RSS-GPT Configuration
Introduction
Prerequisites
- GitHub account
- OpenAI API Key (get it at OpenAI website)
1. GitHub Actions deployment
The main idea is to use GitHub Actions to run Python scripts periodically, the script calls OpenAI API to generate summaries and append them to original RSS entries, then generate a new xml file, and commit it to the repo.
All contents in the repo folder are deployed on GitHub Pages, so you can access the xml file via your GitHub Pages URL, and subscribe to it like normal RSS feeds in any RSS reader.
If you don't want to deploy on GitHub Pages, you can also subscribe to the raw xml file in the repo (URL starts with https://raw.githubusercontent.com), e.g. the xml file URL of this repo is https://raw.githubusercontent.com/yinan-c/RSS-GPT/main/docs/brett-terpstra.xml.
1.1 Fork the project
Go to the project RSS-GPT and fork it to your own repo. I recommend not to change the repo name, if you do so, you'll have to modify main.py in step 3.
1.2 Three Repo Secrets
U_NAME
The username used for git commit, please set to your GitHub username.
U_EMAIL
The email used for git commit, it's the email you used to register GitHub, can be found in GitHub Settings page.
WORK_TOKEN
Since the project involves using scripts to operate repo contents, permissions are needed for the script to modify files in the repo. Apply for a new personal access token (classic) in GitHub settings page and configure the new token as follows:
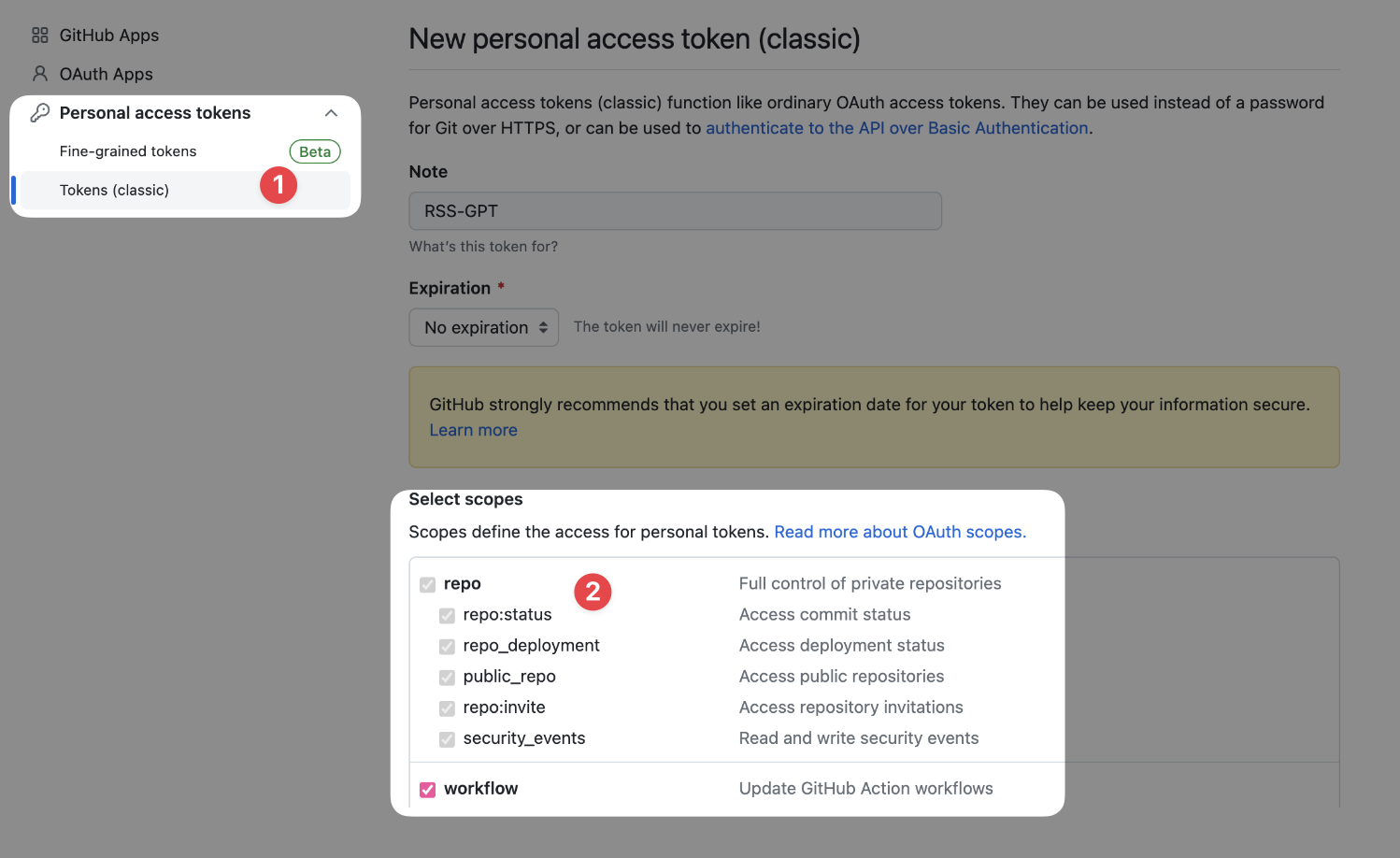
- Note: RSS-GPT or any name you like
- Select scopes: Check all options under "repo" and "workflow"
- Expiration: Choose "No expiration"
- Click "Generate token" at bottom.
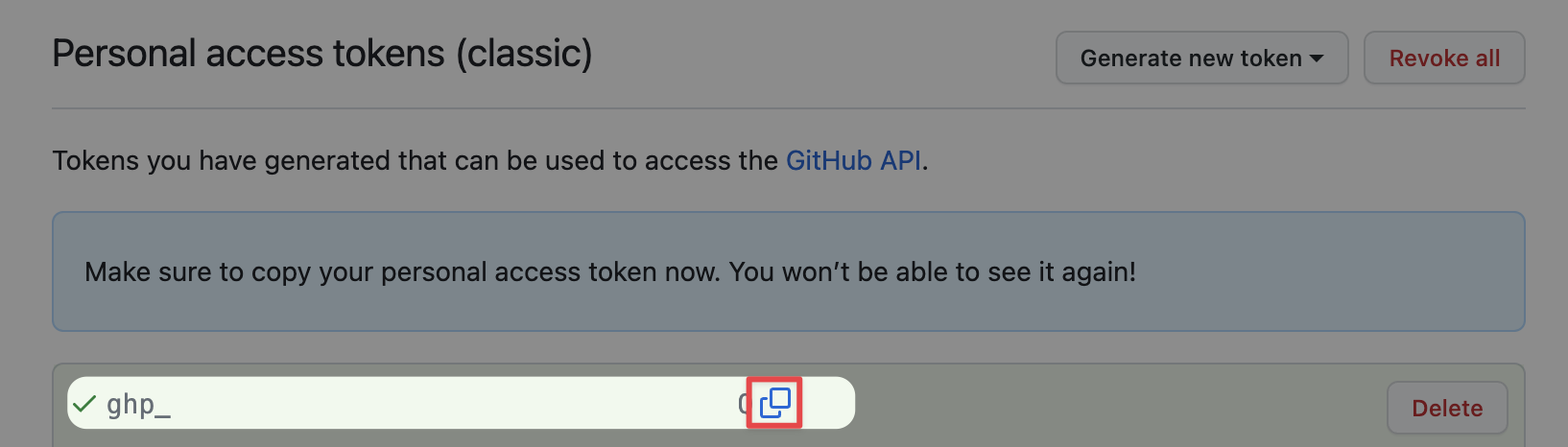
Copy the token after clicking, make sure to copy it on this page, you won't be able to see the token after leaving this page. If you miss it, you'll have to generate a new one following the steps above.
1.3 Set Repository Secrets
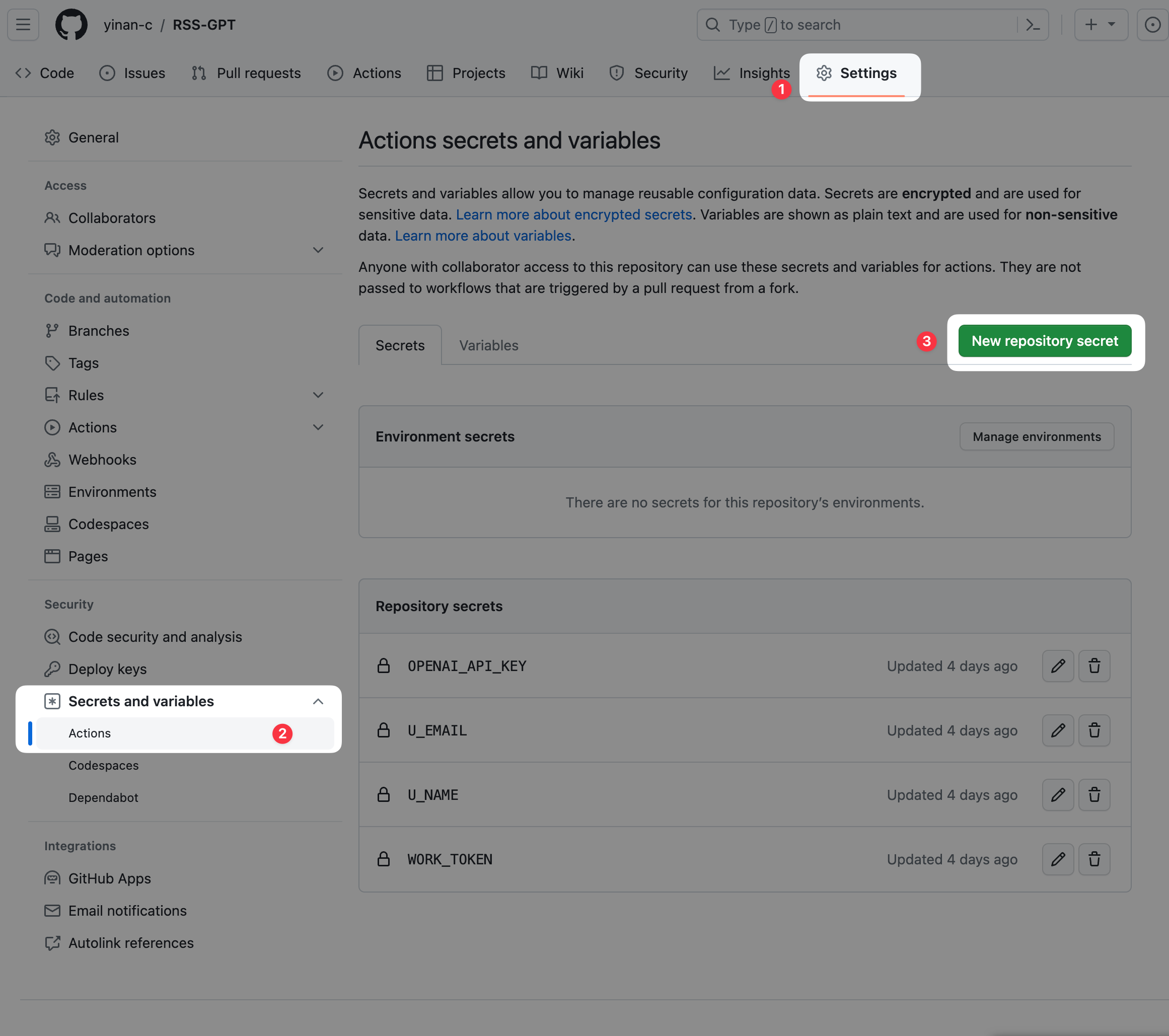
Go to your forked repo, click "Settings" in top menu bar, then click "Secrets and variables" in left sidebar, choose "Actions", then click "New repository secret" at top right.
-
Add
U_NAME,U_EMAIL,WORK_TOKEN,OPENAI_API_KEYas secrets to the repo, can only add one at a time: -
Name: U_NAME, U_EMAIL, WORK_TOKEN, OPENAI_API_KEY
- Value: Your username, email, the copied GitHub token and OpenAI API Key
- Click "Add secret"
1.4 Grant required permissions
Enable GitHub Actions access to Pages:
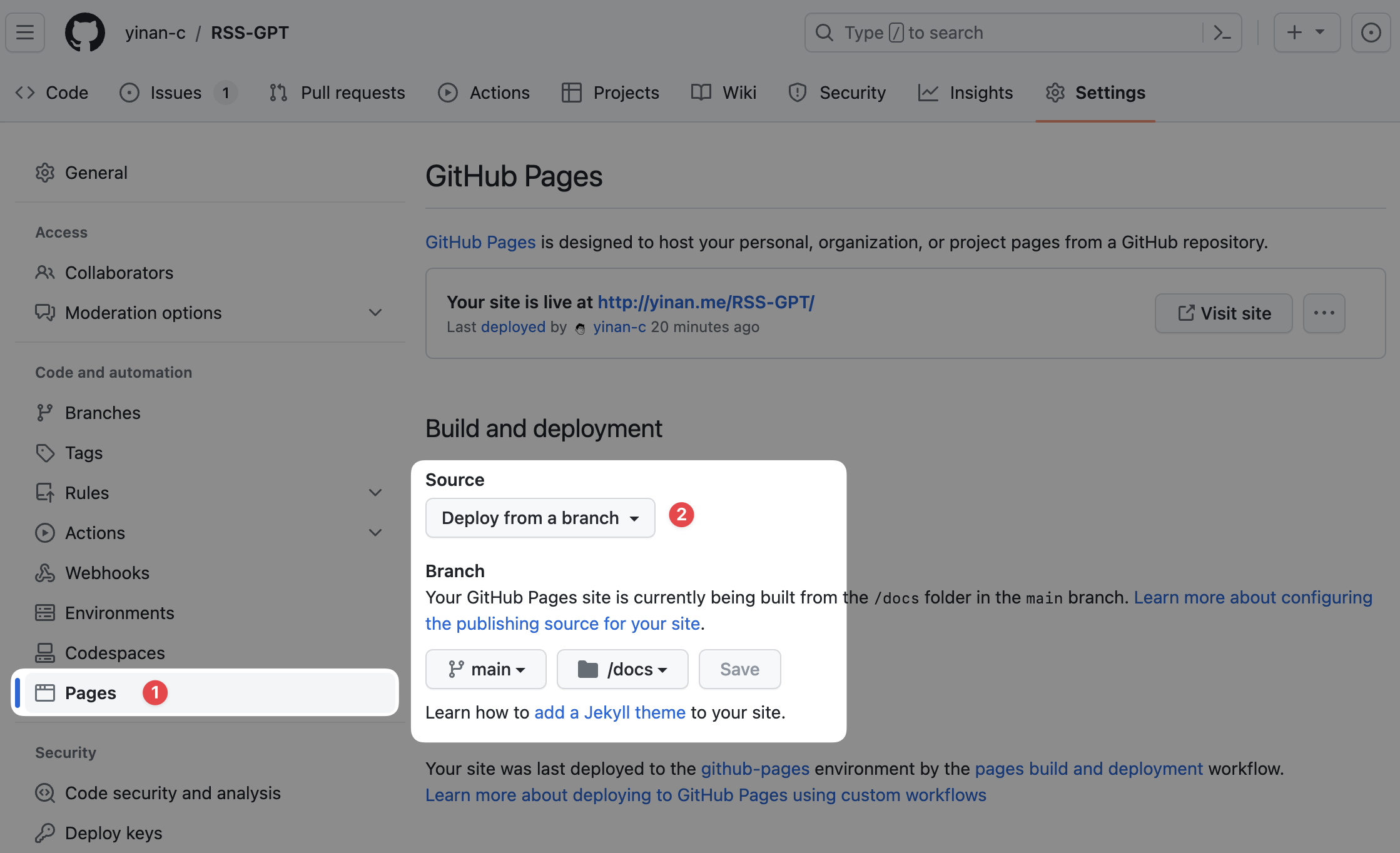
- Click "Settings" in top menu bar
- Find "Pages" under "Code and automation" in left sidebar and click in
- Set source as deploy from main branch /docs folder.
2. Configure RSS sources to merge, filter and summarize
Go to the project, open the "config.ini" file, click the pencil icon at top right to edit code and configure your desired sources. Don't change the first two lines.
[cfg]
base = "docs/"
Then modify the target language, number of keywords, and summary length in the next 3 lines. The following code is feed-specific configs, format is:
[source001]: Feed ID, starts from 001 and increments, make sure IDs are unique to avoid errors.name = "brett-terpstra": Name of the generated feed, only letters (a-z A-Z), numbers (0-9), (-,_,.,~) allowed.url = "https://brett.trpstra.net/brettterpstra": Original RSS feed URL, can contain multiple feeds separated by comma.max_items = "10": Number of articles to summarize between refreshes. E.g. 10 means summarizing the latest 10 articles on each refresh. If set to 0 or not set, no articles will be summarized and original entries will be returned.
Next are optional filter configs, note all three configs must be set or not set at the same time, error will occur if only one or two of them are set:
filter_apply = "title": Apply filter on "title", "article" (content) or "link".filter_type = "exclude": Filter type: "include", "exclude", "regex match" or "regex not match".filter_rule = "TextExpander": Filter text or regex.
Click "Commit changes" at bottom to submit edits.
3 Modify main.py
(if you used default repo name in 1.1 and you don't want to modify prompt, you can skip this step)
- Open "main.py" file, click the pencil icon to edit code, go to line 290 and modify the "RSS-GPT" in "https://{U_NAME}.github.io/RSS-GPT" to your repo name.
- (Optional) Modify prompt at lines 113-129 based on your needs for better summaries.
- Click "Commit changes" at bottom to submit edits.
4. Configure and test GitHub Actions
Go to the project, click "Actions" in top menu bar, click "cron_job" and choose "Run workflow".
Green check mark means successful run, red x means failure, usually due to errors in edited ini file or incorrect permissions/tokens. Double check if errors occur.
If there are no errors, you should see your feeds on the project README page.
On the left of -> is original URL, right is converted URL to subscribe like any other RSS feeds.
Some extra notes
About feeds refresh frequency
- Default run frequency is every 2 hours, modify
.github/workflows/cron_job.ymlline 7 to change, e.g.
- cron: '0 */2 * * *' # run every 2 hours
- cron: '0 */1 * * *' # run every 1 hours
- cron: '0 0 * * *' # run every day at 00:00
- cron: '*/30 * * * *' # run every 30 minutes
For more info on cron syntax, see crontab docs or GitHub docs.
What if I don't want to use summarization feature?
-
Well, you can still use this script to filter and merge multiple subscription sources. You just need to not set the OpenAI API Key in 1.3, or not set the
max_itemsinconfig.ini, or set it to 0. By default, this script can also return the original article entries when the AI call fails. -
If you do want the AI summarization feature and have correctly set
config.ini, but still receive the original entries without summarization or experience infrequent updates, you can check the error information of the OpenAI API or feedparser from thefeed_name.logfile in thedocs/subdirectory of the repo.
About AI summary content
-
My prompt is basically asking AI to extract keywords + summarize + auto-formatting. Formatting is not always perfect, and my prompt is not perfectly optmized for everyone. You can modify prompt at lines 113-129 based on your needs.
-
AI summaries are based on the description of each article in the feed. If the RSS itself provides the full text article, the full text will be summarized; if the RSS only provides the article summary, the summary will be based on the summary, and the script does not currently provide the function of crawling the full text of the original article.
About the usage of OpenAI API
-
Regarding the usage of the OpenAI API, in order to minimize costs as much as possible, the following default measures have been adopted for this project:
-
All unrelevent content (images, frames, HTML tags etc.) are removed before sending to OpenAI API, in order to reduce the token length and cost.
-
If the text length exceeds 16k,
gpt-4-1106-previewwill be used, otherwiseGPT-3.5 Turbois used by default. If you want to use a different model, you can modify the model parameter passed to thegpt_summaryfunction of lines 227-243 of main.py, e.g.model="your_model". Please refer to the OpenAI API Pricing for different prices of different OpenAI models. -
The script will read the xml files already existing in the docs/ folder. Existing articles will not be summarized again, so OpenAI API will not be repeatedly consumed.
About repo updates
-
I have separated manual edits and workflow auto commits into different branches, so you can see when and what I have edited in the
devbranch to decide whether to pull the latest changes. -
If OpenAI releases more models in the future, I will choose the most suitable default model and update the code accordingly. If you have a better way to use AI or encounter any issues or spotted any errors, feel free to email me.