基于PVE Ceph集群搭建(二):Ceph存储池搭建与基本性能测试
MatthewLXJ发表于 2023-01-15 16:13:00
接前篇“基于PVE Ceph集群搭建(一):集群40GbEx2聚合测试”,搭建Ceph存储池以及性能基本的测试
Ceph集群搭建
集群包括七个节点,其中三个为纯存储节点,四个存储计算一体节点,均处于同一内网,根据“基于PVE Ceph集群搭建(一):集群40GbEx2聚合测试”中的测试节点间40GbEx2聚合后可实现50GbE互联。
软件部分
软件版本
proxmox-ve: 7.3-1 (running kernel: 5.15.74-1-pve)
ceph:17.2.5-pve1 quincy (stable)
iperf:2.0.14a (2 October 2020) pthreads
fio:3.25节点配置
| Node name | Node IP | Motherboard | CPU | Memory | Network |
|---|---|---|---|---|---|
| node1 | 192.168.1.11 | H12SSL-i | EPYC 7502QS | Samsung 3200 32G 2R8 x8 | 40GbE x2 |
| node2 | 192.168.1.12 | X9DRi-F | E5-2670 x2 | Samsung 1600 16G 2R4 x8 | 40GbE x2 |
| node3 | 192.168.1.13 | Dell R730xd | E5-2666v3 x2 | Samsung 2133 16G 2R4 x6 | 40GbE x2 |
| node4 | 192.168.1.14 | Dell R720xd | E5-2630L x2 | Samsung 1600 16G 2R4 x4 | 40GbE x2 |
| node5 | 192.168.1.15 | Dell R720xd | E5-2696v2 x2 | Samsung 1600 16G 2R4 x4 | 40GbE x2 |
| node6 | 192.168.1.16 | Dell R730xd | E5-2680v3 x2 | Samsung 2133 16G 2R4 x4 | 40GbE x2 |
| node7 | 192.168.1.17 | Dell R730xd | E5-2680v3 x2 | Samsung 2133 16G 2R4 x4 | 40GbE x2 |
注:其中node2、node4、node5为存储节点,其他为存储计算一体节点。
OSD分布与配置
| Node name | HDD | NVME | OSD Setting |
|---|---|---|---|
| node1 | 10T x6 | PM9A1 512G x2 | HDD + 1% NVME DB/WAL |
| node2 | 6T x12 | PM983A 900G x1 | HDD + 1% NVME DB/WAL |
| node4 | 300G x2+ 3T x4+ 4T x3 | PM983A 900G x1 | HDD + 1% NVME DB/WAL |
| node6 | 6T x4 | PM983A 900G x1 | HDD + 1% NVME DB/WAL |
| node7 | 6T x4 | PM983A 900G x1 | HDD + 1% NVME DB/WAL |
注:node3与node5中磁盘被ZFS占用,相对于当前Ceph为五节点,后续ZFS数据迁移完成补上七节点测试数据。
Ceph共36个OSD
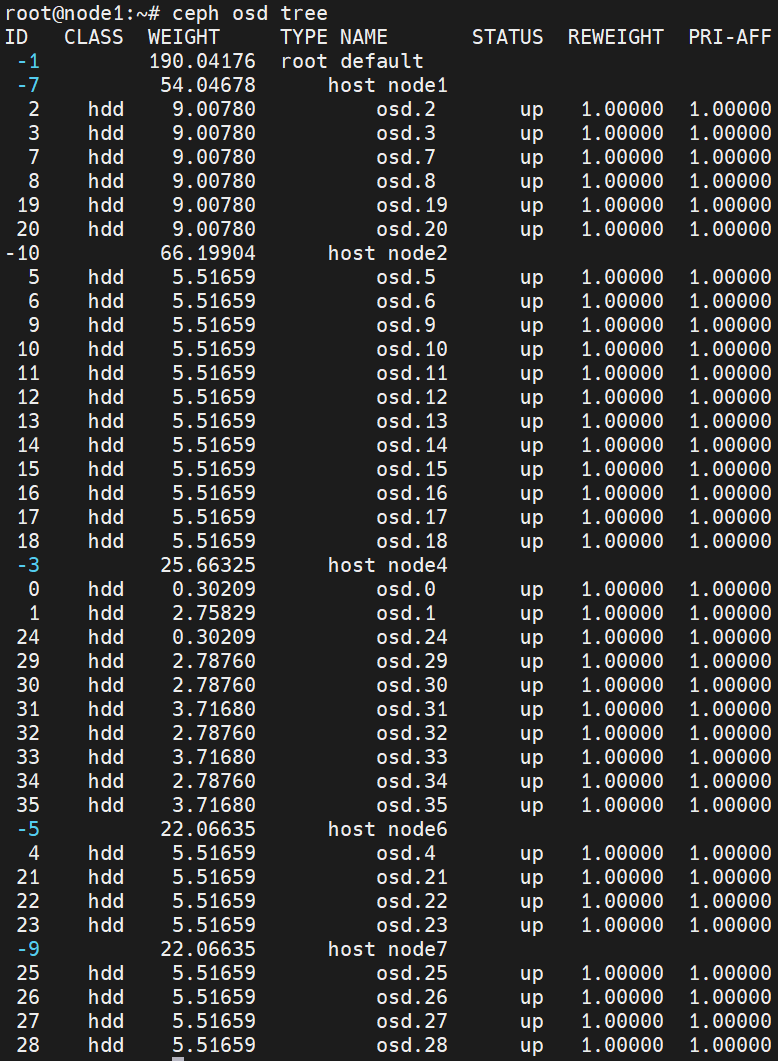
mon: node1、node3、node4、node6、node7
mgr: node1、node2、node3、node4、node5、node6、node7
mds: node1、node3、node5、node6、node7(node1 atcive)创建Ceph存储池
1.RBD
ceph osd pool create testbench 100 100 (创建测试池testbench)
ceph osd pool application enable testbench rbd (分配application)
rbd create testbench/disk1 --size 1024000
rbd map testbench/disk1
mkfs.xfs /dev/rbd0
mount /dev/rbd0 /mnt/rbd
/mnt/rbd用于fio对rbd进行测试2.Cephfs
ceph fs new cephfs cephfs_data cephfs.metadata
mount -t ceph :/ /mnt/pve/cephfs -o name=admin,secret=
/mnt/pve/cephfs用于fio对cephfs进行测试3.NFS
Ceph推荐使用NFS-ganesha来提供NFS服务,基于PVE集群搭建的ceph不能直接提供NFS配置,因此暂时未进行测试,后续补上。
Ceph性能测试
本次性能测试从以下几项展开:
- Ceph的rados bench测试write、read和seq;
- fio测试runtime、bs、iodepth、numjobs和iodepth*numjobs的影响;
- 针对Ceph,分别测试CephFS、RBD、NFS的性能;
1.Ceph的rados工具测试
rados bench -p testbench 30 write -b 4M -t 16 --no-cleanup | tee rados_write.log
rados bench -p testbench 30 rand -t 16 | tee rados_rand.log
rados bench -p testbench 30 seq -t 16 | tee rados_seq.log| Test | bandwidth(MB/sec) | IOPS | clat(ms) |
|---|---|---|---|
| write | 738.117 | 184 | 86 |
| rand | 998.687 | 249 | 64 |
| seq | 998.544 | 249 | 63 |
Ceph自带的rados工具针对4M进行测试。
2.fio测试
(I) rbd
- fio_rbd.conf
[global]
ioengine=libaio
direct=1
size=5g
lockmem=1G
runtime=30
group_reporting
directory=/mnt/rbd
numjobs=1
iodepth=1
[4k_randwrite]
stonewall
rw=randwrite
bs=4k
[4k_randread]
stonewall
rw=randread
bs=4k
[64k_write]
stonewall
rw=write
bs=64k
[64k_read]
stonewall
rw=read
bs=64k
[1M_write]
stonewall
rw=write
bs=1M
[1M_read]
stonewall
rw=read
bs=1M- fio_rbd.sh
for iodepth in 1 2 4 8 16 32; do
sed -i "/^iodepth/c iodepth=${iodepth}" fio_rbd.conf && fio fio_rbd.conf | tee rbd_i$(printf "%02d" ${iodepth}).log && sleep 20s
done(II) cephfs
- fio_cephfs.conf
[global]
ioengine=libaio
direct=1
size=5g
lockmem=1G
runtime=30
group_reporting
directory=/mnt/pve/cephfs
numjobs=1
iodepth=1
[4k_randwrite]
stonewall
rw=randwrite
bs=4k
[4k_randread]
stonewall
rw=randread
bs=4k
[64k_write]
stonewall
rw=write
bs=64k
[64k_read]
stonewall
rw=read
bs=64k
[1M_write]
stonewall
rw=write
bs=1M
[1M_read]
stonewall
rw=read
bs=1M- fio_cephfs.sh
for iodepth in 1 2 4 8 16 32; do
sed -i "/^iodepth/c iodepth=${iodepth}" fio_cephfs.conf && fio fio_cephfs.conf | tee cephfs_i$(printf "%02d" ${iodepth}).log && sleep 20s
done测试结果
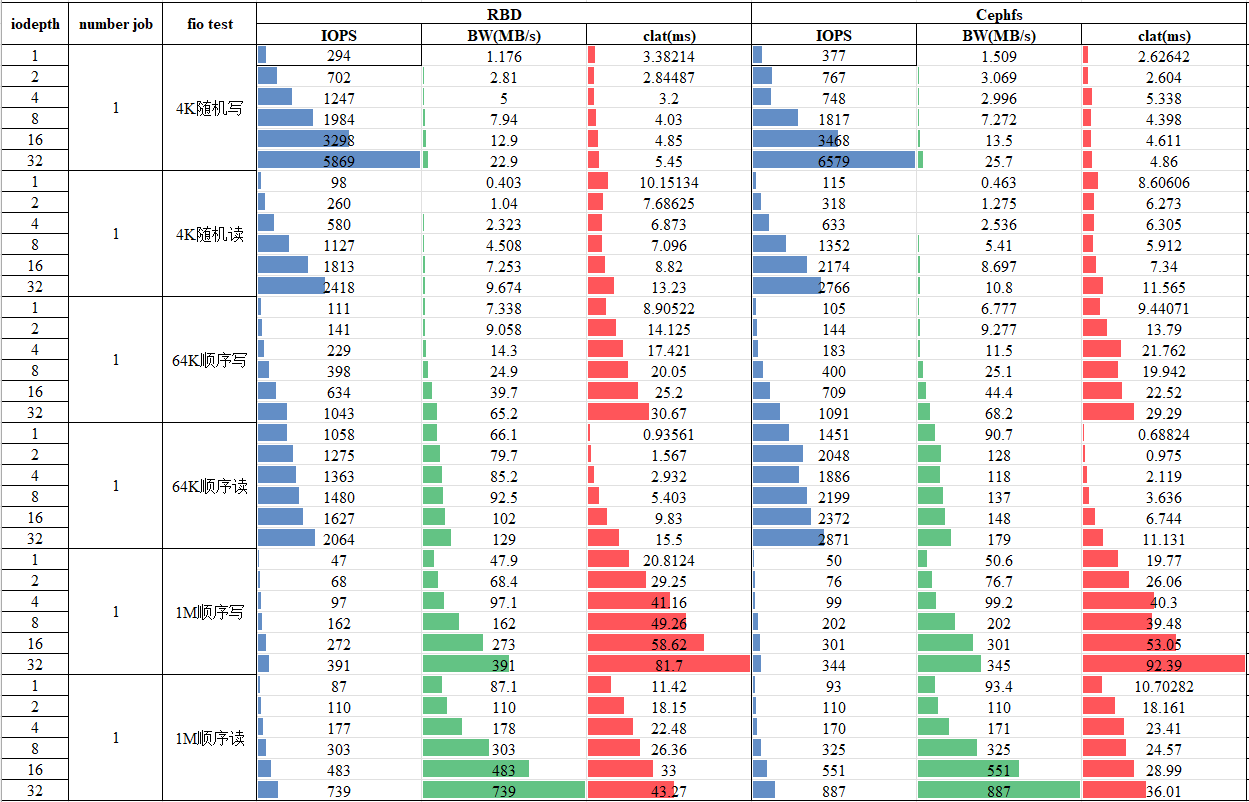
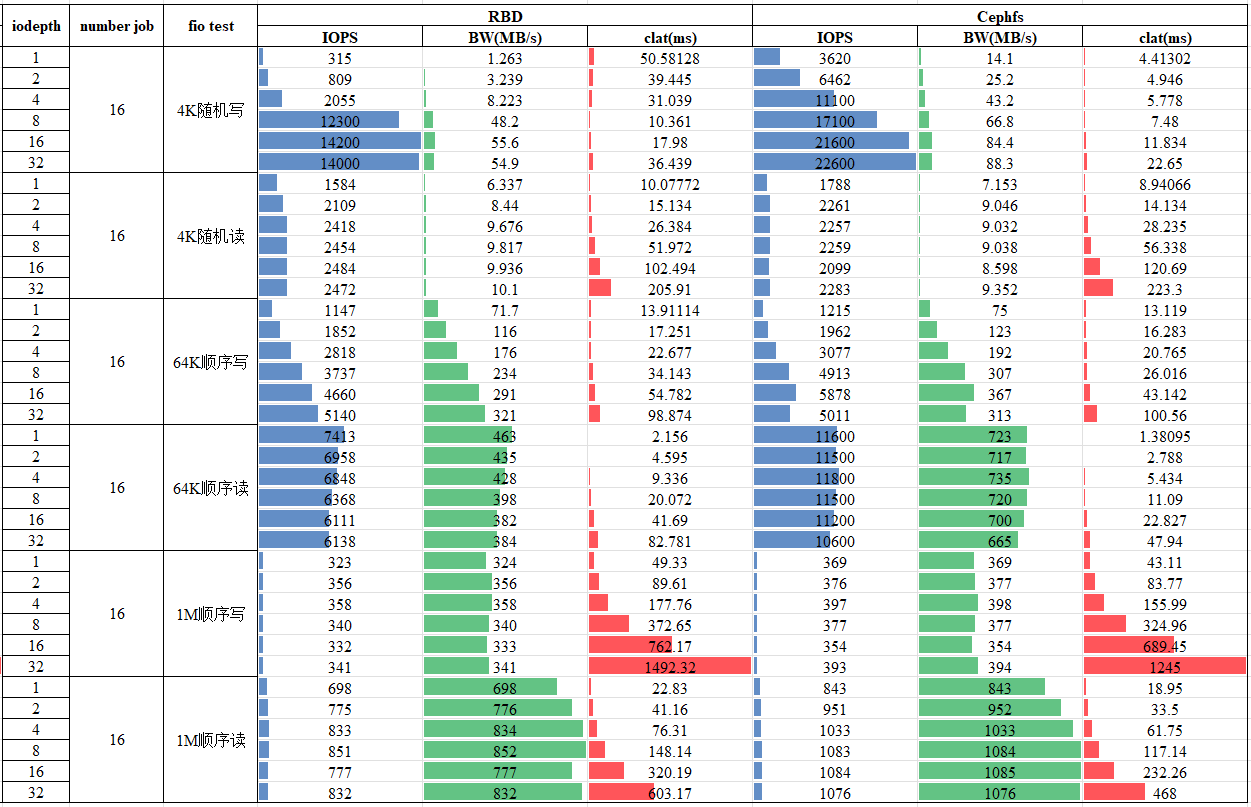
测试结论
- RBD、Cephfs总体性能是随iodepth、线程数(number job)提升的。
- 延迟(clat)随着number job与iodepth的乘积的增加而增加的,相对来说,number job对延迟的影响更大,更多的并行IO任务会显著提高IO延迟。
- Cephfs相对RBD来说4K随机写性能有显著提升。
参数配置建议
针对我当前Ceph的配置,36 OSD + 1% NVME共200T存储空间的情况下,结合测试结果,为了得到更好的性能,参数设置:
- 4K随机读写: iodepth设置为16或32及以上,并采用Cephfs的方式来存储;
- 1M顺序读写:iodepth设置为1,多线程能够尽可能发挥读写极限。
3. Cache Tier测试
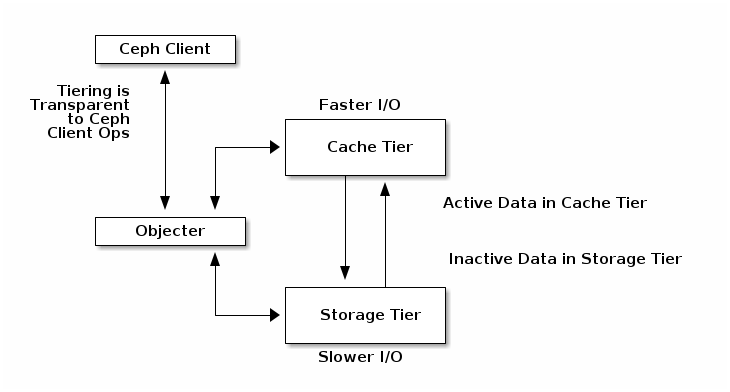
Ceph官方文档对Cache Tier的解释:Cache Tier为Ceph客户端提供了更好的I/O性能,用于存储在支持存储层的数据子集。缓存分层包括创建一个相对快速的存储设备池(例如,固态驱动器)配置为缓存层,以及一个由擦除编码或相对较慢/便宜的设备组成的备份池,配置为经济的存储层。Ceph objecter处理放置对象的位置,分层代理决定何时将对象从缓存中冲到备份存储层。所以缓存层和后备存储层对Ceph客户端是完全透明的。
Ceph官方文档提到,值得注意的是:
- 缓存分层将降低大多数工作负载的性能。用户在使用这个功能之前应该非常谨慎。
取决于工作负载。缓存是否能提高性能在很大程度上取决于工作负载。因为将对象移入或移出缓存是有成本的,所以只有当数据集的访问模式有很大的偏差,比如大部分的请求只触及少量的对象时,它才会有效。缓存池应该足够大,以便为你的工作负载捕获工作集,从而避免惊扰。 - 难以进行基准测试。大多数用户用来衡量性能的基准测试都会显示出高速缓存分层的糟糕性能,部分原因是其中很少有请求偏向于一小部分对象,高速缓存需要很长的时间来 "预热",而且预热成本也很高。
- 通常情况下,速度较慢。对于不适合缓存分层的工作负载,性能通常比没有启用缓存分层的普通RADOS池要慢。
- librados对象枚举。librados级别的对象枚举API并不意味着在存在的情况下是连贯的。如果你的应用程序直接使用librados并依赖于对象枚举,缓存分层可能不会像预期的那样工作。(这对RGW、RBD或CephFS来说不是一个问题)。
- 复杂性。启用缓存分层意味着在RADOS集群中使用了很多额外的机器和复杂性。这增加了你在系统中遇到其他用户尚未遇到的错误的概率,并将你的部署置于更高的风险水平。
由于NVME基本被OSD的DB/WAL设备占用,后续继续增加SSD/NVME设备后对Cache Tier进行测试。
后续性能优化方向
- 当前测试系统下OSD节点与mon、mgr、mds均重叠,可能会影响性能,后续分离优化;
- 部分节点NVME盘体积与数量均太少,后续增加NVME,按照10% NVME配置DB/WAL将带来较大性能提升,同时一块NVME不能给过多OSD缓存;
- 当前测试下OSD临时数量为36,最终集群Ceph总OSD数量为87,裸机HDD总容量624T,NVME总数量20,裸机NVME容量63T。
下一篇将会更新“基于PVE CEPH集群搭建(三):Cephfs、RBD、NFS存储池性能调优”