在 kubernetes 环境下如何优雅扩缩容 Pulsar
背景
在整个大环境的降本增效的熏陶下,我们也不得不做好应对方案。
根据对线上流量、存储以及系统资源的占用,发现我们的 Pulsar 集群有许多的冗余,所以考虑进行缩容从而减少资源浪费,最终也能省一些费用。
不过在缩容之前很有必要先聊聊扩容,Pulsar 一开始就是存算分离的架构(更多关于 Pulsar 架构的内容本文不做过多介绍,感兴趣的可以自行搜索),天然就非常适合 kubernetes 环境,也可以利用 kubernetes 的能力进行快速扩容。
扩容
Pulsar 的扩容相对比较简单,在 kubernetes 环境下只需要修改副本即可。
Broker
当我们的 broker 层出现瓶颈时(比如 CPU、内存负载较高、GC 频繁时)可以考虑扩容。
计算层都扩容了,也需要根据流量计算下存储层是否够用。
如果我们使用的是 helm 安装的 Pulsar 集群,那只需要修改对于的副本数即可。
1 | broker: |
当我们将副本数从 3 增加到 5 之后 kubernetes 会自动拉起新增的两个 Pod,之后我们啥也不需要做了。
Pulsar 的负载均衡器会自动感知到新增两个 broker 的加入,从而帮我们将一些负载高的节点的流量迁移到新增的节点中。
Bookkeeper
在介绍 bookkeeper 扩容前先简单介绍些 Bookkeeper 的一些基本概念。
- Ensemble size (E):当前 Bookkeeper 集群的节点数量
- Write quorum size (QW):一条消息需要写入到几个 Bookkeeper 节点中
- ACK quorum size (QA):有多少个 Bookkeeper 节点 ACK 之后表示写入成功
对应到我们在 broker.conf 中的配置如下:
1 | managedLedgerDefaultEnsembleSize: "2" |
这个三个参数表示一条消息需要同时写入两个 Bookkeeper 节点,同时都返回 ACK 之后才能表示当前消息写入成功。
从这个配置也可以看出,Bookkeeper 是多副本写入模型,适当的降低 QW 和 QA 的数量可以提高写入吞吐率。
大部分场景下 Bookkeeper 有三个节点然后 E/QW/QA 都配置为 2 就可以满足消息多副本写入了。
多副本可以保证当某个节点宕机后,这个节点的消息在其他节点依然有存放,消息读取不会出现问题。
那什么情况下需要扩容 Bookkeeper 了,当然如果单个 Bookkeeper 的负载较高也是可以扩容的。
但我们当时扩容 Bookkeeper 的场景是想利用 Pulsar 的资源隔离功能。
因为有部分业务的消息量明显比高于其他的 topic,这样会导致某个 Broker 的负载较高,同时也可能影响到其他正常的 topic。
最好的方式就将这部分数据用单独的 broker 和 Bookkeeper 来承载,从而实现硬件资源的隔离。
这样的需求如果使用其他消息队列往往不太好实现,到后来可能就会部署多个集群来实现隔离,但这样也会增加运维的复杂度。
好在 Pulsar 天然就支持资源隔离,只需要一个集群就可以实现不同 namespace 的流量隔离。
此时就可以额外扩容几个 Bookkeeper 节点用于特定的 namespace 使用。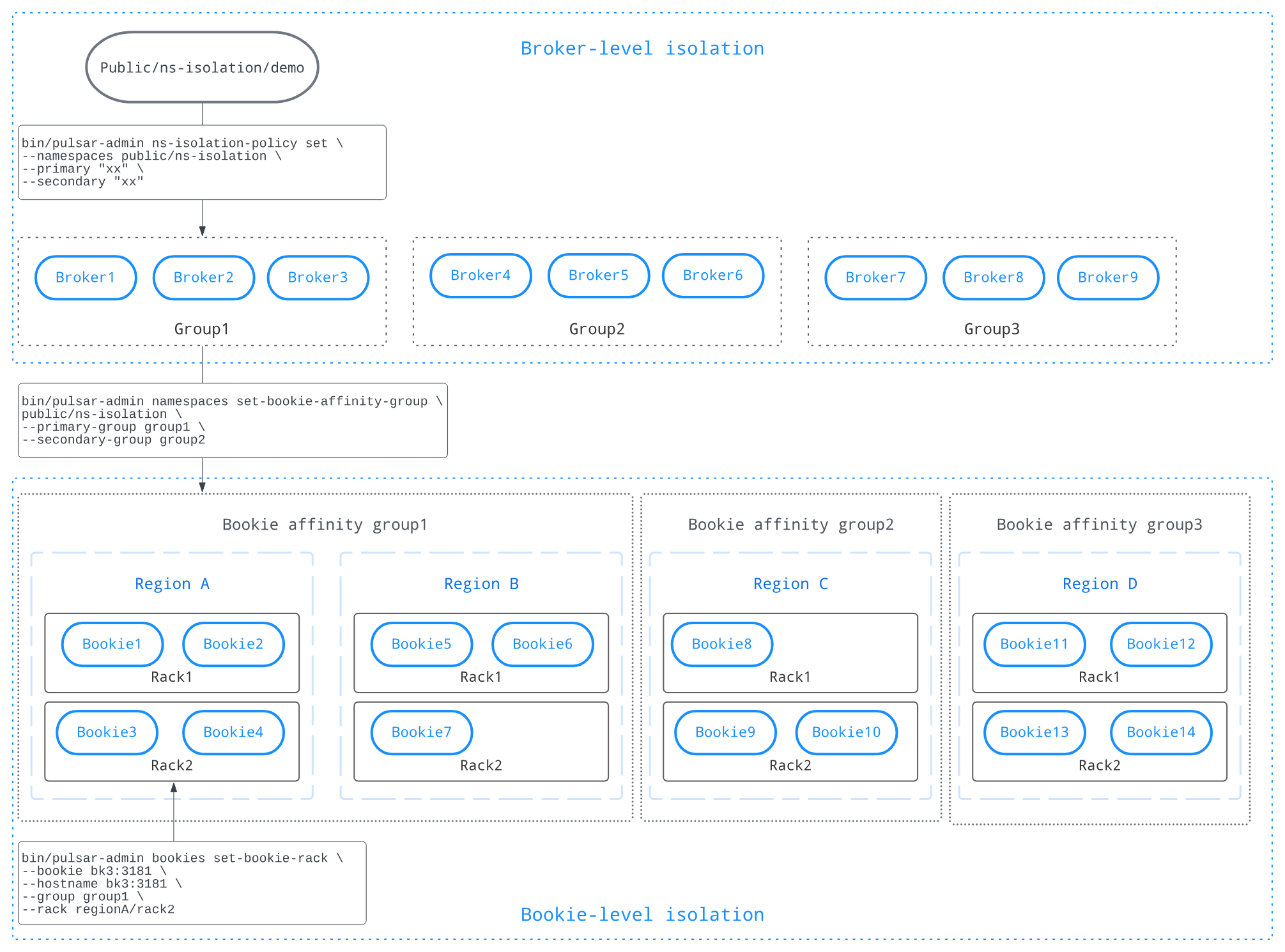
从上图可以看到:我们可以将 broker 和 Bookkeeper 分别进行分组,然后再配置对应的 namespace,这样就能实现资源隔离了。
更多关于资源隔离的细节本文就不过多赘述了。
铺垫了这么多,其实 Bookkeeper 的扩容也蛮简单的:
1 | bookkeeper: |
和 broker 扩容类似,提高副本数量后,Pulsar 的元数据中心会感知到新的 Bookkeeper 节点加入,从而更新 broker 中的节点数据,这样就会根据我们配置的隔离策略分配流量。
缩容
其实本文的重点在于缩容,特别是 Bookkeeper 的缩容,这部分内容我在互联网上很少看到有人提及。
Broker
Broker 的缩容相对简单,因为存算分离的特点:broker 作为计算层是无状态的,并不承载任何的数据。
其实是承载数据的,只是 Pulsar 会自动迁移数据,从而体感上觉得是无状态的。
只是当一个 broker 下线后,它上面所绑定的 topic 会自动转移到其他在线的 broker 中。
这个过程会导致连接了这个 broker 的 client 触发重连,从而短暂的影响业务。
正因为 broker 的下线会导致 topic 的归属发生转移,所以在下线前最好是先通过监控面板观察需要下线的 broker topic 是否过多,如果过多则可以先手动 unload 一些数据,尽量避免一次性大批量的数据转移。
观察各个broker 的 topic 数量
Bookkeeper
而 Bookkeeper 的缩容则没那么容易了,由于它是作为存储层,本身是有状态的,下线后节点上存储的数据是需要迁移到其他的 Bookkeeper 节点中的。
不然就无法满足之前提到的 Write quorum size (QW) 要求;因此缩容还有一个潜在条件需要满足:
缩容后的 Bookkeeper 节点数量需要大于broker 中的配置:
1 | managedLedgerDefaultEnsembleSize: "2" |
不然写入会失败,整个集群将变得不可用。
Pulsar 提供了两种 Bookkeeper 的下线方案:
不需要迁移数据
其实两种方案主要区别在于是否需要迁移数据,第一种比较简单,就是不迁移数据的方案。
首先需要将 Bookkeeper 设置为 read-only 状态,此时该节点将不会接受写请求,直到这个 Bookkeeper 上的数据全部过期被回收后,我们就可以手动下线该节点。
使用 forceReadOnlyBookie=true 可以强制将 Bookkeeper 设置为只读。
但这个方案存在几个问题:
- 下线时间不确定,如果该
Bookkeeper上存储的数据生命周期较长,则无法预估什么时候可以下线该节点。 - 该配置修改后需要重启才能生效,在 kubernetes 环境中这些配置都是写在了 configmap 中,一旦刷新后所有节点都会读取到该配置,无法针对某一个节点生效;所以可能会出现将不该下线的节点设置为了只读状态。
但该方案的好处是不需要迁移数据,人工介入的流程少,同样也就减少了出错的可能。
比较适合于用虚拟机部署的集群。
迁移数据
第二种就是需要迁移数据的方案,更适用于 kubernetes 环境。
迁移原理
先来看看迁移的原理:
- 当 bookkeeper 停机后,AutoRecovery Auditor 会检测到 zookeeper 节点
/ledger/available发生变化,将下线节点的 ledger 信息写入到 zookeeper 的/ledgers/underreplicated节点中。 - AutoRecovery ReplicationWorker 会检测
/ledgers/underreplicated节点信息,然后轮训这些 ledger 信息从其他在线的 BK 中复制数据到没有该数据的节点,保证 QW 数量不变。- 每复制一条数据后都会删除
/ledgers/underreplicated节点信息。 - 所有
/ledgers/underreplicated被删除后说明迁移任务完成。
- 每复制一条数据后都会删除
- 执行
bin/bookkeeper shell decommissionbookie下线命令:- 会等待
/ledgers/underreplicated全部删除 - 然后删除 zookeeper 中的元数据
- 元数据删除后 bookkeeper 才是真正下线成功,此时 broker 才会感知到 Bookkeeper 下线。
- 会等待
AutoRecovery 是 Bookkeeper 提供的一个自动恢复程序,他会在后台检测是否有数据需要迁移。
简单来说就是当某个Bookkeeper 停机后,它上面所存储的 ledgerID 会被写入到元数据中心,此时会有一个单独的线程来扫描这些需要迁移的数据,最终将这些数据写入到其他在线的 Bookkeeper 节点。
Bookkeeper 中的一些关键代码:

下线步骤
下面来看具体的下线流程:
- 副本数-1
bin/bookkeeper shell listunderreplicated检测有多少 ledger 需要被迁移
- 执行远程下线元数据
nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &- 这个命令会一直后台运行等待数据迁移完成,比较耗时
- 查看下线节点是否已被剔除
bin/bookkeeper shell listbookies -a
- 循环第一步
第一步是检测一些现在有多少数据需要迁移:bin/bookkeeper shell listunderreplicated 命令查看需要被迁移的 ledger 数据也是来自于 /ledgers/underreplicated节点
正常情况下是 0
第二步的命令会等待数据迁移完成后从 zookeeper 中删除节点信息,这个进程退出后表示下线成功。
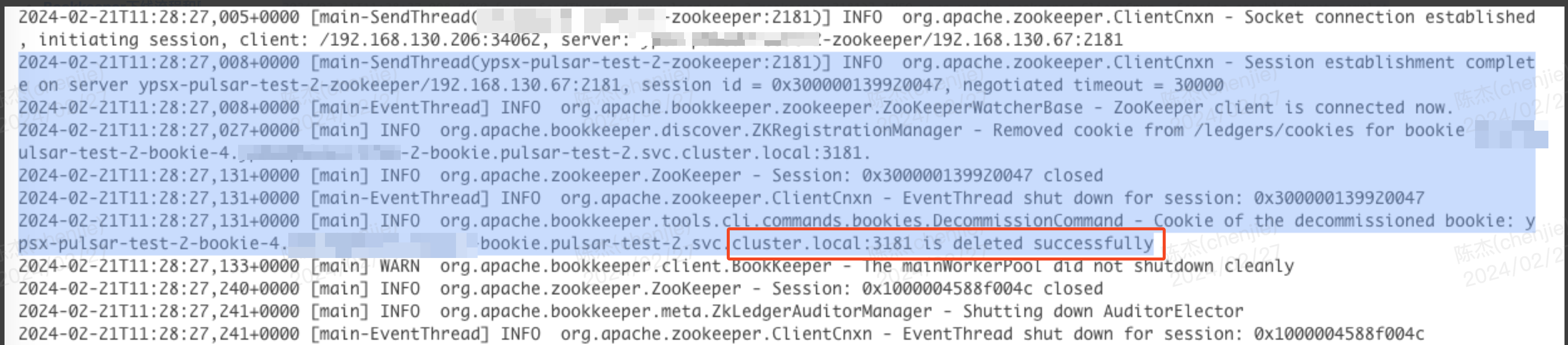
这个命令最好是后台执行,并输出日志到专门的文件,因为周期较长,很有可能终端会话已经超时了。
我们登录 zookeeper 可以看到需要迁移的 ledger 数据:
1 | bin/pulsar zookeeper-shell -server pulsar-zookeeper:2181 |
underreplication 的节点路径中存放了 ledgerId,通过 ledgerId 计算路径:
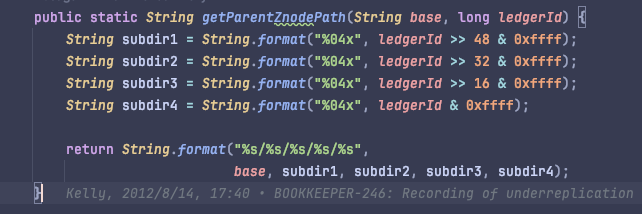
注意事项
下线过程中我们可以查看 nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &这个命令写入的日志来确认迁移的进度,日志中会打印当前还有多少数量的 ledger 没有迁移。
同时需要观察 zookeeper、Bookkeeper 的资源占用情况。
因为迁移过程中写入大量数据到 zookeeper 节点,同时迁移数时也会有大量流量写入 Bookkeeper。
不要让迁移过程影响到了正常的业务使用。
根据我的迁移经验来看,通常 2w 的ledger 数据需要 2~3 小时不等的时间,具体情况还得根据你的集群来确认。
回滚方案
当然万一迁移比较耗时,或者影响了业务使用,所以还是要有一个回滚方案:
这里有一个大的前提:
只要 BK 节点元数据、PVC(也就是磁盘中的数据) 没有被删除就可以进行回滚。
所以只要上述的 decommissionbookie 命令没有完全执行完毕,我们就可以手动 kill 该进程,然后恢复副本数据。
这样恢复的 Bookkeeper 节点依然可以提供服务,同时数据也还存在;只是浪费了一些 autorecovery 的资源。
最后当 bookkeeper 成功下线后,我们需要删除 PVC,不然如果今后需要扩容的时候是无法启动 bookkeeper 的,因为在启动过程中会判断挂载的磁盘是否有数据。
总结
总的来说 Pulsar 的扩缩容还是非常简单的,只是对于有状态节点的数据迁移稍微复杂一些,但只要跟着流程走就不会有什么问题。
参考链接:
- https://pulsar.apache.org/docs/next/administration-isolation/
- https://bookkeeper.apache.org/docs/4.13.0/admin/decomission
- https://bookkeeper.apache.org/docs/4.13.0/admin/autorecovery
#Blog #Pulsar