【竞品分析】Dify.AI的全解析(2/2)
接着上一篇对于Dify中类似GPTs、Agent部分的介绍,本文将重点介绍知识库等Memory方面的分析,包括如何进行提升。
1 知识库
1.1 创建流程
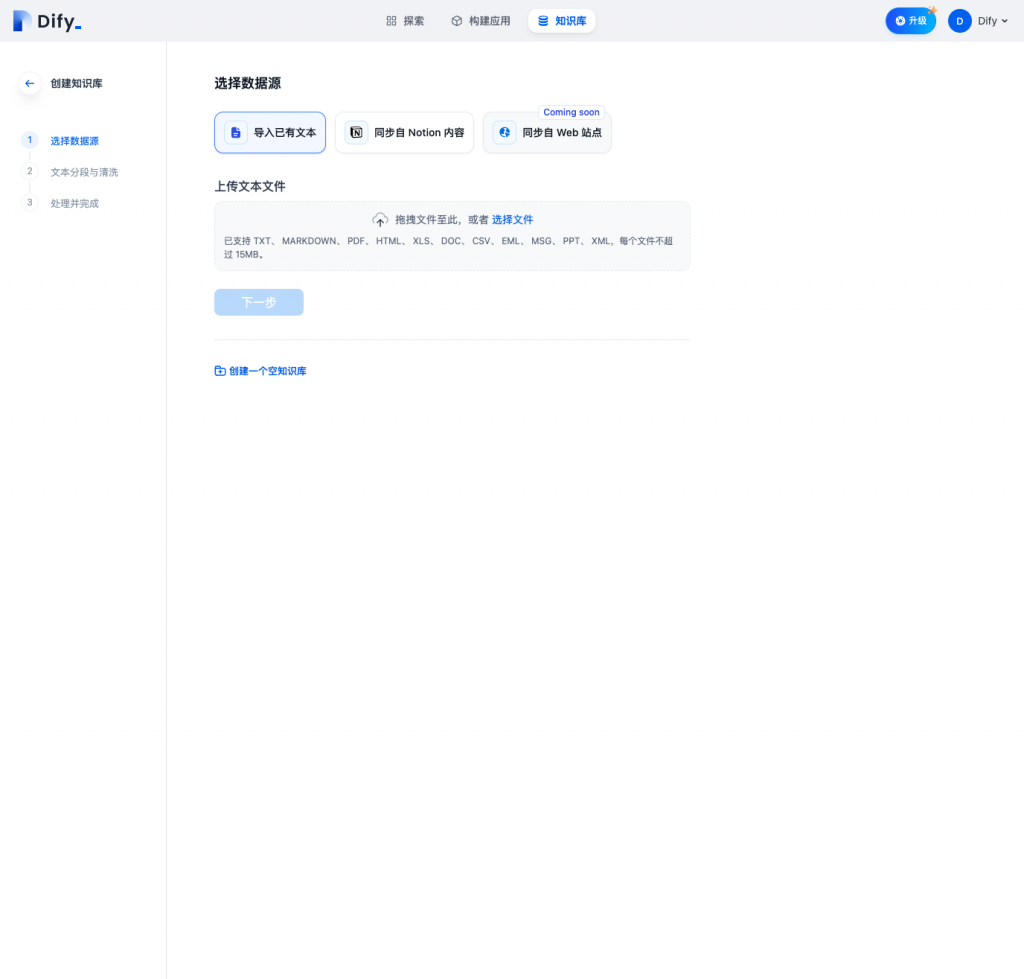
第一步 提交文档
目前支持两种方式的数据源提交
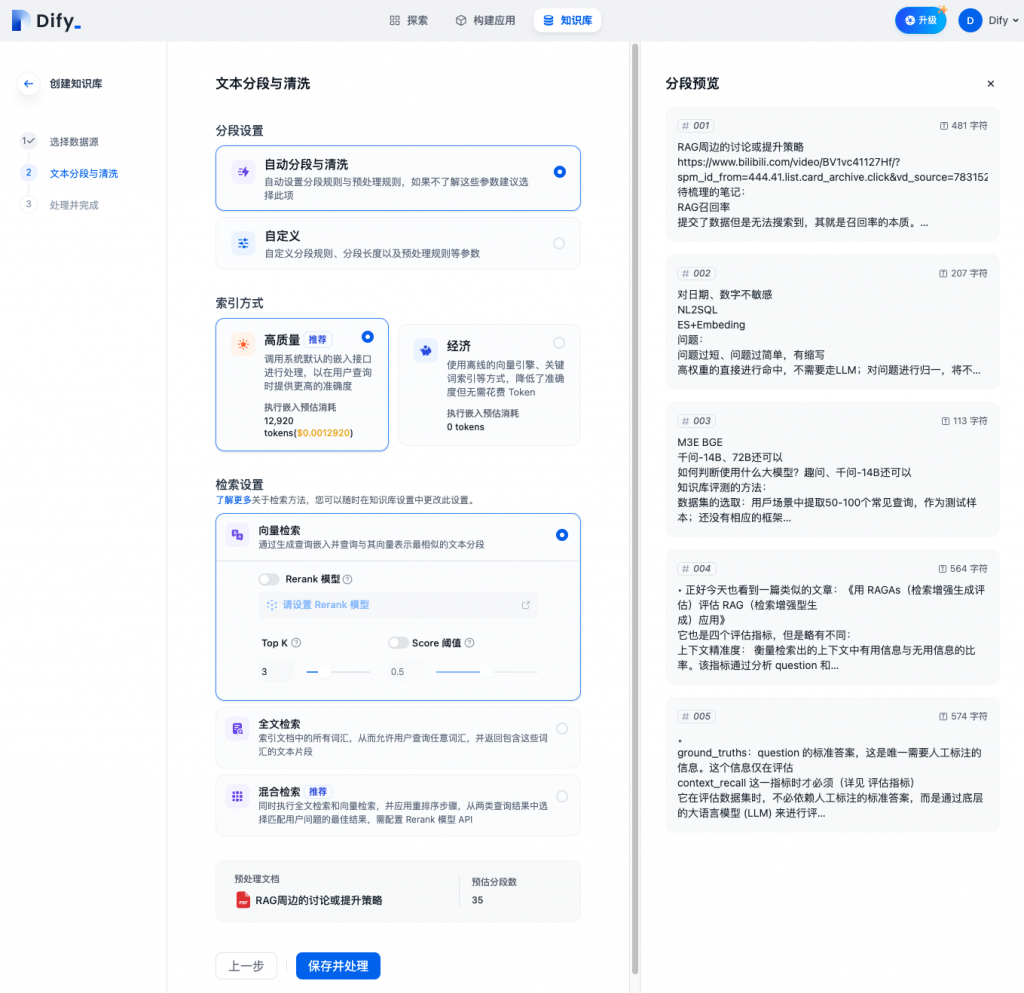
第二步 文本分段和清洗
以一种实时交互的方式展示切片信息,并提供了丰富的分段逻辑和切片清洗逻辑(下文详细描述)
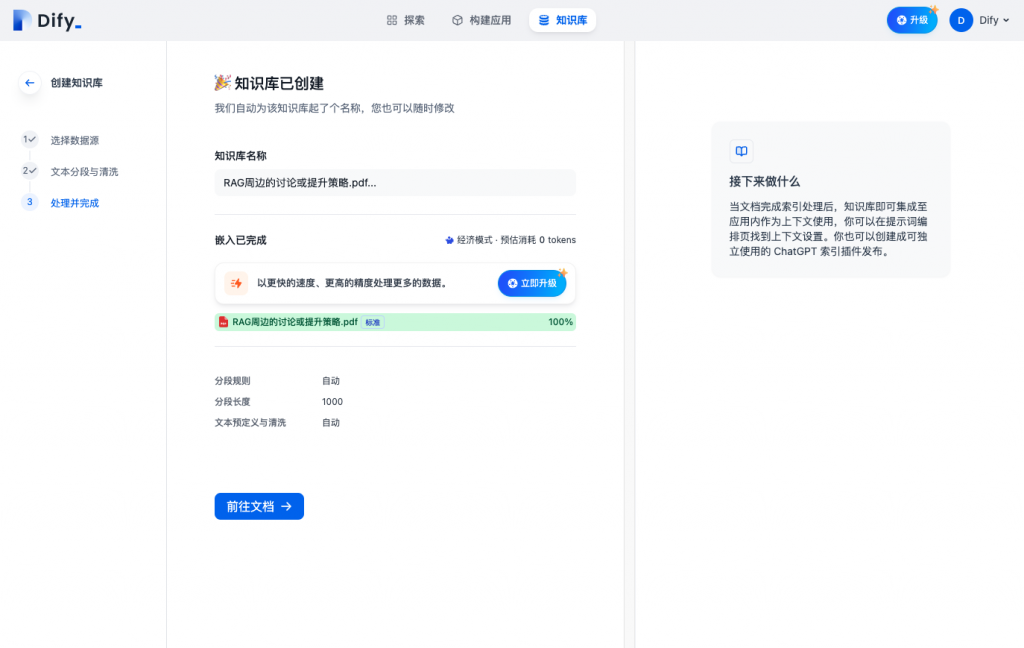
第三步 创建成功的引导
整个创建过程和主流的处理方案基本一致,但交互更加细腻,尤其是准实时的方式展示切片效果方便对chunk不熟悉的用户有一个直观的感受。同时,提供了多种的高级设置。

进入详情页面后可查看同步的数据信息,并进行后续的管理
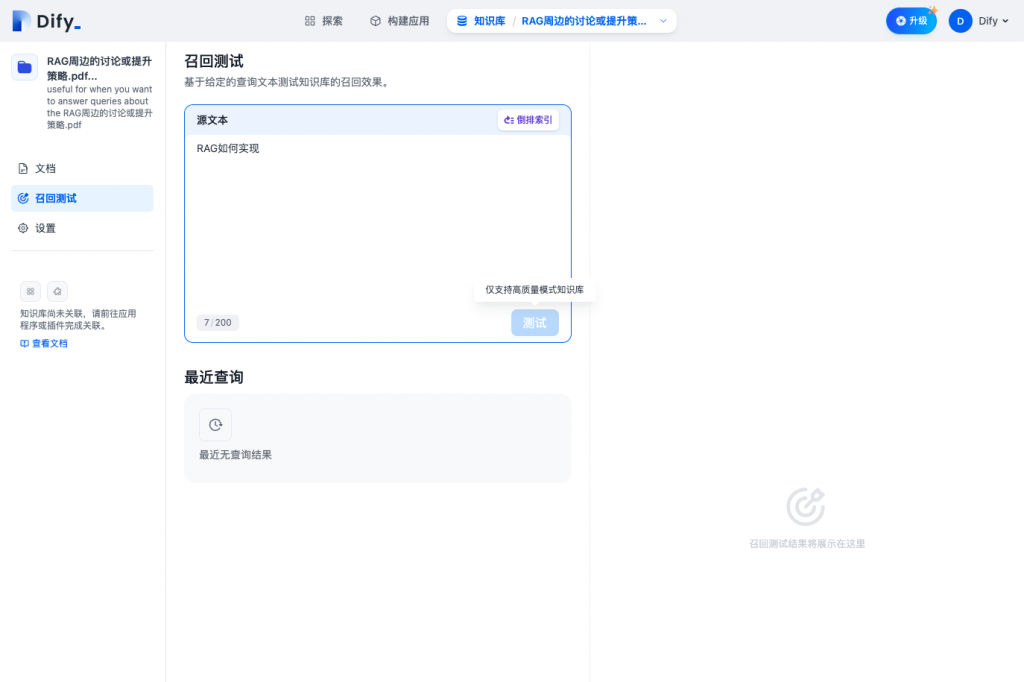
同时支持召回测试,通过搜索验证召回效果

除了支持创建时候的索引模式、检索设置之外,也支持权限等配置
1.2 高级设置
在本章节,将重点分析知识库中的一些高级设置。
分段设置
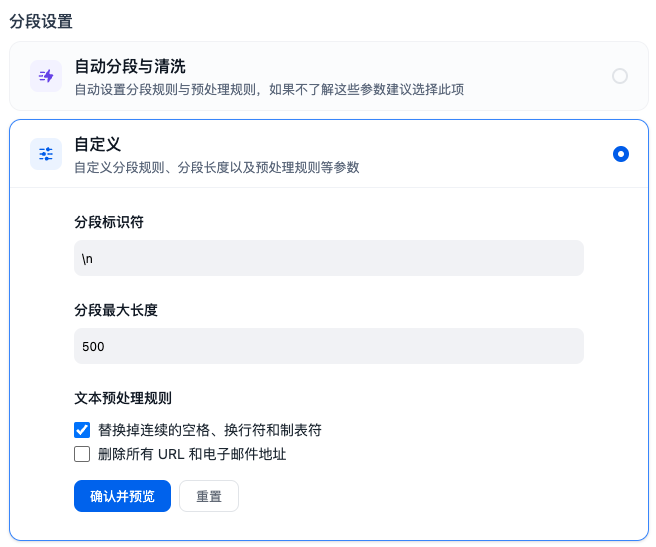
系统支持进行自定义的切片逻辑;但从过往的实际经验来看,文档内容提取和切片其实是两个过程。
由于不同格式数据的影响,在进行内容提取时候并不十分精准;比如图片、表格、分栏格式等处理还需要重点进行关注。
另外,业界大多也任务,切片对搜索精准率的影响比重较大,中英文等切片规则可能也不一样,这些都需要在实际工程中进行验证测试,不能一概而论。
索引方式
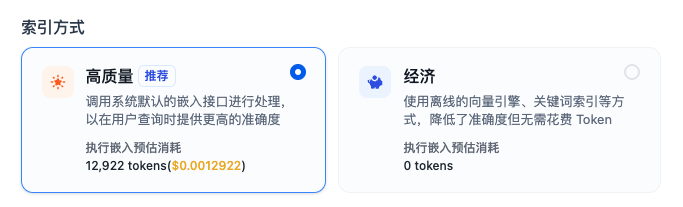
系统提供了两种方式:
第一种通过Embedding进行向量化,后续依赖向量数据库的近似匹配完成搜索,需要消耗一定的token;
第二种是通过传统关键词搜索的方式构建索引,采用类似ES的组件完成搜索。
市面上,其实有很多RAG产品也在采取多路召回的方式,通过“关键词搜索+向量搜索”方式来完成最终的搜索。Dify在公开资料中也提及了该方式。
详见右侧针对不同索引方式的检索设置。
检索方式——针对经济索引方式
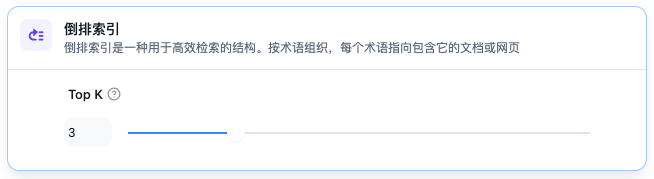
倒排索引仅提供了Top_K结果的返回
检索方式——针对高质量索引

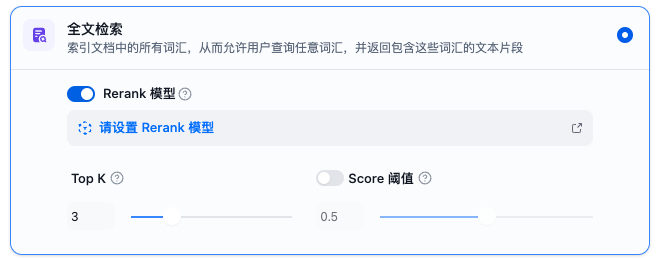
针对高质量索引方式则复杂的较多,支持向量检索、全文检索以及混合检索。
1.3 混合检索=向量检索+全文检索
1.3 知识库相关的知识
从Dify公开资料中可以获得其对于数据集、文档切片和清洗、数据集元数据的一些具体实践。
1.3.1 数据集
在 Dify 中,数据集(Knowledge)是一些文档(Documents)的集合。一个数据集可以被整体集成至一个应用中作为上下文使用。
一个应用支持引用多个数据集,AI 会根据用户的提问和数据集的描述来决定使用哪个数据集来回答用户的问题。因此,良好的数据集描述能提升 AI 选择数据集的准确率。
编写良好的数据集描述的要点是写清楚数据集包含的内容和特点。数据集的描述建议以这个开头:仅当你想要回答的问题是关于以下内容时有用:具体描述。
一个房地产数据集的描述:
仅当你想要回答的问题是关于以下内容时有用: 2010 年到 2020 年的全球房地产市场数据。这些数据包括每个城市的平均房价、房产销售量、房屋类型等信息。此外,该数据集还包括了一些经济指标,如 GDP、失业率等,以及一些社会指标,如人口数量、教育水平等,这些指标可以帮助分析房地产市场的趋势和影响因素。
通过这些数据,我们可以了解全球房地产市场的发展趋势,分析各个城市的房价变化,以及了解经济和社会因素对房地产市场的影响。
1.3.2 数据元数据
元数据在进行搜索时候支持混合搜索(和Dify不太一样,常见向量数据库中的搜索方式),支持过滤筛选;Dify提供了书籍、网页、论文、社交媒体帖子、个人文档、商务文档、IM聊天记录等文档类型。同时在一些文档类型方面为大家做了很全面的总结。
比如:
- 个人文档包含:笔记、博客草稿、日记、研究报告、书籍摘录、日程安排、列表、项目概述、照片集、创意写作、代码片段、设计草稿、个人简历、其他
- 商务文档包含:会议纪要、研究报告、提案、员工手册、培训材料、需求文档、设计文档、产品规格、财务报告、市场分析、项目计划、团队结构、政策和流程、合同和协议、往来邮件、其他
1.3.3 文本切片和清洗
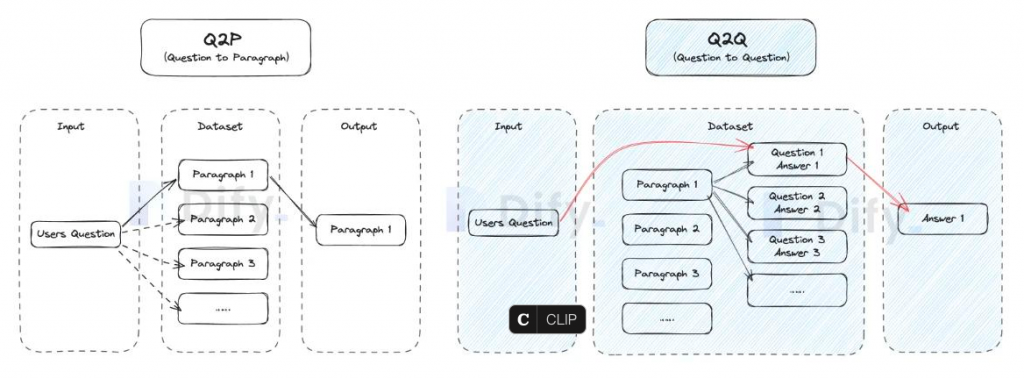
文本数据的分段与清洗是指 Dify 自动将数据进行段落分段 & 向量化处理,使得用户的提问(输入)能匹配到相关的文本段落(Q to P),最后输出结果。上传一个数据集的文档,你需要选择文本的索引方式来指定数据的匹配方式。这会影响到 AI 在回复问题时的准确度。
系统提供了三种索引方式/多路召回:
- 高质量模式下,将调用 OpenAI 的嵌入接口进行处理,以在用户查询时提供更高的准确度。
- 经济模式下,会使用关键词索引方式,降低了准确度但无需花费 Token。
- Q&A 分段模式下,Q&A 分段模式功能,与上述普通的「Q to P」(问题匹配文本段落)匹配模式不同,它是采用「Q to Q」(问题匹配问题)匹配工作,在文档经过分段后,经过总结为每一个分段生成 Q&A 匹配对,当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地获取用户真正需要的信息。
2 RAG的最佳实践
那到这里,Dify已经完成了Agent设置和知识库的搭建,剩余的就是如何提升RAG的效果,以便聊天等场景能够真的根据知识库的上下文更好的与用户产生互动。
2.1 搜索的实现
2.1.1 搜索的对比
在进行搜索的分析之前,先对搜索进行总结对比:
向量检索的优势
- 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
- 多语言理解(跨语言理解,如输入中文匹配英文)
- 多模态理解(支持文本、图像、音视频等的相似匹配)
- 容错性(处理拼写错误、模糊的描述)
向量检索的优势
- 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
- 多语言理解(跨语言理解,如输入中文匹配英文)
- 多模态理解(支持文本、图像、音视频等的相似匹配)
- 容错性(处理拼写错误、模糊的描述)
传统关键词搜索优势
- 精确匹配(如产品名称、姓名、产品编号)
- 少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
- 倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“想”“吗”在句子中承载更重要的含义)
向量搜索的劣势恰恰是传统关键词搜索的优势。对于大多数文本搜索的情景,首要的是确保潜在最相关结果能够出现在候选结果中。向量检索和关键词检索在检索领域各有其优势。混合搜索正是结合了这两种搜索技术的优点,同时弥补了两方的缺点。
2.1.2 向量搜索
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
- Top_K:用于筛选与用户问题相似度最高的文本片段。系统默认值为 3 。
- Score 阈值:用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5 。
- Rerank 模型:系统会在语义检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
2.1.3 全文搜索/关键词搜索
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
- TopK:用于筛选与用户问题相似度最高的文本片段。系统默认值为 3 。
- Rerank 模型:系统会在全文检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
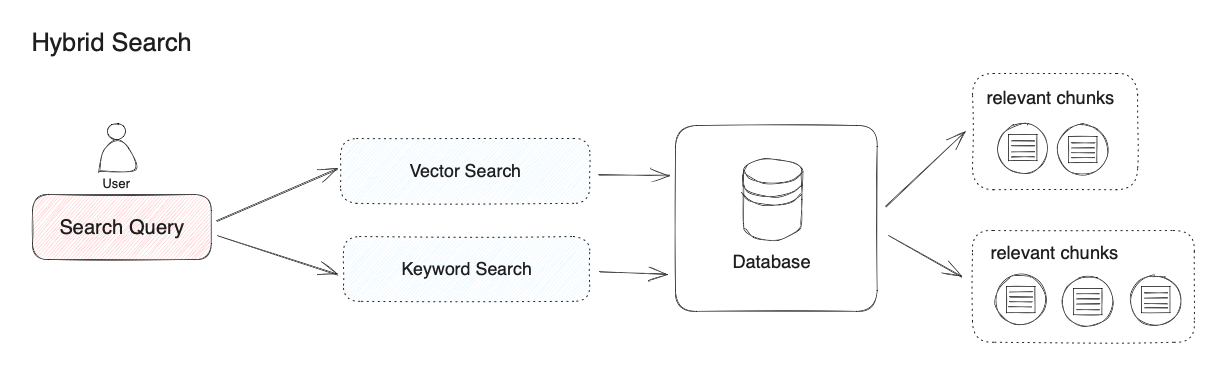
2.1.4 混合搜索
在混合检索中,你需要在数据库中提前建立向量索引和关键词索引,在用户问题输入时,分别通过两种检索器在文档中检索出最相关的文本。
- TopK:用于筛选与用户问题相似度最高的文本片段。系统默认值为 3 。
- Rerank 模型:系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
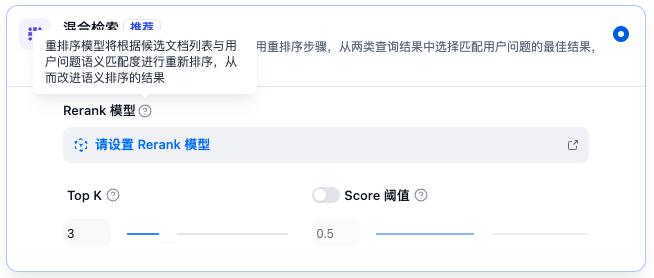
2.2 Rerank
混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
重排序模型通过将候选文档列表与用户问题语义匹配度进行重新排序,从而改进语义排序的结果。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
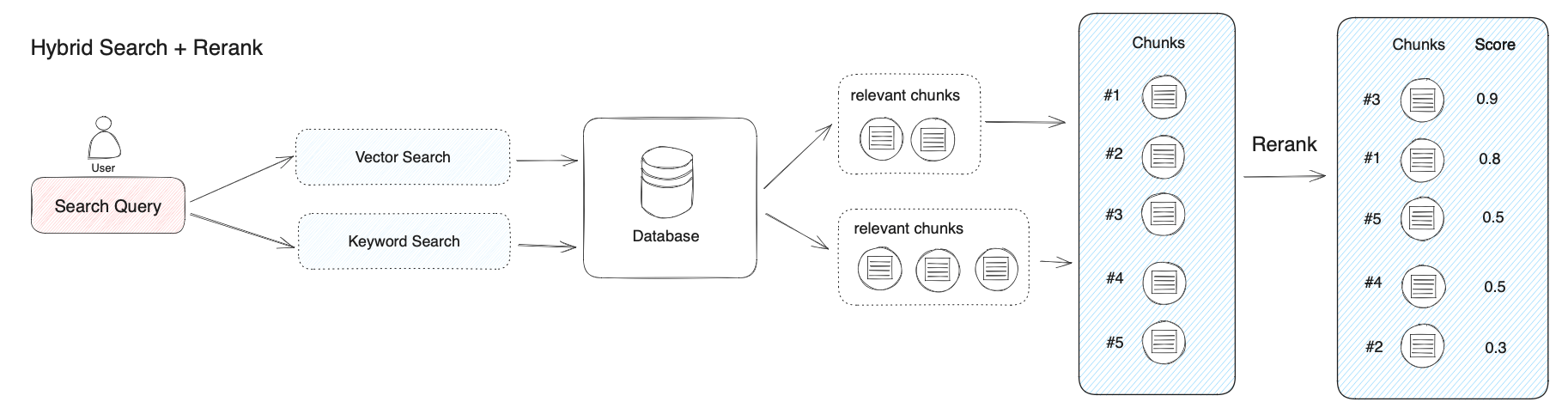
重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果。重排序并不是只适用于不同检索系统的结果合并,即使是在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果。
即使模型上下文窗口很足够大,过多的召回分段会可能会引入相关度较低的内容,导致回答的质量降低,所以重排序的 TopK 参数并不是越大越好。
重排序并不是搜索技术的替代品,而是一种用于增强现有检索系统的辅助工具。它最大的优势是不仅提供了一种简单且低复杂度的方法来改善搜索结果,允许用户将语义相关性纳入现有的搜索系统中,而且无需进行重大的基础设施修改。
以 Cohere Rerank 为例,只需要注册账户和申请 API ,接入只需要两行代码即可完成接入和使用。
2.3 召回模式
Dify的多召回方式与其他资料中描述的不太一致;其他资料中更多描述的是混合搜索的方式来提升召回率;而Dify中主要描述在检索过程中对数据集的选择和使用。
请根据文章中的具体情况自行辨别。
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个数据集,Dify 在检索时支持两种召回模式:N选1召回模式和多路召回模式。
2.3.1 N选1召回模式
根据用户意图和数据集描述,由 Agent 自主判断选择最匹配的单个数据集来查询相关文本,适合数据集区分度大且数据集数量偏少的应用。N选1召回模式依赖模型的推理能力,模型需要根据用户意图,选择最符合的一个数据集召回。在推理选择数据集时,数据集将作为 Agent 的工具类通过意图推理来进行选择,工具描述即数据集描述。
在用户上传数据集时,系统将自动为数据集创建一个摘要式的描述。
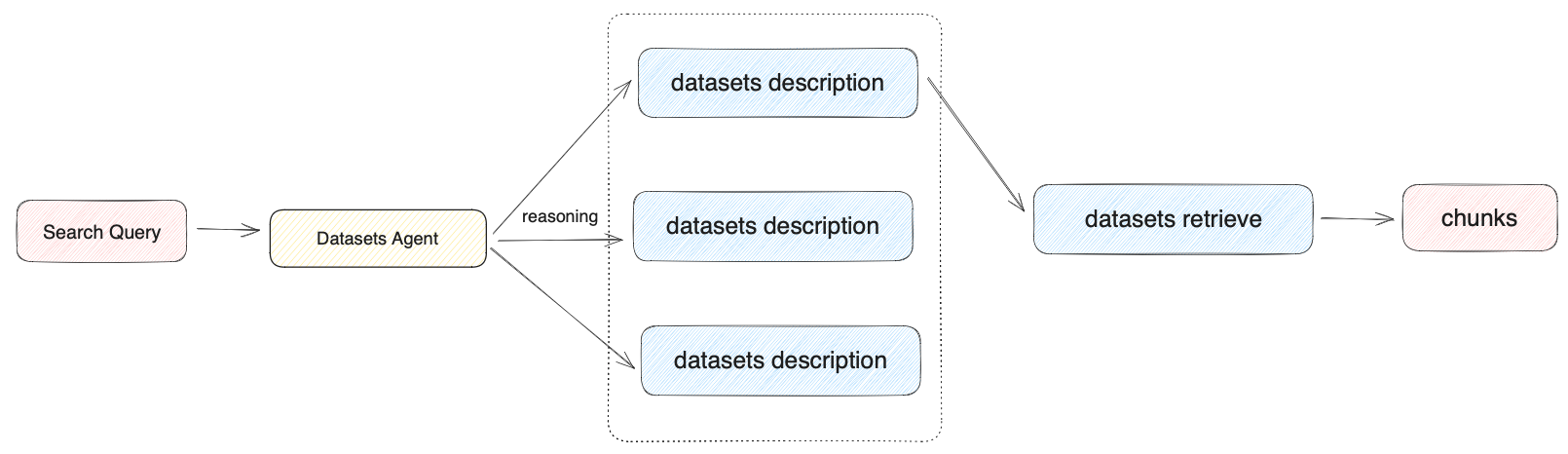
在查询数据集过多,或者数据集描述差异较小时,该模式的保证召回的效果会受到影响。该模式更适用于数据集数量较少的应用。OpenAI Function Call 已支持多个工具调用,Dify 将在后续版本中升级该模式为 “N选M召回” 。
2.3.2 多路召回模式
根据用户意图同时匹配所有数据集,从多路数据集查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的数据集中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
在多路召回模式下,需要配置 Rerank 模型。
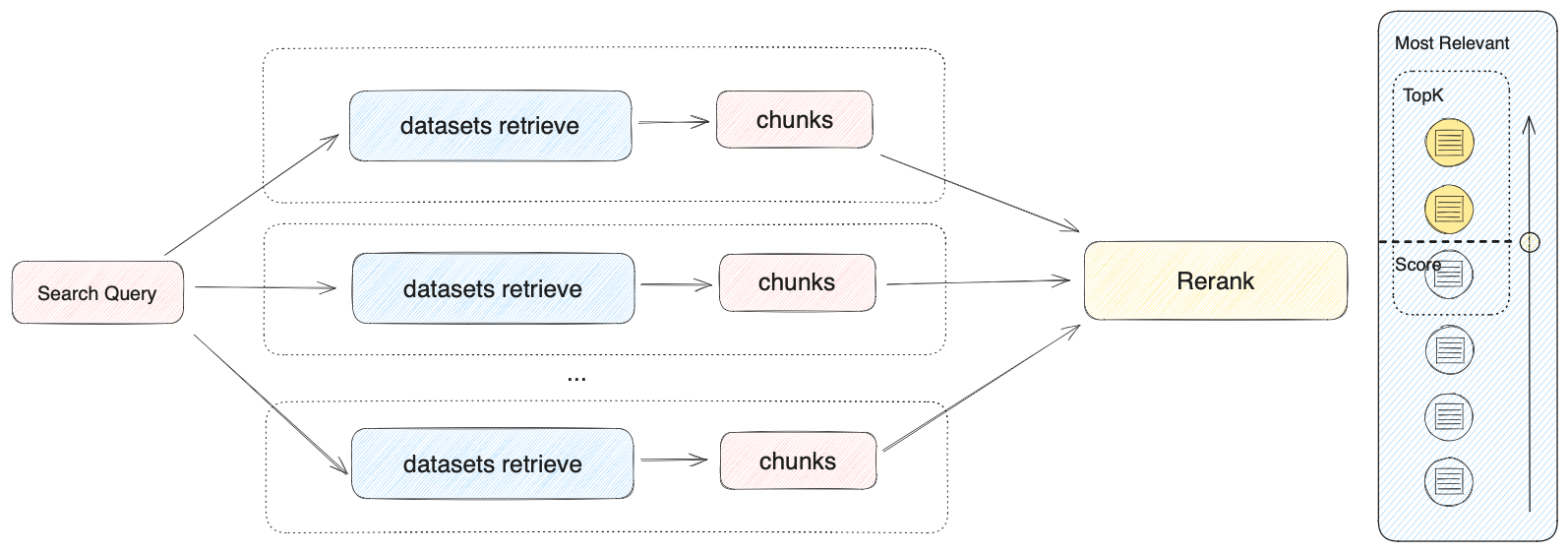
多路召回模式不依赖于模型的推理能力或数据集描述,该模式在多数据集检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个数据集时,更推荐将召回模式配置为多路召回。
3 模型的配置
Dify支持云端、本地两种类型的五种模型部署方式;当然根据各个产品的具体情况,也可以自己搭建GPU集群,但该过程依然需要大量的投入。按照SaaS的理念,使用云端服务肯定是一种比较好的方式,国内也有一些AutoDL等可用。
云端服务:
Hugging Face:支持 Text-Generation 和 Embeddings
Replicate支持接入 Replicate 上的 Language models 和 Embedding models。
本地服务框架
Xinference 是一个强大且通用的分布式推理框架,旨在为大型语言模型、语音识别模型和多模态模型提供服务,甚至可以在笔记本电脑上使用。它支持多种与GGML兼容的模型,如 chatglm, baichuan, whisper, vicuna, orca 等。
Xinference是一个强大且通用的分布式推理框架,旨在为大型语言模型、语音识别模型和多模态模型提供服务,甚至可以在笔记本电脑上使用。它支持多种与GGML兼容的模型,如 chatglm, baichuan, whisper, vicuna, orca 等。
LocalAI是一个本地推理框架,提供了 RESTFul API,与 OpenAI API 规范兼容。它允许你在消费级硬件上本地或者在自有服务器上运行 LLM。不需要 GPU。 Dify 支持以本地部署的方式接入 LocalAI 部署的大型语言模型推理和 embedding 能力。
那么到这里,针对Dify的研究就告一段落,查看了官方的一些预告,其预计在2024年1月份就会推出Flow的编排能力,这一点和我们目前正在做的基本一致,也希望我们的产品能够尽快完成内测后上线。
相关内容的传送门:
The post 【竞品分析】Dify.AI的全解析(2/2) first appeared on PMSOLO.