
事情的起因是这样的,前几日在看 idealclover 大佬的博客,不经意间看到了他的豆瓣观影记录,他博客中关于豆瓣观影记录是实时同步的,很好奇是如何实现的,经过查看,他是爬取的豆瓣观影界面来实现的,其实关于豆瓣观影记录,网上也有很多的教程,恰巧自己所学的 Go 语言也可以做简单的爬虫实现其效果,于是开始上手造轮子了,PS:了解到非法爬取网站信息是违法的,之前豆瓣 API 接口,关闭访问,在豆瓣上找了好久,终于在我的主页中找到了对于观影记录的官方提供 RSS 订阅,打开订阅,看到有自己所需要的字段,比较好获取,于是就开始了此项目。
分析
首先,需要获取豆瓣提供的 XML 文件,在我的主页右下角就可以看到 RSS 订阅链接:
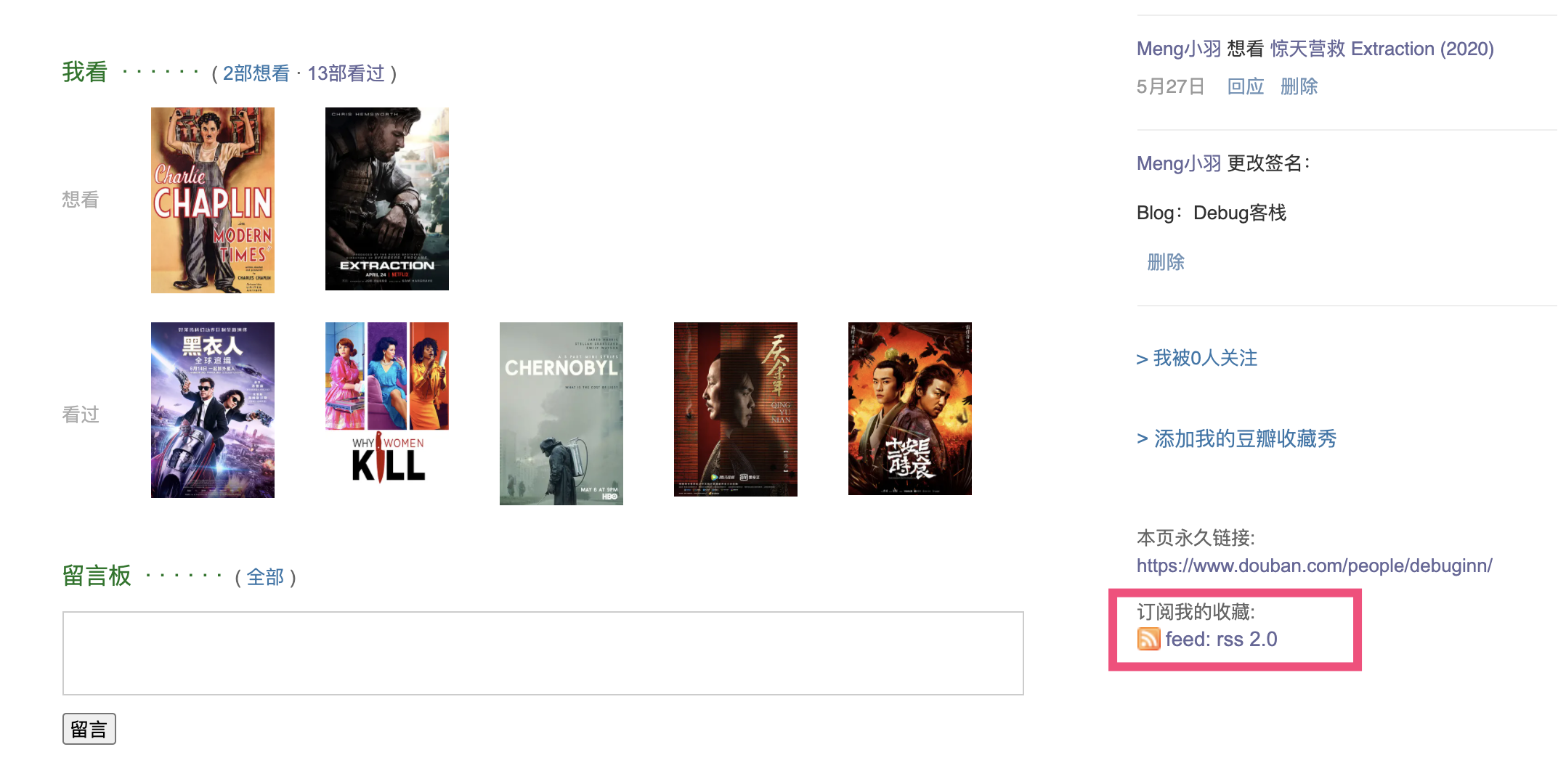
找到了订阅地址,点击查看 XML 结构,可以看到豆瓣提供的结构还是挺理想的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<rss xmlns:content="http://purl.org/rss/1.0/modules/content/" xmlns:dc="http://purl.org/dc/elements/1.1/" version="2.0">
<channel>
<title>Meng小羽 的收藏</title>
<link>https://www.douban.com/people/debuginn/</link>
<description>
<![CDATA[ Meng小羽 的收藏:想看、在看和看过的书和电影,想听、在听和听过的音乐 ]]>
</description>
<language>zh-cn</language>
<copyright>© 2013, douban.com.</copyright>
<pubDate>Sat, 30 May 2020 09:14:08 GMT</pubDate>
<item>
<title>看过黑衣人:全球追缉</title>
<link>http://movie.douban.com/subject/19971676/</link>
<description>
<![CDATA[ <table><tr> <td width="80px"><a href="https://movie.douban.com/subject/19971676/" title="Men in Black International"> <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2558701068.webp" alt="Men in Black International"></a></td> <td> <p>推荐: 力荐</p> </td></tr></table> ]]>
</description>
<dc:creator>Meng小羽</dc:creator>
<pubDate>Sat, 30 May 2020 09:14:08 GMT</pubDate>
<guid isPermaLink="false">https://www.douban.com/people/debuginn/interests/2402808825</guid>
</item>
......
<channel>
|
其实,我们提取的主要就是 item 标签下对应的电影信息内容:
1
2
3
4
5
6
7
8
9
10
|
<item>
<title>看过黑衣人:全球追缉</title>
<link>http://movie.douban.com/subject/19971676/</link>
<description>
<![CDATA[ <table><tr> <td width="80px"><a href="https://movie.douban.com/subject/19971676/" title="Men in Black International"> <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2558701068.webp" alt="Men in Black International"></a></td> <td> <p>推荐: 力荐</p> </td></tr></table> ]]>
</description>
<dc:creator>Meng小羽</dc:creator>
<pubDate>Sat, 30 May 2020 09:14:08 GMT</pubDate>
<guid isPermaLink="false">https://www.douban.com/people/debuginn/interests/2402808825</guid>
</item>
|
设计
根据豆瓣官方提供的 XML 标签数据,可以利用 Go 语言中 encoding/xml 包来进行对数据的映射,可以设计成如下结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// 豆瓣 xml 描述结构体
type Attributes struct {
XMLName xml.Name `xml:"rss"`
Version string `xml:"version,attr"`
Channel Channel `xml:"channel"`
}
// XML 主题结构拆分
type Channel struct {
Title string `xml:"title"`
Link string `xml:"link"`
Description string `xml:"description"`
Language string `xml:"language"`
Copyright string `xml:"copyright"`
Pubdate string `xml:"pubDate"`
MovieItem []MovieItem `xml:"item"`
}
// 豆瓣 电影列表结构体
type MovieItem struct {
Title string `xml:"title"`
Link string `xml:"link"`
Description string `xml:"description"`
Pubdate string `xml:"pubDate"`
}
|
可以和 XML 文件对应字段进行匹配,可以从上面的结构体中我们可以看到,最终我们想获取到的数据就是结构体 MovieItem 的数据。
由于是从网上链接获取数据的,在这里首先我们需要将网上豆瓣提供的 XML 文件转换成 []byte 类型的数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 获取 xml 文件数据
func getXMLData(url string) (data []byte, err error) {
// 读取 xml 文件
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
// 自定义Header
req.Header.Set("User-Agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)")
resp, err := client.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close() // 关闭文件
// 读取所有文件内容保存至 []byte
data, err = ioutil.ReadAll(resp.Body)
if err != nil {
return nil, err
}
return
}
|
上面这个函数实现的就是将 XML 文件保存至 Go 语言的数据结构的操作,现在可以将 XML 文件成功读取出来,接下来就是要进行 XML 字段与上面作出的结构体之间的映射,其实映射至结构体的过程是比较简单的,首先声明 Attributes{} 类型的结构体,之后通过 xml.Unmarshal 来实现映射拷贝,就可以得到对应的结构体类型的数据,由于我们想要的数据是结构体数据中的一部分,即 MovieItem,在得到结构体数据后就可以将想要的这一部分的数据选择抽取出来:
1
2
3
4
5
6
7
|
v := Attributes{}
unMarshalErr := xml.Unmarshal(data, &v)
if unMarshalErr != nil {
fmt.Printf("xml unmarshal failed, err:%v\n", err)
}
movieItem := v.Channel.MovieItem
|
Map 转换
在这里我们可以得到结构体中嵌套的结构体,在结构体中有一些字段我们是不想要的,需要进行处理,对于 description 这个字段中,官方提供的是一段 HTML 描述串,其中电影的描述文件是我们所需要的,对于 HTML 字符串的拆分,我们可以借助strings.Split 函数来实现截取,使用 \" 符号截取,虽然可以获取到我们想要的数据了,但是由于这个是嵌套的结构体,我们需要做一个匹配的 map 来进行存储处理好的数据,可以看代码中我的设计:
1
2
3
4
5
6
7
8
9
10
11
|
MoviesMap := make(map[int]interface{})
for i := 0; i < len(movieItem); i++ {
movie := make(map[string]string)
description := strings.Split(movieItem[i].Description, "\"")
movie["Title"] = string([]rune(movieItem[i].Title)[2:])
movie["Link"] = movieItem[i].Link
movie["Img"] = description[7]
movie["Pubdate"] = movieItem[i].Pubdate
MoviesMap[i] = movie
}
|
外层 map 是采用 map[int]interface{} 类型,在 interface{} 中存储这内层 map map[string]string 类型。
针对于 Img 地址的获取,是现根据特定符号拆分,之后获取制定位置的数据获取的。
1
2
3
|
0 map[Img:https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2558701068.jpg Link:http://movie.douban.com/subject/19971676/ Pubdate:Sat, 30 May 2020 09:14:08 GMT Title:黑衣人:全球追缉]
1 map[Img:https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2263408369.jpg Link:http://movie.douban.com/subject/1294371/ Pubdate:Thu, 28 May 2020 10:06:23 GMT Title:摩登时代]
......
|
最后就是将这个 map 做一下序列化处理,这样就可以返回给前台数据了。
1
|
data, _ = json.Marshal(MoviesMap)
|
服务
处理好数据,做了对应的处理,怎么将数据作为服务端提供给前台,在这里需要使用 Web 服务,Go 中可以使用原生 Web,不过我在这里使用的是之前学过的 Gin 框架,来提供服务的:
1
2
3
4
5
|
r := gin.Default()
r.GET("/doubanmovies", func(context *gin.Context) {
context.JSON(http.StatusOK, MoviesMap)
})
_ = r.Run(":8080")
|
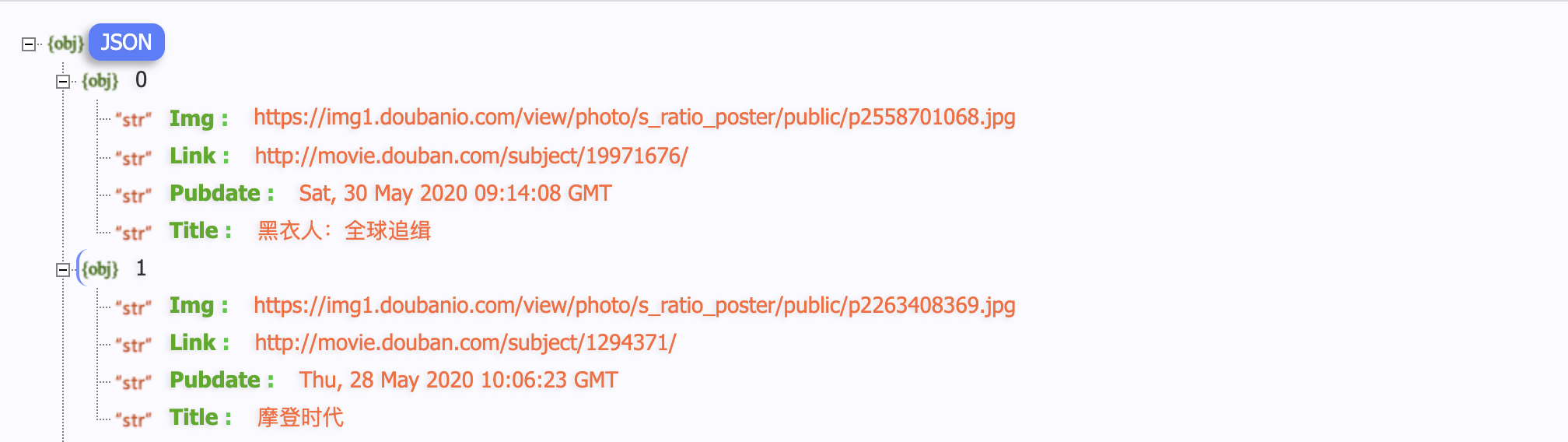
启动服务,可以得到对应的 json 数据,你若以为现在就可以实现了,那么你错了,远远没有那么简单……
前台
由于我知晓我的博客采用的前台 UI 技术是 MDUI, 我利用自身的卡片 UI 迅速设计了一个模块,因为后期需要放在我的博客页面上,前端读取数据采用的是 VUE 和 axios 技术:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<div class="mdui-container-fluid" id="app">
<div class="mdui-row">
<div v-for="item in info">
<div class="mdui-col-xs-6 mdui-col-sm-4 mdui-col-md-3 mdui-col-lg-3 mdui-m-b-1 mdui-m-t-1">
<a :href="item.Link" target="_blank">
<div class="mdui-card mdui-hoverable">
<div class="mdui-card-media">
<img :src="item.Img" style="height: 260px;" />
<div class="mdui-card-media-covered">
<div class="mdui-card-primary">
<div class="mdui-card-primary-subtitle">{{ item.Title }}</div>
</div>
</div>
</div>
</div>
</a>
</div>
</div>
</div>
</div>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<script src="./static/js/mdui.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/vue/2.1.8/vue.min.js"></script>
<script src="https://cdn.staticfile.org/axios/0.18.0/axios.min.js"></script>
<script>
new Vue({
el: '#app',
data() {
return {
info: null
}
},
mounted() {
axios
.get('http://127.0.0.1:8080/doubanmovies')
.then(response => (this.info = response.data))
.catch(function (error) { // 请求失败处理
console.log(error);
});
}
})
</script>
|
设计好了以后,访问页面,却加载不出来,emmmmmm

CORS
看到了是 CORS 同源策略的原因,接下来就是要解决同源问题了,方法比较简单,就是将 Go 服务端加上 CORS 同源策略就可以了,方法如下:
1
2
3
4
5
6
7
|
r := gin.Default()
r.Use(Cors())
r.GET("/doubanmovies", func(context *gin.Context) {
context.JSON(http.StatusOK, MoviesMap)
})
_ = r.Run(":8080")
|
在路由访问中添加 Cors() 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// 跨域
func Cors() gin.HandlerFunc {
return func(c *gin.Context) {
method := c.Request.Method //请求方法
origin := c.Request.Header.Get("Origin") //请求头部
var headerKeys []string // 声明请求头keys
for k, _ := range c.Request.Header {
headerKeys = append(headerKeys, k)
}
headerStr := strings.Join(headerKeys, ", ")
if headerStr != "" {
headerStr = fmt.Sprintf("access-control-allow-origin, access-control-allow-headers, %s", headerStr)
} else {
headerStr = "access-control-allow-origin, access-control-allow-headers"
}
if origin != "" {
c.Writer.Header().Set("Access-Control-Allow-Origin", "*")
c.Header("Access-Control-Allow-Origin", "*") // 这是允许访问所有域
c.Header("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE,UPDATE") //服务器支持的所有跨域请求的方法,为了避免浏览次请求的多次'预检'请求
// header的类型
c.Header("Access-Control-Allow-Headers", "Authorization, Content-Length, X-CSRF-Token, Token,session,X_Requested_With,Accept, Origin, Host, Connection, Accept-Encoding, Accept-Language,DNT, X-CustomHeader, Keep-Alive, User-Agent, X-Requested-With, If-Modified-Since, Cache-Control, Content-Type, Pragma")
// 允许跨域设置 可以返回其他子段
c.Header("Access-Control-Expose-Headers", "Content-Length, Access-Control-Allow-Origin, Access-Control-Allow-Headers,Cache-Control,Content-Language,Content-Type,Expires,Last-Modified,Pragma,FooBar") // 跨域关键设置 让浏览器可以解析
c.Header("Access-Control-Max-Age", "172800") // 缓存请求信息 单位为秒
c.Header("Access-Control-Allow-Credentials", "false") // 跨域请求是否需要带cookie信息 默认设置为true
c.Set("content-type", "application/json") // 设置返回格式是json
}
//放行所有OPTIONS方法
if method == "OPTIONS" {
c.JSON(http.StatusOK, "Options Request!")
}
// 处理请求
c.Next() // 处理请求
}
}
|
这样就可以看到结果了,如下图:

看到结果后,心中窃喜,感觉成功了,接下来就需要将 Go 服务部署到我的服务器中去了,部署步骤比较简单,就不过多解释了,最后访问服务器 IP 及对应单口可以呈现结果,最后将前台代码粘贴到新建的页面中,生成预览,emmmm,啥都没有,浏览器居然报 HTTPS 请求 HTTP 资源是不安全的,吐了一口血,解决吧,唉,经过查询资料,得出如下两个解决方案:
- Gin 框架服务本身使用 SSL 证书,实现 HTTPS 访问,不过需要配置域名;
- 使用 Nginx 服务做一下代理,将一个特定链接代理到本身服务中去。
作为学生党的我,没有太多的资金去申请过多的 SSL 证书(省着点用),于是我就在我的 debuginn.com 子域名下做了一个代理。
代理
Nginx 代理实现也是比较简单的,就是将前端访问某个接口代理至服务器中某个端口的服务中,表面上看是 Nginx 在做数据处理,实际上是 Nginx 只做了一个代理转发,由于我www.debuginn.com 子域名本身就是 https 的,所以设置好了代理之后,就可以使用固定的代理链接访问了,配置如下:
1
2
3
4
5
6
7
8
9
|
server{
.....
location /douban_movies {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host:80;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
|
这样就可以实现 https 资源访问了:https://debuginn.com/doubanmovies
效果
解决了 HTTPS 访问 HTTP 资源的问题,就解决了所有问题,实现了效果。
具体效果如下:https://debuginn.com/doubanmovies
开源
针对于此小项目,我已经开源至 Github 中,若是你感兴趣或者有什么建议,可以联系我,我们一起改进,同时希望你可以给我一个 Star,万分感谢!
https://github.com/debuginn/douban-movies