《用Python写网络爬虫》读书笔记
1.书籍信息
书名:Web Scraping with Python
译名:用Python写网络爬虫
作者:Richard Lawson
译者:李斌
出版社:人民邮电出版社
ISBN:978-7-115-43179-0
页数:157
2.纸张、印刷与排版
16开本,纸张较厚,行、段间距较大,字体较大。
3.勘误
本书勘误文章:http://www.pythoner.com/492.html
出版社勘误页:http://www.epubit.com.cn/book/details/4610
4.笔记与评价
阅读级别:翻译。
推荐级别:细读,适合初学者。
本书面向Python爬虫的初学者,从最基础的抓取方式起步,根据实际需求中可能碰到的问题逐步扩展,此外还介绍了一些Python爬虫常用的三方库和框架。书中没有特别高深的知识,也不会在某一方面过分深入,如果想要了解更深入的知识,可以阅读书中给出的一些参考文档用于补充。
本书中的源代码均可在作者提供的git上进行下载。读者可以很轻松地搭建出与作者相似的环境来进行实践,当然作者也提供了一个demo网站用于为读者服务,不过如果想要学习更加清晰,还是建议大家自行搭建这个demo网站,并自行尝试编码。
实践部分的几个网站,可能不太符合国情,所以大家可以使用一些国内常用于爬取的站点(比如豆瓣、知乎等)来进行实践,这样更能加深自己的理解。
本书共分为9章。
第1章介绍背景,并编写最简单的爬虫。
第2章介绍了正则表达式、BeautifulSoup、lxml三种抓取页面的方式,并对其性能进行对比。
第3章中介绍了磁盘和数据库(MongoDB)两种数据库缓存方式。
第4章引入了并发爬虫执行的概念。当然,这里需要注意的是,爬虫的速率应该进行一定的限制,避免被所爬取网站的防爬策略ban掉。
第5章处理动态表单。AJAX提交表单的方式目前也十分常见,因此传统的方式经常会无法获取到渲染后的源代码,需要使用本章中介绍的逆向工程或是渲染引擎来解析网页。另外,本章还介绍了著名的Selenium框架。
第6章实现自动化表单交互。
第7章处理验证码,介绍了OCR和打码平台两种方式。
第8章介绍了著名的Scrapy框架。
第9章在几个真实网站上进行了实践。
巧合的是,有一本英文同名的著作也在前几个月出版了中文版本(《Python网络数据采集》),过段时间把那本书看完之后,我也会写一下那本书的读书笔记,并谈一下两本书的区别。
5.思维导图
思维导图(图片版)
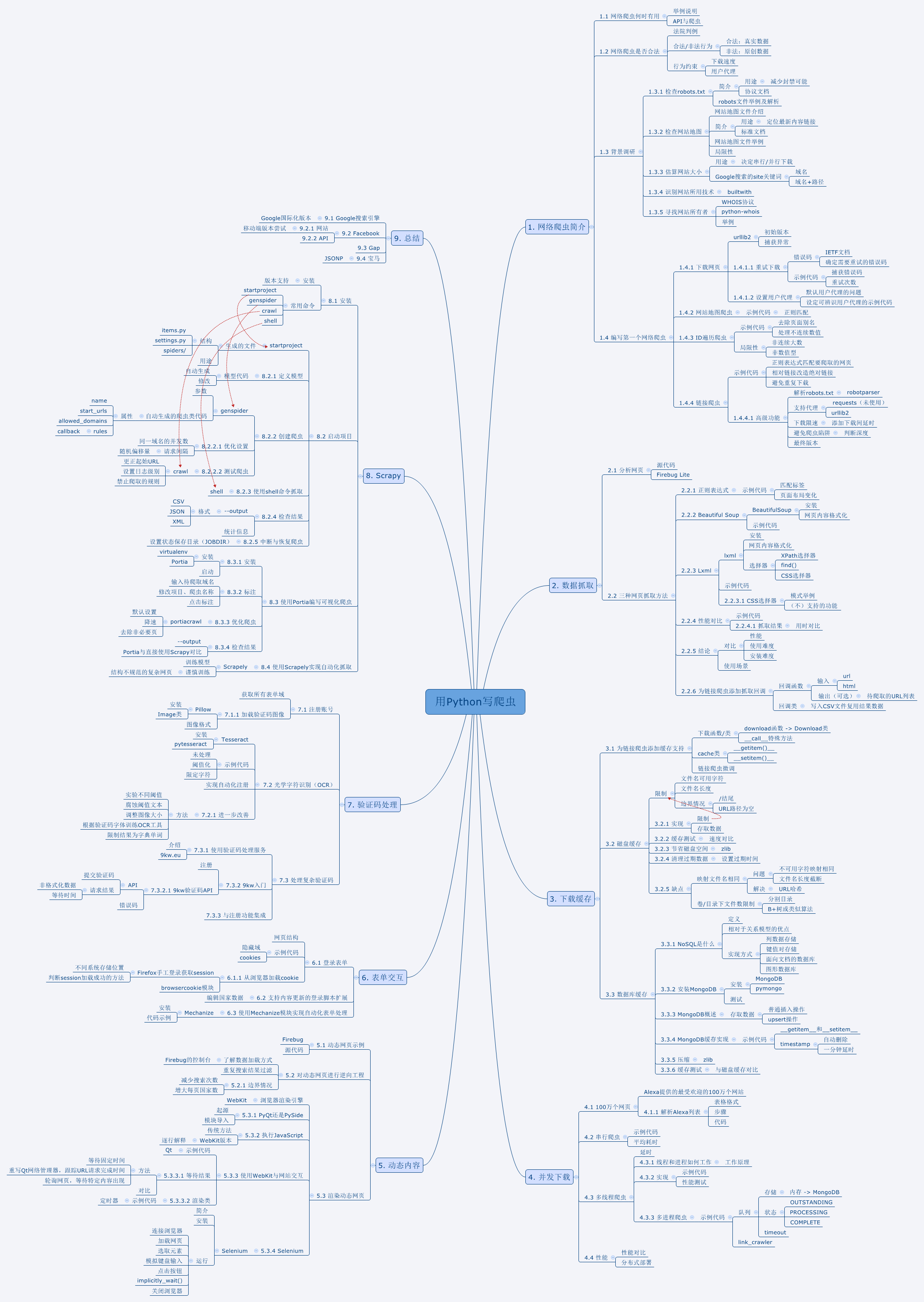
《用Python写网络爬虫》思维导图
思维导图(xmind):《用Python写网络爬虫》思维导图(xmind)