复杂 C++ 项目堆栈保留以及 eBPF 性能分析
在构建和维护复杂的 C++ 项目时,性能优化和内存管理是至关重要的。当我们面对性能瓶颈或内存泄露时,可以使用eBPF(Extended Berkeley Packet Filter)和 BCC(BPF Compiler Collection)工具来分析。如我们在Redis Issue 分析:流数据读写导致的“死锁”问题(1)文中看到的一样,我们用 BCC 的 profile 工具分析 Redis 的 CPU 占用,画了 CPU 火焰图,然后就能比较容易找到耗时占比大的函数以及其调用链。

这里使用 profile 分析的一个大前提就是,服务的二进制文件要保留函数的堆栈信息。堆栈信息是程序执行过程中函数调用和局部变量的记录,当程序执行到某一点时,通过查看堆栈信息,我们可以知道哪些函数被调用,以及它们是如何相互关联的。这对于调试和优化代码至关重要,特别是在处理性能问题和内存泄露时。
但是在实际的项目中,我们用 eBPF 来分析服务的性能瓶颈或者内存泄露的时候,往往会拿不到函数调用堆栈,遇到各种 unknown 的函数调用链。这是因为生产环境为了减少二进制文件的大小,通常不包含调试信息。此外,就算生产环境编译 C++ 代码的时候用了 -g 生成了调试信息,也可能拿不到完整的函数调用堆栈。这里面的原因比较复杂,本文将展开聊一下这个问题。
程序的堆栈信息
在计算机科学中,堆栈(Stack)是一种基本的数据结构,它遵循后进先出(LIFO)的原则。这意味着最后一个被添加到堆栈的元素是第一个被移除的。堆栈在程序设计中有很多用途,其中最常见的是在函数调用和局部变量存储中的应用。
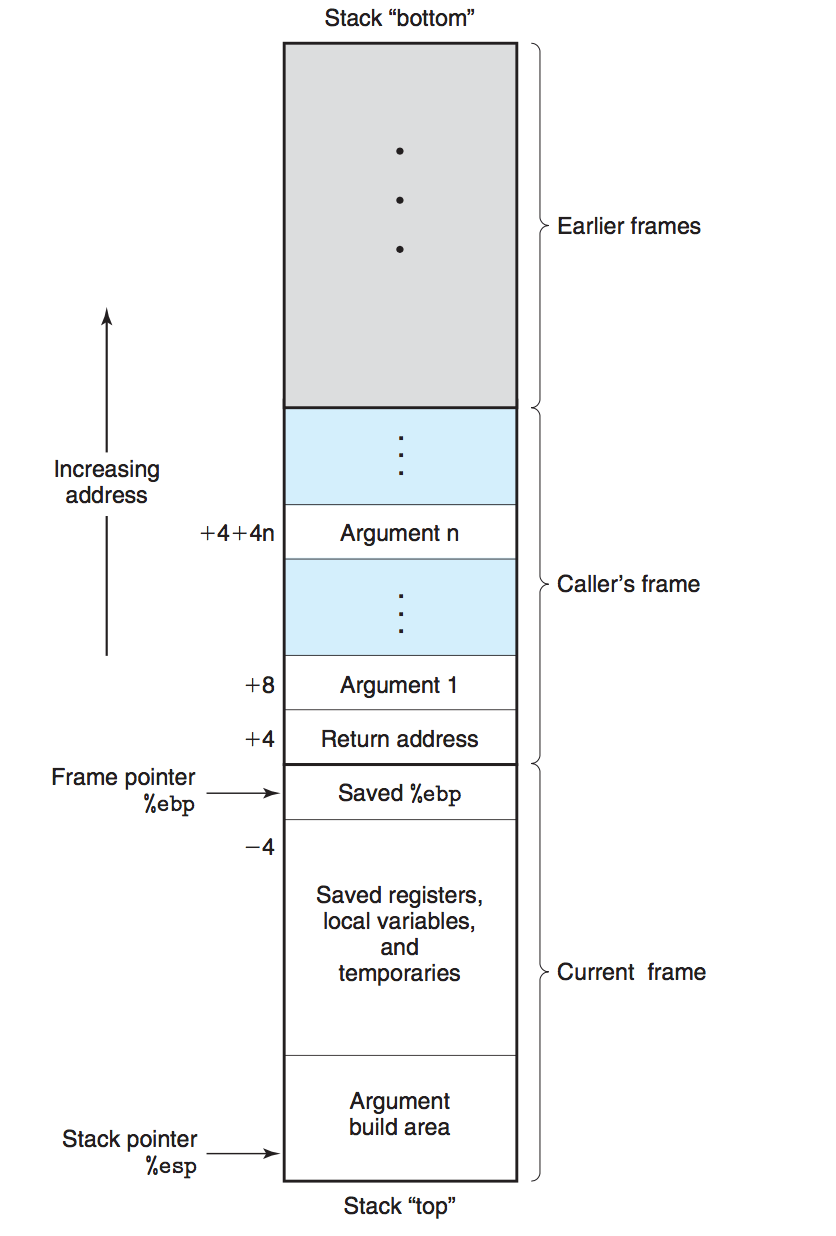
在程序执行过程中,堆栈被用于管理函数调用,这称为“调用堆栈”或“执行堆栈”。当一个函数被调用时,一个新的堆栈帧被创建并压入调用堆栈。这个堆栈帧包含:
- 返回地址:函数执行完成后,程序应该继续执行的内存地址。
- 函数参数:传递给函数的参数。
- 局部变量:在函数内部定义的变量。
- 帧指针:指向前一个堆栈帧的指针,以便在当前函数返回时恢复前一个堆栈帧的上下文。
当函数执行完成时,其堆栈帧被弹出,控制返回到保存的返回地址。堆栈在内存中的分布如下图:
DWARF 格式的堆栈信息
函数调用堆栈的信息在二进制文件中以 DWARF 格式保存。DWARF 是一种用于表示程序的调试信息的标准格式,广泛应用于Unix和Linux系统。它是一种非常灵活和可扩展的格式,能够表示丰富的调试信息,包括但不限于源代码行号、变量名、数据类型、堆栈帧以及它们的关系。
DWARF由一系列的“调试节”组成,每个节包含特定类型的调试信息。比如 .debug_info: 包含关于程序结构的信息,如变量、类型和过程。.debug_line: 包含源代码行号和地址信息的映射,这对于在调试器中定位源代码位置非常有用。可以在 DWARF 官网 上看到具体格式标准,比如当前的 Version 5 版本,有一个 PDF 记录详细的规范。
How debuggers work: Part 3 - Debugging information 这篇文章用实际代码,结合 objdump 和 readelf 工具,深入探讨了 DWARF 调试信息格式,值得一读。
对于 C++ 项目来说,为了在编译时生成包含 DWARF 调试信息的二进制文件,需要使用编译器的编译选项。对于 GCC 和 Clang 编译器,这通常是通过使用 -g 标志来完成的。下面是一个简单的示例代码:
1 | // dwarf.cpp |
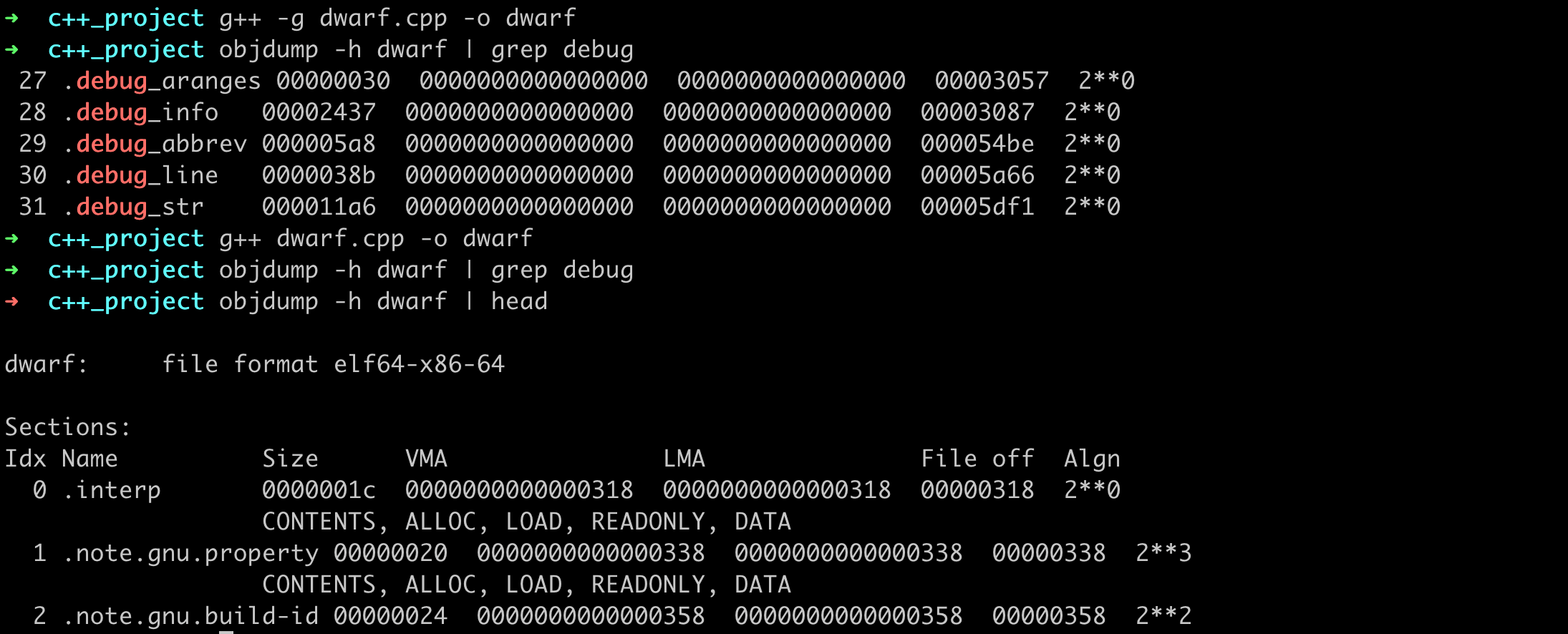
在生成的 ELF 二进制文件中,我们用 objdump 的 [-h|--section-headers|--headers] 选项,可以打印出所有的 section headers。如果用 -g 编译,生成文件包含 DWARF 调试信息,主要有 debug_aranges,.debug_info 等section。没有 -g 选项的时候,生成的二进制文件则没有这些section。
如果二进制 ELF 文件带了 DWARF 信息,用 GDB 调试的时候,就可以设置函数行断点、单步执行代码、检查变量值,并查看函数调用堆栈等。此外,传统的性能分析工具 perf,也可以读取 DWARF 信息来解析函数调用堆栈,如下命令即可:
1 | perf record --call-graph dwarf ./my_program |
Frame Pointer 解析堆栈
虽然 DWARF 信息对于调试非常有用,但基于 eBPF 的工具不能读取 DWARF 里面的堆栈信息。在 eBPF 中使用另外方法读取堆栈信息,那就是帧指针(frame pointer),帧指针可以为我们提供完整的堆栈跟踪。帧指针是 perf 的默认堆栈遍历,也是目前 bcc-tools 或 bpftrace 唯一支持的堆栈遍历技术。
为了在生成的二进制文件中保留帧指针,要确保在编译程序时启用帧指针。这可以通过使用编译器标志来完成,例如在 GCC 中使用 -fno-omit-frame-pointer。下面是一个简单的示例代码:
1 | // fp_demo_write.cpp |
用 -fno-omit-frame-pointer 编译后,可以用 profile 拿到 cpu 耗时的函数调用堆栈,之后用 FlameGraph 可以拿到 cpu 火焰图。
1 | g++ fp_demo_write.cpp -fno-omit-frame-pointer -o fp_demo_write |
这里 CPU 火焰图如下,可以看到整体函数调用链路,以及各种操作的耗时:

上面示例函数中,我们用 write(STDOUT_FILENO, message, 16); 来打印字符串,这里一开始用了c++的 std::cout 来打印,结果 cpu 火焰图有点和预期不一样,可以看到和 __libc_start_call_main 同级别的,有一个 unknown 函数帧,然后在这里面有 write 和 std::basic_ostream<char, std::char_traits<char> >::~basic_ostream() 函数。

理论上这里所有的函数都应该在 main 的函数栈里面的,但是现在并列有了一个 unknown 的调用堆栈。可能是和 C++ 标准库 glibc 的内部工作方式和缓冲机制有关,在使用 std::cout 写入数据时,数据不会立即写入标准输出,而是存储在内部缓冲区中,直到缓冲区满或显式刷新。这里的输出由 glibc 控制,所以调用堆栈不在 main 中。
如果想验证我们的二进制文件是否有帧指针的信息,可以用 objdump 拿到反汇编内容,然后看函数的开始指令是不是 push %rbp; mov %rsp,%rbp 即可。对于前面的例子,我们可以看到反汇编结果如下:
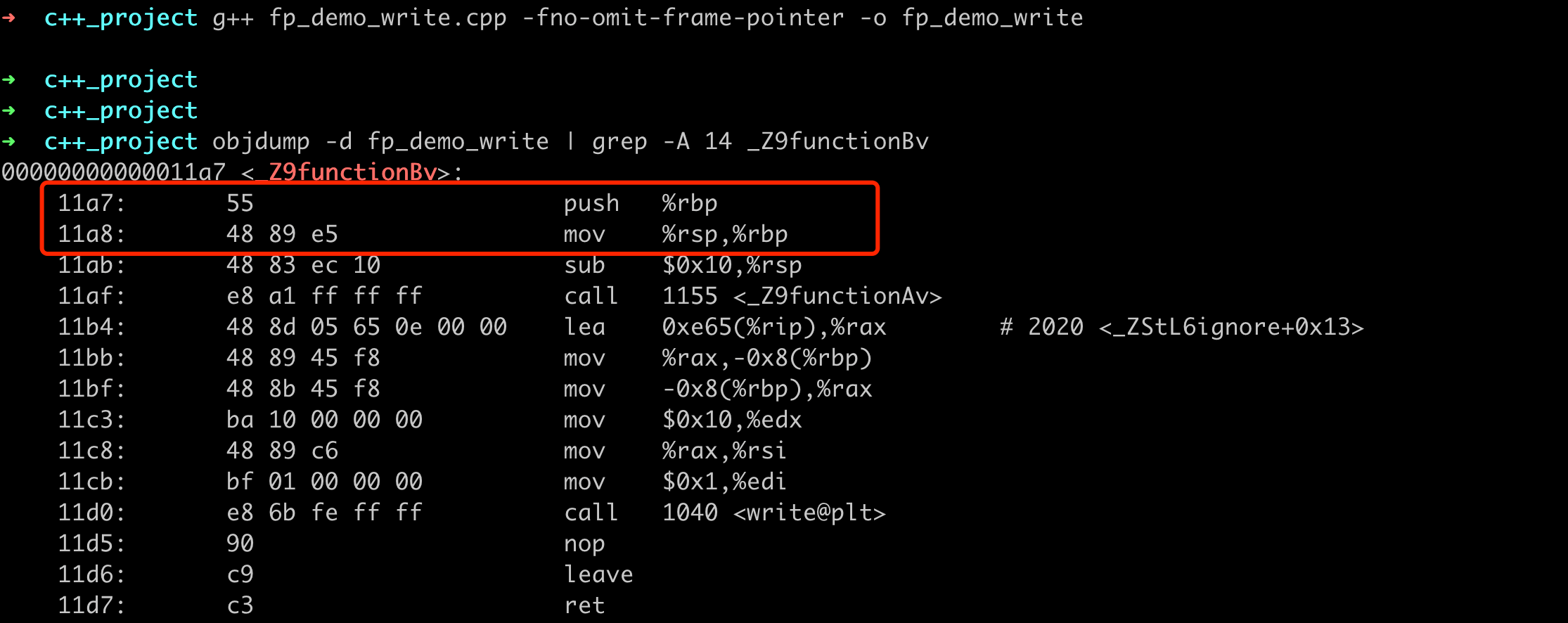
GCC/G++ 编译器中,是否默认使用-fno-omit-frame-pointer选项依赖于编译器的版本和目标架构。在某些版本和/或架构上,可能默认保留帧指针。如果没有保留帧指针,生成的二进制汇编代码中就没有相关 rbp 的部分。在我的机器上,默认编译也是有帧指针的,用 -O2 开启编译优化后生成的二进制中就没有帧指针了,如下所示:
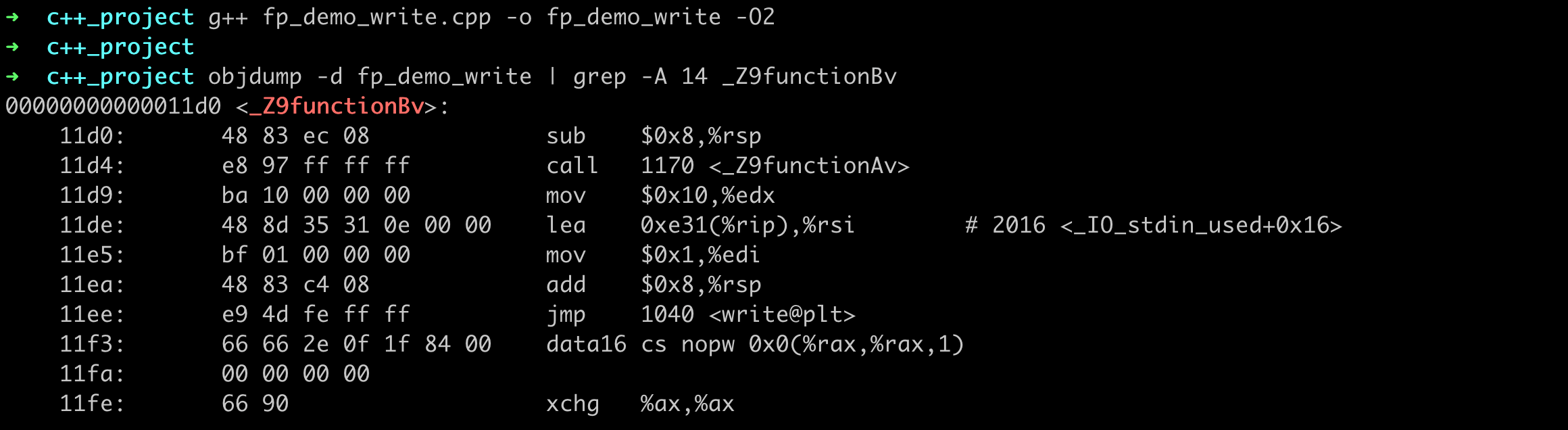
再用 profile 来分析的话,就拿不到完整的函数调用栈信息了,如下图:

在实际的项目开发中,建议在默认编译选项中加上 -fno-omit-frame-pointer,方便后面进行分析。在Linux 发行版 fedora 的 wiki 上可以看到有人就提议,默认开启 Changes/fno-omit-frame-pointer,并列举了这样做的好处以及可能的性能损失。
复杂 C++ 项目编译
上面的例子中都是编译一个简单的 cpp 文件,对于实际项目来说,可能有很多 cpp 文件,同时还有各种复杂的第三方库依赖。如何使最后编译的二进制文件保留完整的堆栈信息,就会变得有挑战。下面我们将重点来看,对于有复杂第三方依赖的项目,编译选项-fno-omit-frame-pointer 如何影响最终生成的二进制文件。
动态链接与静态链接
C++ 项目依赖第三方库有两种链接方式,静态链接和动态链接。静态链接是在编译时将所有库文件的代码合并到一个单一的可执行文件中,这意味着可执行文件包含了它所需要的所有代码,不依赖于外部的库文件。与静态链接不同,动态链接不会将库代码合并到可执行文件中。相反,它在运行时动态地加载库,这意味着可执行文件只包含对库的引用,而不是库的实际代码。
下面是静态链接和动态链接的一些特点:
| 特点 | 静态链接 | 动态链接 |
|---|---|---|
| 部署难度 | 简单,只需分发一个文件 | 较复杂,需要确保可执行文件能找到依赖的库 |
| 启动时间 | 通常更快,因为没有额外的加载开销 | 可能较慢,因为需要在运行时加载库 |
| 文件大小 | 通常较大,因为包含所有依赖的代码 | 通常较小,因为只包含对库的引用 |
| 内存占用 | 通常较高,每个实例都有其自己的库副本 | 通常较低,多个实例可以共享同一份库的内存 |
| 兼容性 | 可以更好地控制版本,因为库是嵌入的,不受外部库更新的影响 | 可能面临兼容性问题,如果外部库更新并且不向后兼容 |
对于一个大型 C++项目来说,具体选择哪种链接方式可能看团队的权衡。总的来说,项目模块之间所有可能的依赖关系可以归类为下图的几种情形:

图片由 Graphviz 渲染,图片源码如下:
1 | digraph G { |
这其中最常见的依赖方式是静态链接库依赖其他静态链接库,动态链接库依赖其他动态链接库,后面的分析会基于这两种依赖关系。动态库 A 依赖静态库 B 是可行的,并且在某些情况下是有意义的。例如,如果静态库 B 包含一些不经常变化的代码,而动态库 A 包含一些经常更新的代码。不推荐在静态库 B 中依赖动态库 A,因为静态库通常被视为独立的代码块,不依赖于外部的动态链接。
静态链接的堆栈
接下来我们分析在静态链接情况下,如果中间有第三方依赖没有带编译选项 -fno-omit-frame-pointer,会带来怎么样的影响。
假设有一个 main.cpp 依赖了 utils.cpp 和静态库 static_A,静态库 static_A 依赖了静态库 static_B,这里static_A 编译的时候没带上 -fno-omit-frame-pointer,但是其他都带了-fno-omit-frame-pointer,最终生成的二进制文件中,各静态库和 cpp 文件中的函数会有帧指针吗?这种情况下 eBPF 和 BCC 的工具能最大程度地解析出堆栈信息吗?
我们在本地创建一个完整的示例项目,包含上面的各种依赖关系,代码结构如下,完整代码在 Gist 上:
1 | FP_static_demo tree |
然后在编译生成的二进制文件中,发现 static_A 里面的函数没有帧指针,但是 static_B 和其他函数都有帧指针。运行二进制后,用 ebpf 的 profile 命令来分析 cpu 耗时堆栈,命令如下:
1 | profile -F 999 -U -f --pid $(pgrep main) 60 > depend_main.stack |
在生成的 cpu 火焰图中,拿到的函数调用堆栈是错乱的,如下图:

正常如果没丢失帧指针的话,火焰图应该如下图所示,

通过上面的实验看到,profile 工具分析性能时,依赖帧指针来重建调用堆栈。即使只丢失中间某个依赖库的帧指针,整体函数的调用堆栈就会错乱,并不是只丢失这中间的部分函数调用堆栈。
还是上面的场景,如果我们在依赖的最底层 static_B 编译的时候不保存堆栈信息,但是其他部分都保存,那么生成的二进制文件中,只有 static_B 中的函数没有帧指针。再次用 profile 分析 cpu 堆栈,发现虽然只是最后一层函数调用没有帧指针,但是 BCC tools 分析拿到的堆栈信息还是有问题,如下图,printStaticA 和 function_entry 被混到了同一层。这里多次运行,得到的堆栈信息图还可能不一样,不过都是错误的。

动态链接的堆栈
动态链接情况下,如果中间有第三方依赖没有带编译选项 -fno-omit-frame-pointer,理论上应该和静态链接一样,堆栈信息会错乱,不过还是写一个例子来验证下。还是上面的 main.cpp 和函数调用关系,把所有静态依赖改成动态依赖,重新改了下目录结构如下:
1 | tree |
完整代码还是在 Gist 上。正常堆栈如下图:

修改 Makefile,只在编译 dynamic_A 的的时候忽略堆栈,生成的 CPU 火焰图如下:

修改 Makefile,只在编译 dynamic_B 的的时候忽略堆栈,生成的 CPU 火焰图如下:

和我们前面猜想一致,一旦丢失了部分堆栈信息,分析出来的堆栈图就会有错乱。
参考文章
Practical Linux tracing ( Part 1/5) : symbols, debug symbols and stack unwinding
How debuggers work: Part 3 - Debugging information
Understanding how function call works
Hacking With GDB