环次数的关系
继续向前
下面是代码的完全版。它相当的小。但每个小部分都显示了有用且可理解的TensorflowFlow的功能。
import tensorflow as tf
x = tf.constant(1.0, name=’input’)
w = tf.Variable(0.8, name=’weight’)
y = tf.mul(w, x, name=’output’)
y_ = tf.constant(0.0, name=’correct_value’)
loss = tf.pow(y – y_, 2, name=’loss’)
train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
for value in [x, w, y, y_, loss]:
tf.scalar_summary(value.op.name, value)
summaries = tf.merge_all_summaries()
sess = tf.Session()
summary_writer = tf.train.SummaryWriter(‘log_simple_stats’, sess.graph)
sess.run(tf.initialize_all_variables())
for i in range(100):
summary_writer.add_summary(sess.run(summaries), i)
sess.run(train_step)
我们这里所演示的例子甚至比催生这篇文章的麦克·尼尔森的这篇《神经网络和深度学习》文章里的例子还要简单。对我自己,能看到这样具体的例子可以帮助理解,还可以从简单的砖头开始使用并扩展构建更为复杂的系统。
如果你想继续实践TensorFlow,可以从构建更有趣的神经元开始,或许可以使用不同的激活函数。你也可以用更有趣的数据来训练。继续添加更多的神经元,或者更多的层级。你可以查看更复杂的预制的模型,或学习TensorFlow的教程与如何使用它手册。去学吧!
感谢Paco Nathan,Ben Lorica和Marie Beaugureau 的细心编辑,从而让这篇博文真正诞生。感谢深度学习分析公司的亨利·陈,丹尼斯·梁和波·古雷,以及华盛顿特区的机器学习期刊俱乐部对本博文的早期版本的意见反馈。再次感谢Marie Beaugureau 和杰娜·韦伯对本博文的质量提升所做的杰出贡献。

Aaron Schumacher
Aaron Schumacher是深度学习分析公司的数据科学家和软件工程师。他在联合国大会和麦迪斯数据科学训练营里教授Python和R语言。Aaron曾在博思艾伦咨询公司,纽约大学和纽约市教育局任职并从事数据工作。Aaron生涯最好的霹雳舞成绩是挺近R16韩国2009大赛个人街舞的半决赛。他现在很荣幸地被评为TensorFlow 0.9版的次重要贡献者。