mydumper-myloader
简介
mydumper 是一款开源的 MySQL 逻辑备份工具,主要由 C 语言编写。与 MySQL 自带的 mysqldump 类似,但是 mydumper 更快更高效。
mydumper 的一些优点特性:
- 轻量级 C 语言开发
- 支持多线程备份数据,备份后按表生成多个备份文件
- 支持事务性和非事务性表一致性备份
- 支持将导出的文件压缩,节约空间
- 支持多线程恢复
- 支持已守护进程模式工作,定时快照和连续二进制日志
- 支持按指定大小将备份文件切割
- 数据与建表语句分离
下载安装
安装方式非常多,以下介绍几种常见的方式。
Ubuntu 中自带了 myloader
sudo apt-get install mydumper
使用 deb 包安装,以 Ubuntu 为例
apt-get install libatomic1
wget https://github.com/mydumper/mydumper/releases/download/v0.11.5/mydumper_0.11.5-1.$(lsb_release -cs)_amd64.deb dpkg -i mydumper_0.11.5-1.$(lsb_release -cs)_amd64.deb编译安装
- docker 安装
根据实际平台情况,可选择不同的安装方式,官方也提供了一些常见的安装文档,https://github.com/mydumper/mydumper
参数说明
mydumper 参数说明
1 | -B, --database 要备份的数据库,不指定则备份所有库,一般建议备份的时候一个库一条命令 |
myloader 参数说明
1 | -d, --directory 备份文件的文件夹 |
常用案例
mydumper 导出示例
1 | 个人实际中最常用的备份语句 |
myloader 导入案例
1 | 个人实际中最常用的导入语句 |
关于 -e 参数,需要稍微注意下。默认情况下,myloader 是不开启 binlog 的,这样可以提高导入速度。如果导入实例有从库,且需要导入的结果同步到从库上,则需要使用 -e 打开 binlog 记录。
导出之后的目录如下,以数据库 d1 ,其中有表 t1 为例:1
2
3
4
5
6
7
8-d1
-0
metadata 记录备份时间点的 Binlog 信息,日志文件名和写入位置
d1-schema-create.sql 建库语句
d1-schema-post.sql 存储过程,函数,事件创建语句
d1.t1-schema.sql 表结构文件
d1.t1.sql 表数据文件,若使用了分块参数,大表的数据文件会出现多个,以数字分开。
-1
以上为比较常见的导出后的目录结构,根据实际情况不同,可能还有会含有触发器的文件,含有视图的文件等。
常见问题与实践经验
Error switching to database whilst restoring table
使用 myloader 导入时会出现这类报错,可以尝试的解决方法如下:调大 wait_timeout 参数;调大 max_packet_size 参数;使用一个线程导入, -t 1。
(myloader:35671): CRITICAL **: Error restoring test.email_logger from file test.email_logger.sql: Cannot create a JSON value from a string with CHARACTER SET ‘binary’.
MySQL 的一个 Bug,可以尝试手动修改对应的备份文件,将
/!40101 SET NAMES binary/;
修改为:
/!40101 SET NAMES utf8mb4/;
(myloader:34726): CRITICAL **: Error restoring test.(null) from file test-schema-post.sql: Access denied; you need (at least one of) the SUPER privilege(s) for this operation
在导入 AWS RDS 时部分存储过程创建失败,有比较严格的权限限制,需要导入用户有 SUPER 权限,但是 AWS RDS 用户无法授予 SUPER 权限。针对这部分存储过程,可以考虑手动在备份库上创建。
大表导出优化
使用
-r或-F参数,对导出的数据文件进行分片。备份机器配置尽可能高
备份前先预估大小,避免机器磁盘不足。尽可能选用配置较高的机器,加快备份速度。
非必要数据不备份
备份前对于不用备份的数据可以提前进行一次删除,也可在导出数据时添加正则参数等过滤部分表
备份尽量不跨网络
备份数据时尽量在内网中进行,若需要将数据迁移到外网,可以备份完之后,将备份文件拷贝到外网服务器上,尽量减少导出时网络不稳定的干扰。导入时同理。
加快导入速度的一些方法
选择合适的线程数,根据实际情况和机器配置,选择合适的线程参数,并非线程数越多越快。
导入时关闭 MySQL 的 binlog 写入,待导入完成后再开启。
在内网或较稳定的环境中进行导入。
原理与架构
mydumper 工作流程
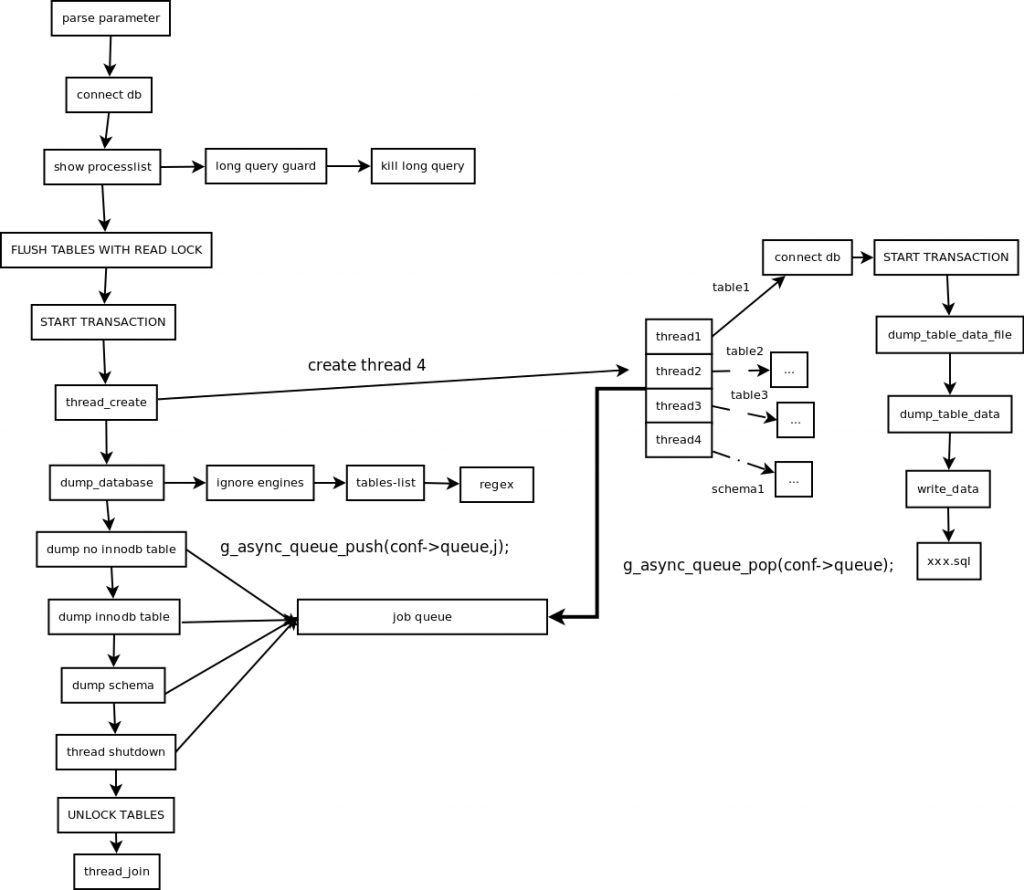
主要步骤概括
- 主线程 FLUSH TABLES WITH READ LOCK,施加全局只读锁,阻止 DML 语句写入,保证数据的一致性。
- 读取当前时间点的二进制日志文件名和日志写入的位置并记录在 metadata 文件中。
- N 个 dump 线程 START TRANSACTION WITH CONSISTENT SNAPSHOT,开启读一致的事务。
- dump non-InnoDB tables, 首先导出非事务引擎的表。
- 主线程 UNLOCK TABLES 非事务引擎备份完后,释放全局只读锁。
- dump InnoDB tables,基于事务导出 InnoDB 表。
- 事务结束。
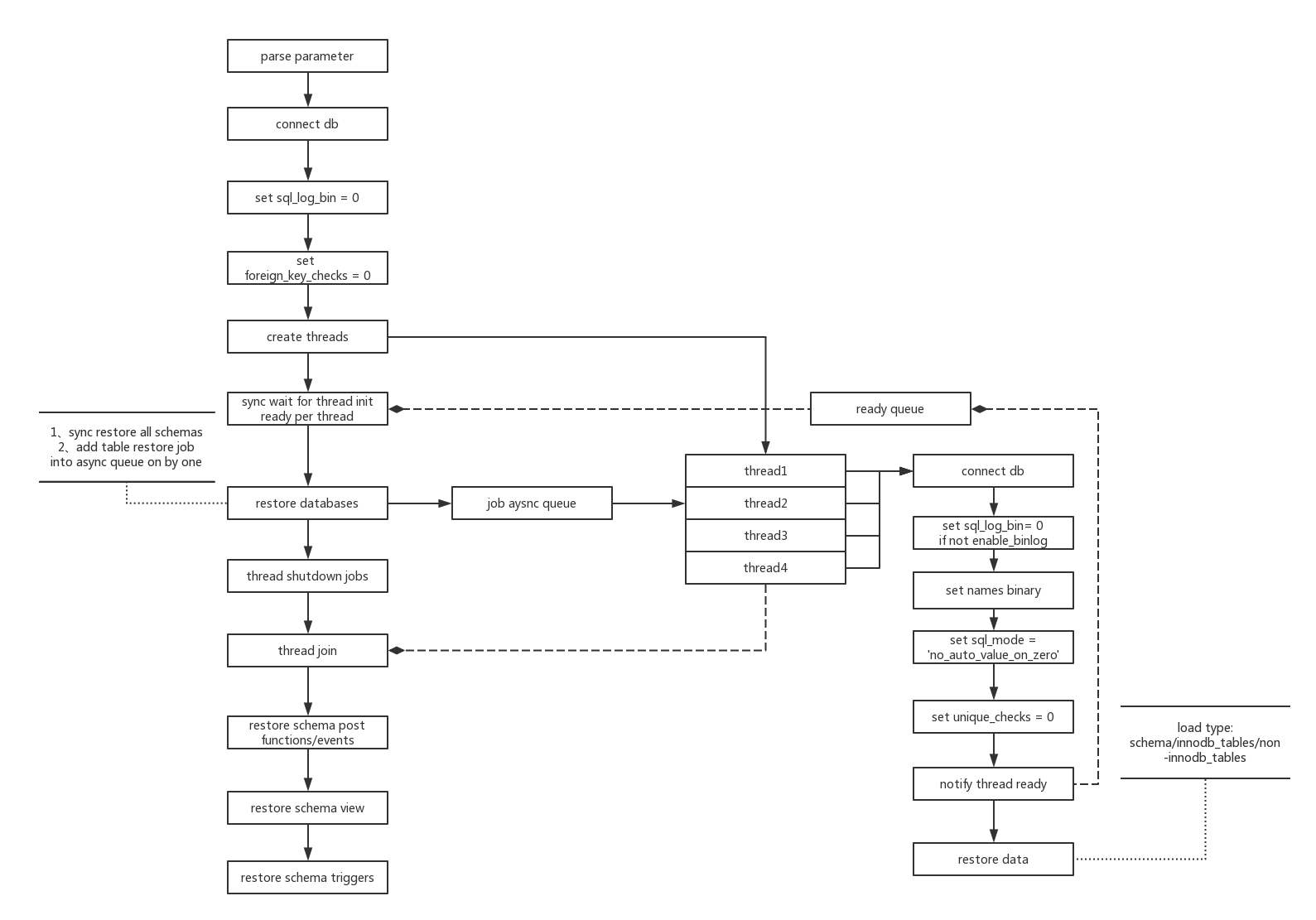
myloader 工作原理
更多技术文章,请关注我的个人博客 www.immaxfang.com 和小公众号 Max 的学习札记。