AWS发布分布式版本Aurora Limitless
在今天凌晨的AWS re:Invent上,Aurora发布了最新的功能“Aurora Limitless”。这是一个基于水平拆分的分布式数据库,算是最近几年来说Aurora发布另一个非常大的功能点。

Aurora Limitless主要是解决两个问题:一个是写扩展,另一个是容量扩展。这也是国内的分布式数据库(诸如PolarDB-X、TDSQL、OceanBase、TiDB等)所解决的最主要的问题,海外也有诸如YugabyteDB、CockroachDB等产品。现在Aurora也加入了这个战场。
产品架构图
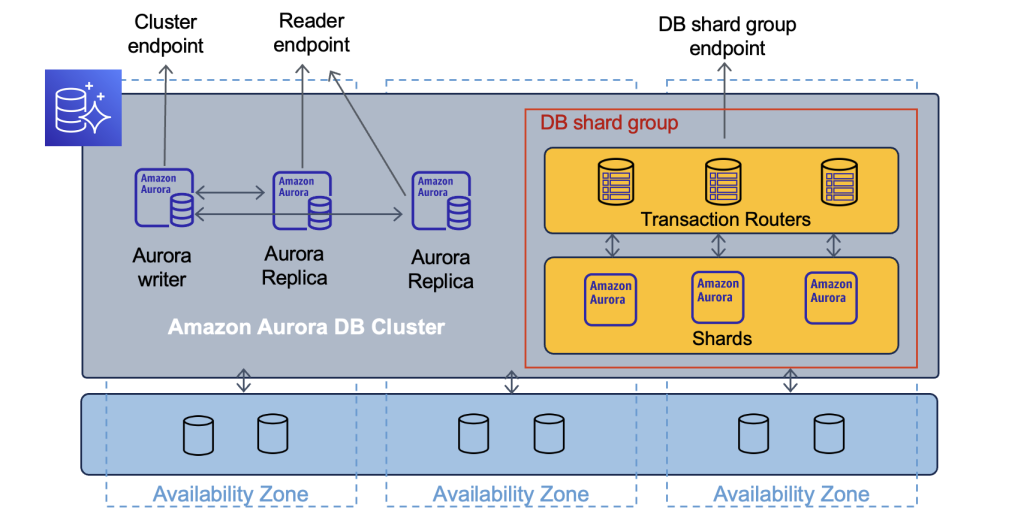
鉴于底层使用的Aurora实例,其架构与PolarDB-X是很类似的。这个版本的Aurora Limitless是基于PostgreSQL的,底层的每个Shard都是一个独立的Aurora PostgreSQL实例,上层有多个Transaction Routers节点用于处理分布式Query。另外,在Aurora Limitless中的表也与一般的分布式数据库类似,分为两类表,一个是shard表,另一个是广播表(Reference tables),Shard表会进行水平的拆分,数据独立的拆分到多个不同的节点上。广播表则会全量复制到不同的shard上,以方便进行更加高性能的JOIN操作。
从架构图来看,上层使用了一个Routers节点做分布式处理,底层是一个Aurora计算节点和存储节点,如果有印象的话,这与21年阿里云发布的PolarDB-X 2.0的”Share Nothing、Share Storage、Share Everything”的理念是非常类似的。
目前,该功能还出于预览阶段,普通用户暂时还无法使用,根据以前Aurora产品的节奏,从预览到正式发布,可能还需要一年左右的时间。
参考: