Elasticsearch 高基数聚合
作者:生哥
一、需求

二、分析
cardinality 是聚合的一种,可以理解成先在内存里创建出若干个桶,然后把每个桶贴上标签,把数据根据规则放入到桶中,最后对桶中数据进行二次计算归类,不管size设置多少,内存中桶的数量是一致的,为字段全部唯一值列表,这样就衍生出一个问题,是否字段唯一基数值越少,查询性能越快,反之越慢。
-
-
- 高基数:字段唯一值较多,比如用户IP、用户ID等。
- 低基数:字段的唯一值较少,比如性别、国家、省份、httpCode等。
-
那高低基数的界线是多少呢?其实这个没有具体值,可以需要根据实际情况来定。
高基数的唯一值聚合造成的数据不准确性就真的无解了吗?特别是业务有一些根据用户ID、请求ID、用户IP等唯一值的查询需求,这些的唯一基数都很大,甚至一些能上亿。
-
- Elasticsearch使用的是HyperLogLog 算法,是一种用于近似计数的算法,它可以在大数据集上进行高效的去重和计数操作,该算法基于概率统计理论,通过使用哈希函数将输入数据映射到一个固定大小的位数组中,并利用这些位来估计不同元素的数量。具体来说,HyperLogLog算法将每个输入元素哈希为一个二进制字符串,并根据这个字符串的前缀零位数(即从左往右数第一个非零位之前的零位数)来确定该元素所属的桶,然后,对于每个桶,算法维护一个最大前缀零位数以及一个位图,用于记录是否存在某个元素的哈希值与当前桶的最大前缀零位数相等,最终HyperLogLog算法将所有桶的最大前缀零位数的调和平均值作为估计值,用于近似计算输入元素的不同数量。
- 该算法的时间复杂度为O(n),空间复杂度为O(log log n)。在Elasticsearch中,HyperLogLog算法被广泛应用于聚合查询中,例如计算唯一访问者、IP地址或用户标识符的数量。它可以帮助提高查询性能和减少内存占用,特别是在处理大型数据集时。简单理解就是 HyperLogLog 是先将字段内容哈希成Long,然后通过msearch获取映射表。如果想详细了解算法可以查看附录。
既然ES内部的聚合是基于HASH来计算的,我是否可以提前对字段内容进行hash,用空间换时间。
-
- MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。由 Austin Appleby 在 2008年发明, 并出现了多个变种,都已经发布到了公有领域(public domain)。与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash的随机分布特征表现更良好。Redis 在实现字典时用到了两种不同的哈希算法,MurmurHash 便是其中一种(另一种是djb),在 Redis 中应用十分广泛,包括数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。发明算法的作者被邀到 google 工作,该算法最新版本是 MurmurHash3 , 基于MurmurHash2改进了一些小瑕疵,使得速度更快,实现了 32 位(低延时)、128 位 HashKey,尤其对大块的数据,具有较高的平衡性与低碰撞率。
- 在所有的ES节点上安装 mapper-murmur3 插件
bin/elasticsearch-plugin install mapper-murmur3
- 插件安装完毕后必须重启ES所有的节点。
- 插件安装完成后,需修改索引的 mapping,给uuid等字段添加字段类型murmur3
PUT /index_name/_mapping/_doc?include_type_name=true
{
"properties": {
"uuid": {
"type": "keyword",
"fields": {
"hash": {
"type": "murmur3"
}
}
},
"udid": {
"type": "keyword",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
}
- 给新字段添加数据,默认索引新加的字段是没有数据的。(只处理udid存在的记录进行数据刷新)
POST /index_name/_update_by_query
{
"script": {
"lang": "painless",
"inline": "ctx._source.udid = ctx._source.udid ;
ctx._source.uuid = ctx._source.uuid"
},
"query": {
"exists": {
"field": "udid"
}
}
}
-
如果之前索引为了节约存储空间,关闭了_source。上面的刷新功能无法使用。等于只有新导入的数据才有会新的索引类型。
-
三、验证
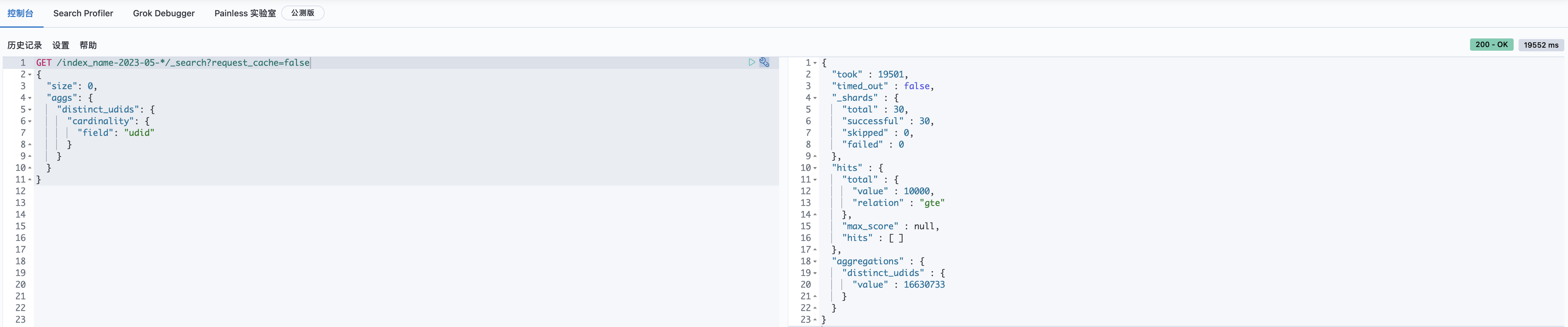
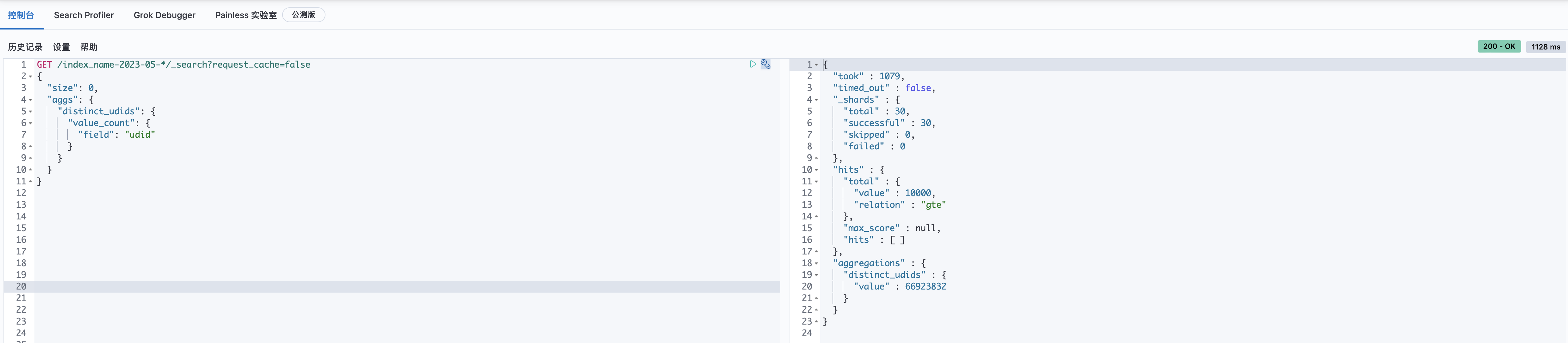
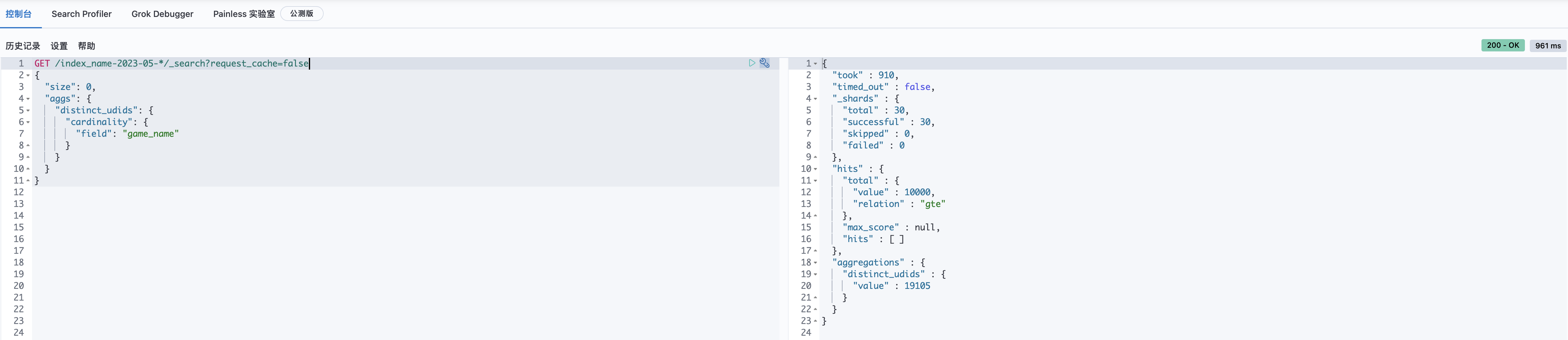
前面的步骤都完成了,让我们检验下效果。惊讶的发现,DSL完成时间从之前的31秒,降低到了5秒。 field:udid, 查询花费19s+, 唯一值个数:16,630,733 (约1663w+) field:game_name, 查询花费0.9s+,唯一值总计数1.9w+ field:udid.hash, 查询花费0.7s+,唯一值总计数16,592,421 (约1659w+) 
效果堪称完美,但需要注意的是,因为murmur3 记录的数值是hash后的,会导致无法用于前端显示,仅用于聚合加速的一个中间值。
但你一定也会发现一个问题,为什么使用udid字段查唯一值个数是1663万多,但udid.hash却是1659万多。是hash有问题还是cardinality聚合函数有问题,导致两种有差距。其实是因为cardinality聚合,使用 HyperLogLog(HLL)算法进行估算,为了取得更准确的精度,可以通过设置 “precision_threshold” : 3000,值越大越精确。值越大所需要的内存越多,内存消耗约为precision_threshold值*8字节。
下面我们取单个索引单个shard,进行精度测试 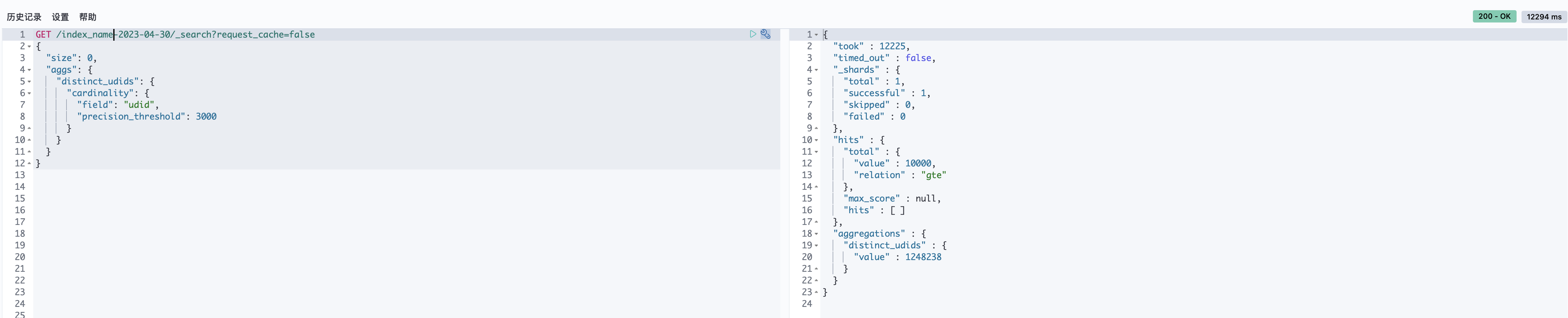
- DSL说明:
- 字段分别为udid和udid.hash
- precision_threshold 分别测试为 0、100、1000、3000、10000、40000,0是默认最小值,40000是最大值,3000为默认值(如果无此参数,默认就是3000)
- 测试结果(udid真实唯一值为330593):
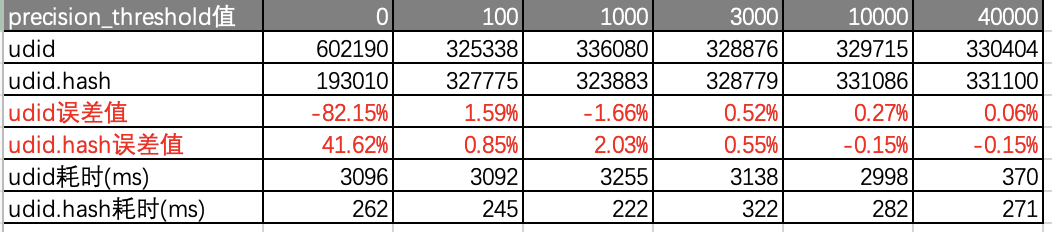
- 测试结果说明:
- 误差值为(真实唯一值个数-估算的唯一值个数)/ 真实唯一值个数
- 当precision_threshold的内存大于聚合时桶的内存消耗时,聚合耗时和hash无异。
- 当误差值为负数时,表示估算出的值比真实值大,简单点说就是估算估多了。
-
单索引的误差默认可控在0.5%左右,最小误差可控在0.06-0.15%。
下面我们加大udid的数据量,取两个索引进行精度测试 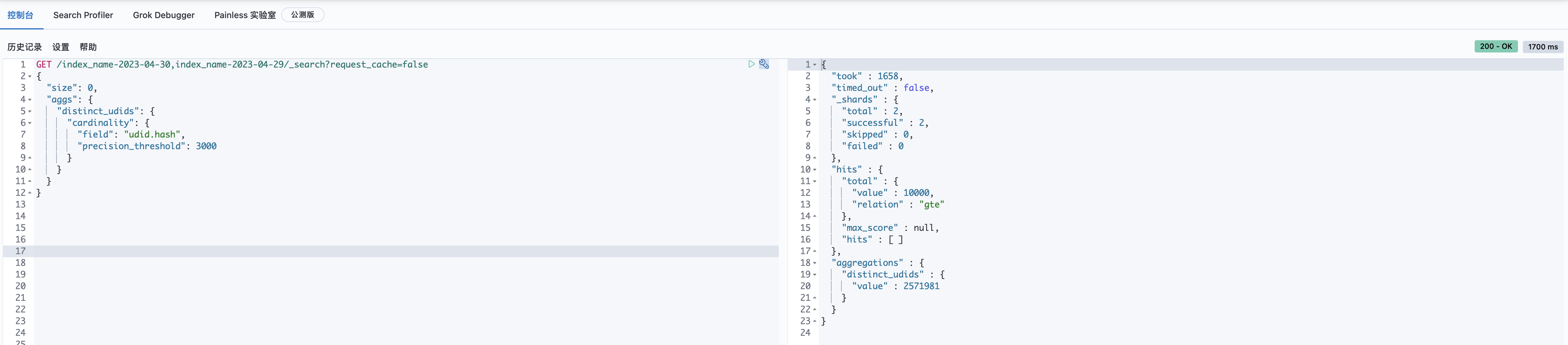
- 测试结果(udid真实唯一值为2577085):
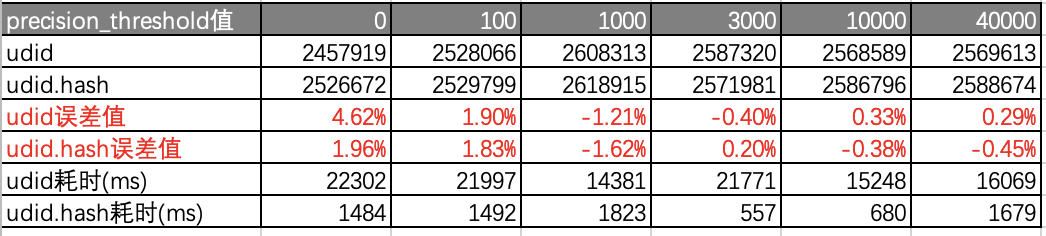
- 测试结果说明:
- 当唯一值量达到250万+时,precision_threshold设置到最大,udid的耗时远比udid.hash大。因为内存已不能支持这么大的唯一值计算,需要频繁的通过内存交换来计算数值。
-
从误差率看两者几乎相近,误差不超0.1%。如果用0.1%的误差去换15-16倍的时间优化觉得还是值得的。
四、拓展
之前也考虑过使用 eager_global_ordinals: true ,全局基数来优化上面问题,但实际测试时发现,只有使用基于 keyword,ip 等字段的分桶聚合,包含:terms聚合、composite 聚合等,才会有明显加速。使用 cardinality 情况下几乎没有效果。因为 eager_global_ordinals 简单的理解就是把字段事先标记好全局编号,从而提高在聚合时的编号作业,用空间换时间,但 cardinality 是计算编号个数,如果编号很多有几千万几亿个,事先做好的编号等于无效,只不过是把数据重新编辑了一次而已,还是需要进行hash作业。
拆分聚合和多进程并发查询,对此场景也是无效的。因为取一个月的用户唯一值和把每天的用户唯一值取出后再求和,两者不等同,所以并发优化方案也无效。
- DSL说明:
-
五、附录
https://blog.csdn.net/laoyang360/article/details/111940010
https://www.elastic.co/cn/blog/improving-the-performance-of-high-cardinality-terms-aggregations-in-elasticsearch
https://zhuanlan.zhihu.com/p/77289303