【计网 II】期末复习专题

前言
本章为计算机网络Ⅱ的期末复习专题,主要涉及了隧道技术、虚拟个人网、访问控制和流量控制。
期中复习部分包含了其他章节,其中的纯例题部分跳转:
期中:
期末:
隧道技术
What is the tunneling? What addresses are used in the outer header and inner header of a tunneled packet?
隧道技术是什么?在隧道数据包的外部包头和内部包头中分别使用了哪些地址?
隧道技术是使用外部包头和内部包头在两个不同端点之间建立虚拟逻辑连接的技术。其中,外部包头包含了隧道入口和出口的IP地址,内部包头包含了原始数据包的源IP地址和目标IP地址。 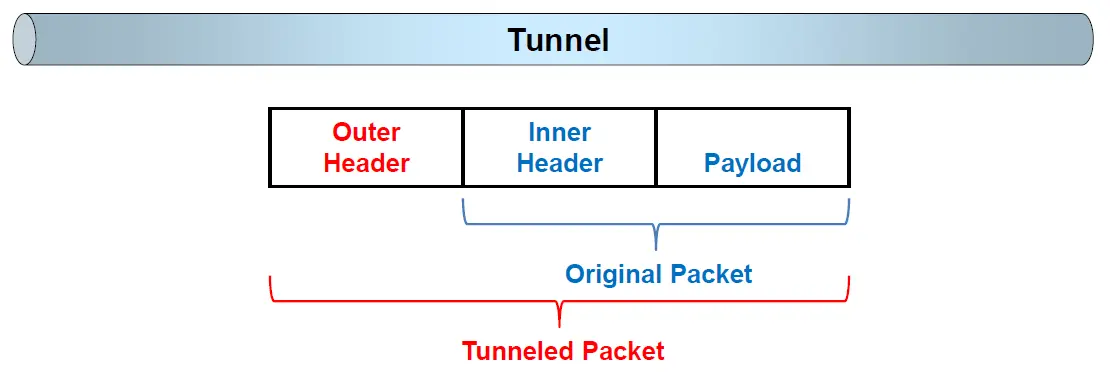
What are the common unsecure tunneling protocols and the secure tunneling protocols?
常见的不安全隧道协议和安全隧道协议有哪些?
常见的不安全的隧道协议有:
- 第二层隧道协议 (L2TP, Layer 2 Tunneling Protocol):是一种使用UDP协议发送隧道数据包的虚拟隧道协议。
- 通用路由封装 (GRE, Genetic Routing Encapsulation):是一种将使用一个路由协议的数据包封装在另一协议的数据包中的隧道技术,它规定了如何将一种网络协议下的数据报封装在另外一种网络协议中,使这些被封装的数据报能够在另一个网络层协议中传输。
安全的隧道协议常见的有:
- 互联网安全协议 (IPsec, Internet Protocol Security):是为IP网络提供安全性的协议和服务的集合,或者说是保护IP协议的网络传输协议族。
What are the two sub-protocols defined in IPsec?
IPsec定义了哪两种子协议?
IPsec有两个主要的子协议:AH(Authentication Header,身份验证头)和ESP(Encapsulating Security Payload,封装安全载荷)。 AH:
- AH通过使用哈希函数验证数据包的完整性来保护IP数据包免受干扰,它可以有效防止数据被修改。
- 当使用AH协议时,通常会使用MD5(Message Digest Algorithm 5)或SHA(Secure Hash Algorithm)这样的哈希函数来实现消息认证码(MAC)功能。
- 在传输模式下,AH header添加在IP报头之后。在隧道模式中,AH header添加在外包头和内包头之间。
 ESP:
ESP:
- ESP通过使用对称加密算法 (Symmetric Cryptography Algorithms)加密整个数据包来保护数据的机密性,它可以有效防止数据被读。
- 常见的ESP加密算法有:DES, 3DES, AES等对称加密算法。
- 在传输模式下,ESP header添加在IP报头之后,而尾部和验证添加在最后。在隧道模式中,ESP header添加在外包头和内包头之间,尾部和验证添加在最后。
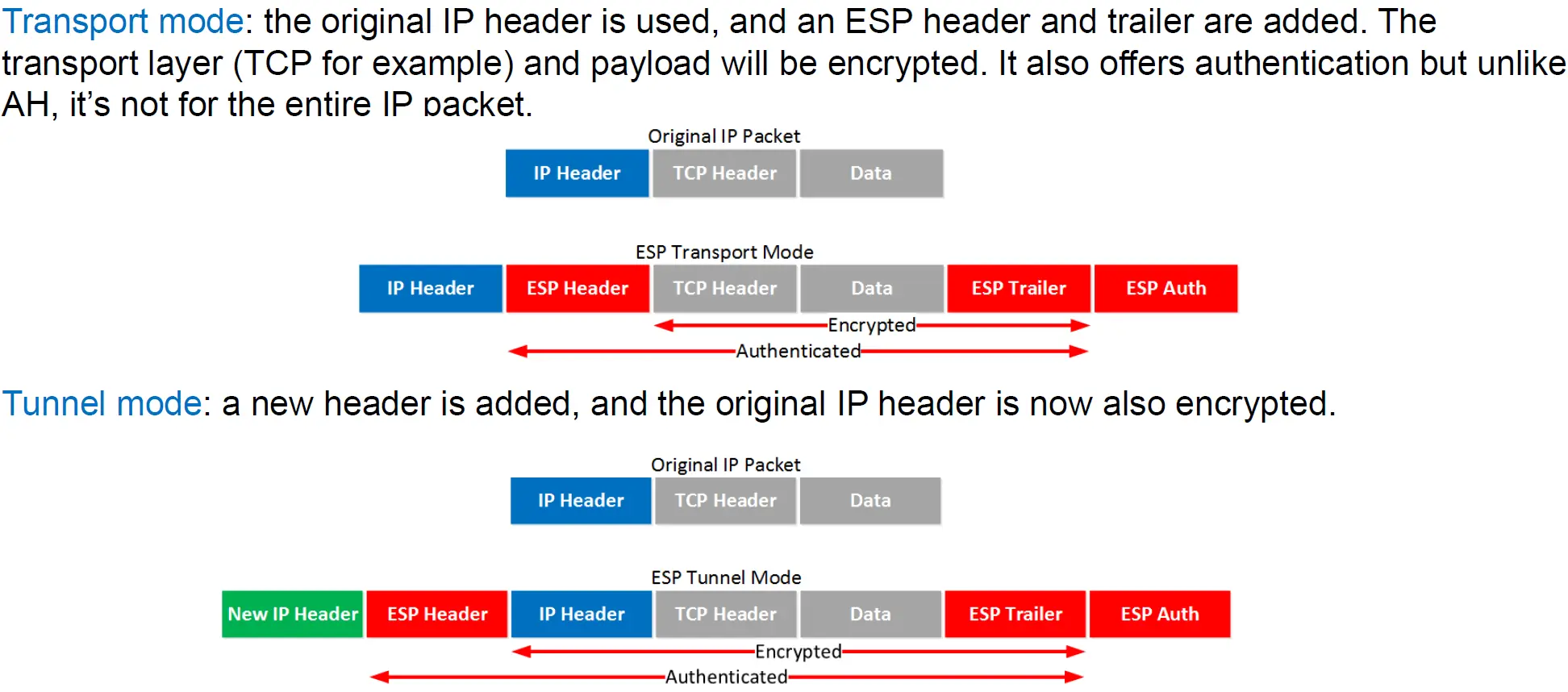 在AH和ESP混用的情况下,AH header会附在ESP header之前。
在AH和ESP混用的情况下,AH header会附在ESP header之前。 
What are the two types of VPNs?
两种类型虚拟专用网络(VPN)分别是什么?有什么区别?
虚拟专用网络主要有两种类型:站点对站点(Site-to-Site)VPN和远程访问(Remote-Access)VPN.
- 站点对站点(Site-to-Site)VPN:站点对站点VPN建立在两个或多个网络之间,允许这些网络之间的通信,通常是两个地理位置之间的网络。用于连接不同地点的企业网络,例如,连接公司总部和分支机构的网络,或者连接不同数据中心之间的网络。
- 远程访问(Remote-Access)VPN:远程访问VPN允许个人用户或远程办公者通过互联网安全地连接到私有网络,以便访问内部资源。常用于提供远程员工或移动用户安全地访问公司网络资源,例如文件、应用程序或内部网站等。
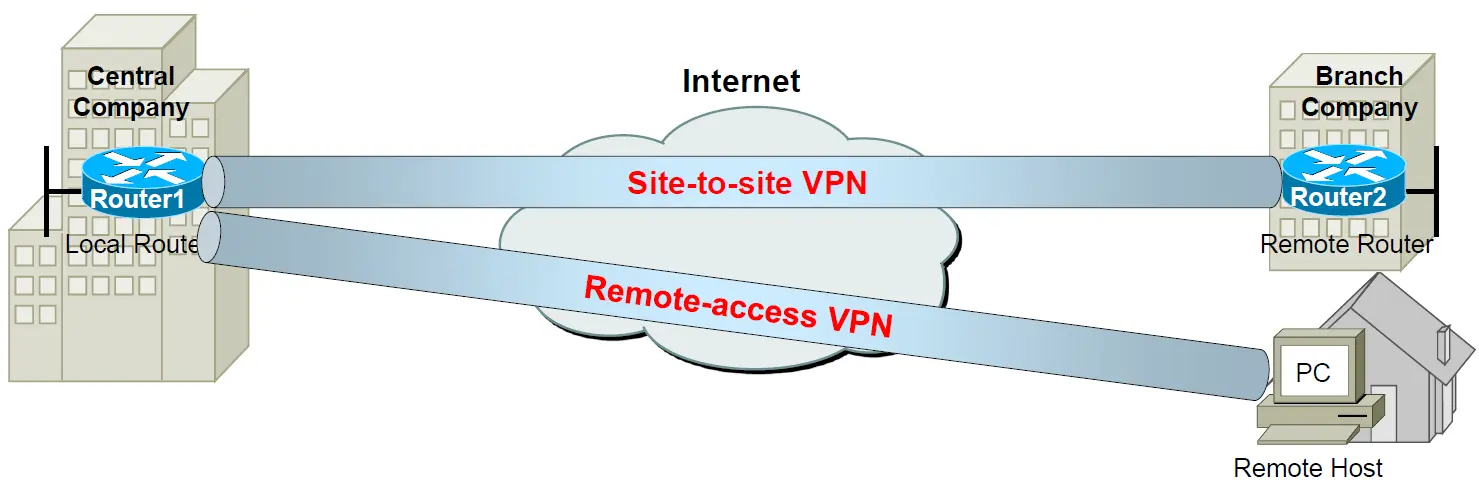 我们可以通过一个问题来理解不同VPN类型的区别并区分它们的地址。
我们可以通过一个问题来理解不同VPN类型的区别并区分它们的地址。
Exercise 8.1.
Q1. What type of VPN is used, if sending a packet from PC1 to PC2, PC1 to PC3, PC3 to PC2?
Q2. What addresses are used in outer header and inner header of the tunneled packet?
Q1. 如果从 PC1 向 PC2、PC1 向 PC3、PC3 向 PC2 发送数据包,它们分别使用哪种类型的VPN?
Q2. 上述连接中,隧道数据包的外层报头(outer header)和内层报头(inner header)分别使用了什么地址?
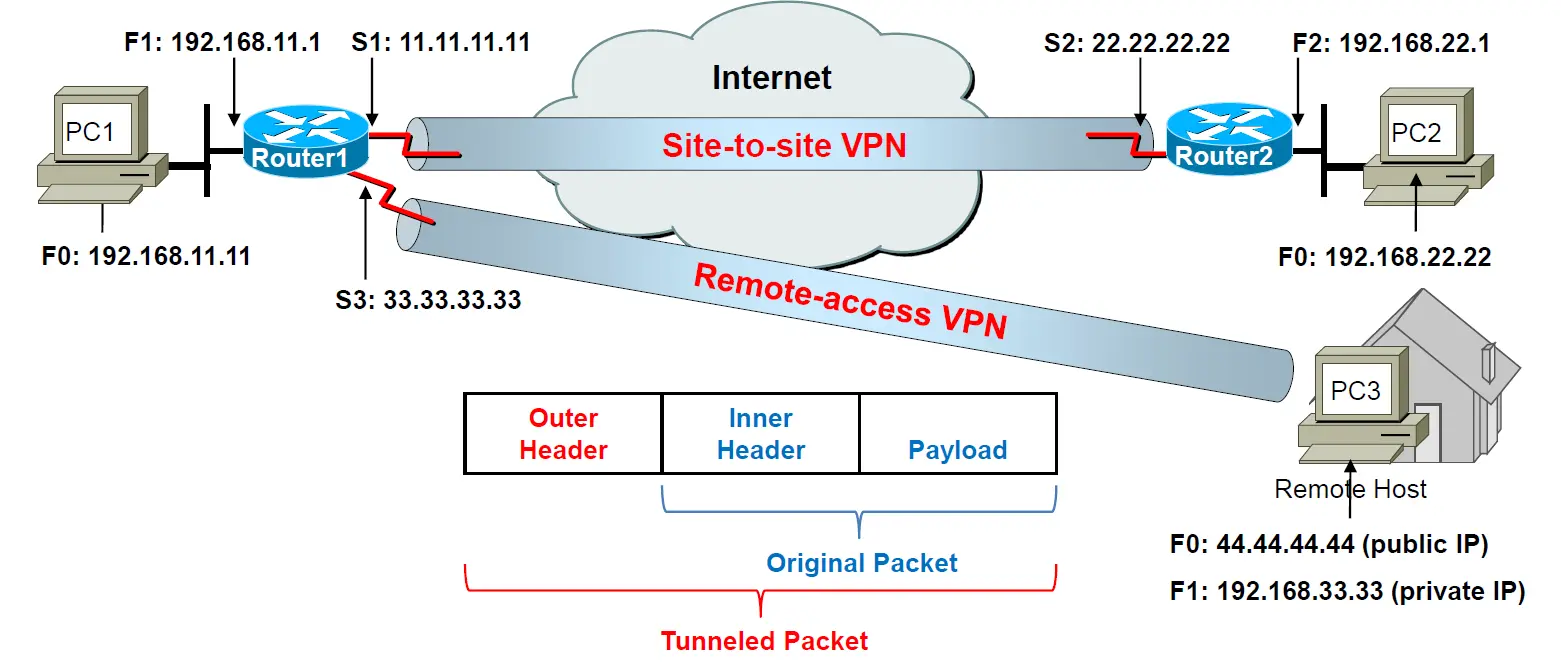
- Q1. PC1 -> PC2是两个网络之间的隧道连接,属于Site-to-site VPN;PC1 -> PC3是一个远端主机与一个网络之间的连接,属于Remote-access VPN;而PC3 -> PC2之间的连接会通过两个隧道连接,先是Remote-access VPN连接到网络1,再使用Site-to-site VPN连接到网络2.
- Q2.
- PC1 -> PC2的连接中,outer header包含了Site-to-site VPN隧道两端的端点IP,分别是11.11.11.11和22.22.22.22,而inner header则包含了数据包原始的源IP和目的IP,分别是192.168.11.11和192.168.22.22。
- PC1 -> PC3的连接中,outer header包含了网络1的隧道端点IP和远端主机的公共IP地址,分别为33.33.33.33和44.44.44.44,在隧道连接建立前,远端主机不存在源IP地址,在建立后网络1会为该主机分配一个私有的地址作为其内网IP,所以inner header包含了PC1的内网地址和PC3新分配的内网地址,分别为192.168.11.11,和192.168.33.33。
- PC3 -> PC2的连接中经历了两次隧道连接。第一次隧道连接中,是远端主机PC3与网络1的连接,参考PC1 -> PC3的连接,outer header包含44.44.44.44和33.33.33.33,inner header包含192.168.33.33和192.168.22.22.第二次隧道连接时网络1和网络2的隧道连接,参考PC1 -> PC2的连接,outer header被修改为11.11.11.11和22.22.22.22,而inner header因为源IP和目的IP地址没有改变而不变。最后的情况下,outer header包含11.11.11.11和22.22.22.22,inner header包含192.168.33.33和192.168.22.22。
What security are provided by VPN? What cryptography, hash and authentication algorithms are used in the VPN security?
VPN提供了哪些安全性措施?VPN安全性中使用了哪些加密、哈希(散列)和认证算法?
VPN为隧道传输提供了一些安全性措施,例如:
- 数据保密性 (Data confidentiality):在没有加密密钥的情况下无法解读捕获的数据包。这是由加密算法提供的,例如DES,3DES或AES。
- 数据完整性 (Data integrity):保证数据在传输过程中不会被修改。这是通过使用哈希算法提供的,例如MD5或SHA。
- 数据源认证 (Data origin authentication):证明数据是由授权用户访问的。这是通过认证算法提供的,例如PSK或RSA。
What is the process of creating an IPsec VPN?
建立一个IPsec VPN需要哪些过程?
IPsec VPN操作大致可以分成5个部分:
- 分流流量:当有需要通过IPsec进行安全传输的数据流量产生时,IPsec过程才被启动。
- 生成IKE SA:在第一阶段,对等方之间协商建立IKE SA,用于安全地交换后续阶段所需的密钥和参数的安全通道。IKE(Internet Key Exchange)是用于在IPsec对端之间协商密钥的协议。(第一层加密)
- 生成IPsec SA进行数据传输:在IKE第二阶段,通过IKE SA,通信节点协商IPsec策略,确定IPsec安全关联(IPsec SA)所需的安全参数,如加密算法、认证算法和密钥等。建立IPsec SA后,即可用于实际数据传输。(第二层加密)
- 数据传输:在建立了IPsec安全关联之后,数据传输过程开始。数据在IPsec通道上进行加密传输,并在传输过程中经过认证和完整性保护,以确保数据的安全性和完整性。
- 隧道终止:当数据传输结束或需要终止IPsec连接时,IPsec隧道被终止。在这一阶段,安全关联(SA)被关闭,IPsec通道被释放,以结束安全连接,停止数据传输。
What are the two phases of the Internet Key Exchange?
互联网密钥交换的两个阶段分别是什么?
阶段一是生成IKE SA,阶段二是生成IPsec SA。IKE Phase 1用于加密Phase 2的隧道信息。  在第一阶段中,常使用之前提过的加密算法(DES、3DES或AES),并使用哈希函数(MD5或SHA)用于保证数据完整性。在秘钥交换中,常使用Diffie Hellman组用于保证秘钥的安全。 Diffie-Hellman密钥交换是一种公开密钥密码学中的协议,用于安全地在两个通信方之间交换密钥,而不需要事先共享密钥。Diffie-Hellman交换的核心思想是使通信方能够协商共享的密钥,而不将密钥直接传输。它基于一个数学问题:离散对数问题。 下面是Diffie-Hellman密钥交换的基本步骤:
在第一阶段中,常使用之前提过的加密算法(DES、3DES或AES),并使用哈希函数(MD5或SHA)用于保证数据完整性。在秘钥交换中,常使用Diffie Hellman组用于保证秘钥的安全。 Diffie-Hellman密钥交换是一种公开密钥密码学中的协议,用于安全地在两个通信方之间交换密钥,而不需要事先共享密钥。Diffie-Hellman交换的核心思想是使通信方能够协商共享的密钥,而不将密钥直接传输。它基于一个数学问题:离散对数问题。 下面是Diffie-Hellman密钥交换的基本步骤:
- 参数选择:两个通信方共同选择两个素数
p和g。 - 公开参数:通信方将选定的
p和g的值公开传输给对方。 - 私密参数生成:每个通信方设置一个私钥
x1和x2。这些私密参数只有通信方自己知道,并且不会被传输到对方。 - 本地计算公钥:每个通信方使用自己的私钥和公开参数
p和g计算出一个本地的公钥y1和y2。 - 交换公钥:通信双方将本地计算得到的公钥发送给对方。
- 计算共享密钥:每个通信方使用收到的对方的公钥和自己的私密参数计算出共享的密钥。
如图展示这个过程中的计算: 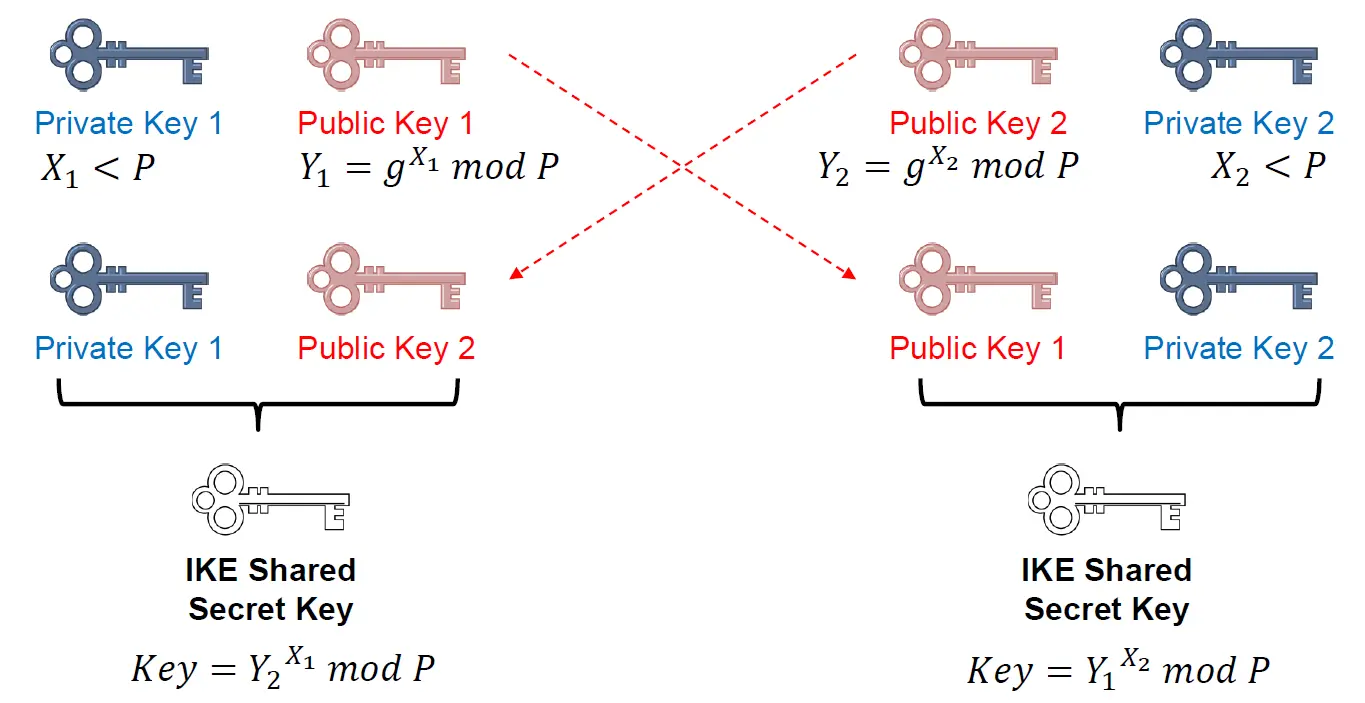 但这个加密方式可以通过中间人攻击(Man-in-the-middle attack)破解,故需要二阶段的加密。二阶段的加密比这个外层加密复杂得多。它可能使用基于TCP的连接,同时加入AH或ESP报头,并使用加密、完整性验证等方法提高数据的安全性。 下面通过一个例子来模拟Diffie-Hellman密钥交换的过程与验证。
但这个加密方式可以通过中间人攻击(Man-in-the-middle attack)破解,故需要二阶段的加密。二阶段的加密比这个外层加密复杂得多。它可能使用基于TCP的连接,同时加入AH或ESP报头,并使用加密、完整性验证等方法提高数据的安全性。 下面通过一个例子来模拟Diffie-Hellman密钥交换的过程与验证。
Exercise 8.2.
Based on the basic steps of Diffie-Hellman key exchange, set parametersp = 101,g = 9. If a client generates a private key ofX1 = 27, a public key ofY1 = 20, and the public key of the other side of the tunnel isY2 = 85, then what is the IKE shared key?
基于Diffie-Hellman密钥交换的基本步骤,设置参数p = 101,g = 9. 若一个客户端生成的私钥为X1 = 27,公钥为Y1 = 20,隧道另一方的公钥为Y2 = 85,则共享密钥是多少?
根据计算步骤,共享密钥的计算与另一端的公钥和自己的私钥有关,计算公式为:Key = Y2X1 mod p,带入计算得Key = 8527 mod 101。
访问控制
AAA框架
What is the three security features in AAA? What are the definitions and examples of Authentication, Authorization and Accounting?
AAA的三个安全特性是什么? Authentication,Authorization和Accounting的定义和例子是什么?
AAA是网络访问控制的一种安全管理框架,它决定哪些的用户能够访问网络,以及用户能够访问哪些资源或者得到哪些服务。AAA分别是:
- Authentication(认证):认证是确认用户身份的过程。用户提供凭据(如用户名和密码、数字证书等),网络系统使用这些凭据验证用户的身份,以确保只有合法的用户可以访问网络资源。用户访问指定的网络资源时,安全服务器会要求用户提供有效的用户名和密码,如果用户凭据匹配则允许用户访问,否则拒绝用户访问。
- Authorization(授权):授权确定了认证用户可以访问哪些资源的权限。一旦用户通过认证,系统会根据用户的身份和权限规则,决定其能够访问的特定资源或执行的操作。用户在访问网络资源时,只有部分的用户得到授权执行指定的命令,访问指定的内容。
- Accounting(计费):计费用来记录用户使用网络服务过程中的相关操作,简单说就是:什么人、什么时间、做了什么事。计费会统计标记时间内的系统事件,用于追踪与审计。
其中,Authorization(授权)必须要在Authentication(认证)后才能使用,而Authentication(认证)和Accounting(计费)均可以单独使用。Authentication(认证)和Authorization(授权)用于防止安全问题,而Accounting(计费)用于操作后的记录。
What are the two security protocols?
两种常见的安全协议是?
Security server 是一个用于管理和控制网络访问的关键组件,是运行了AAA框架的网络设备。 Security server一般使用具有认证和授权功能的应用层协议,例如RADIUS(远程身份验证拨号用户服务)和TACACS+(终端访问控制器访问控制系统)与各种网络设备进行通信。
- RADIUS(远程身份验证拨号用户服务):RADIUS是一种用于网络AAA的协议。当用户尝试访问网络资源时,客户端(如路由器、交换机)将用户的身份信息发送到RADIUS服务器进行验证。RADIUS服务器接收认证请求,验证用户身份,然后返回授权信息,允许或拒绝用户的访问请求。RADIUS使用UDP传输数据。
- TACACS+(终端访问控制器访问控制系统):TACACS+是另一种用于网络AAA的协议,它提供了比RADIUS更强大的功能。与RADIUS不同,TACACS+将认证和授权过程分开,因此提供了更高的灵活性和安全性。在TACACS+中,认证和授权请求发送到不同的服务器,因此可以单独管理和配置认证和授权策略。TACACS+还提供了更强大的日志记录和审计功能,可以记录更多详细的访问信息。TACACS+使用TCP传输数据。
在认证过程中,对于Security server而言,网络访问设备才是客户端(client),而不是终端用户。例如: 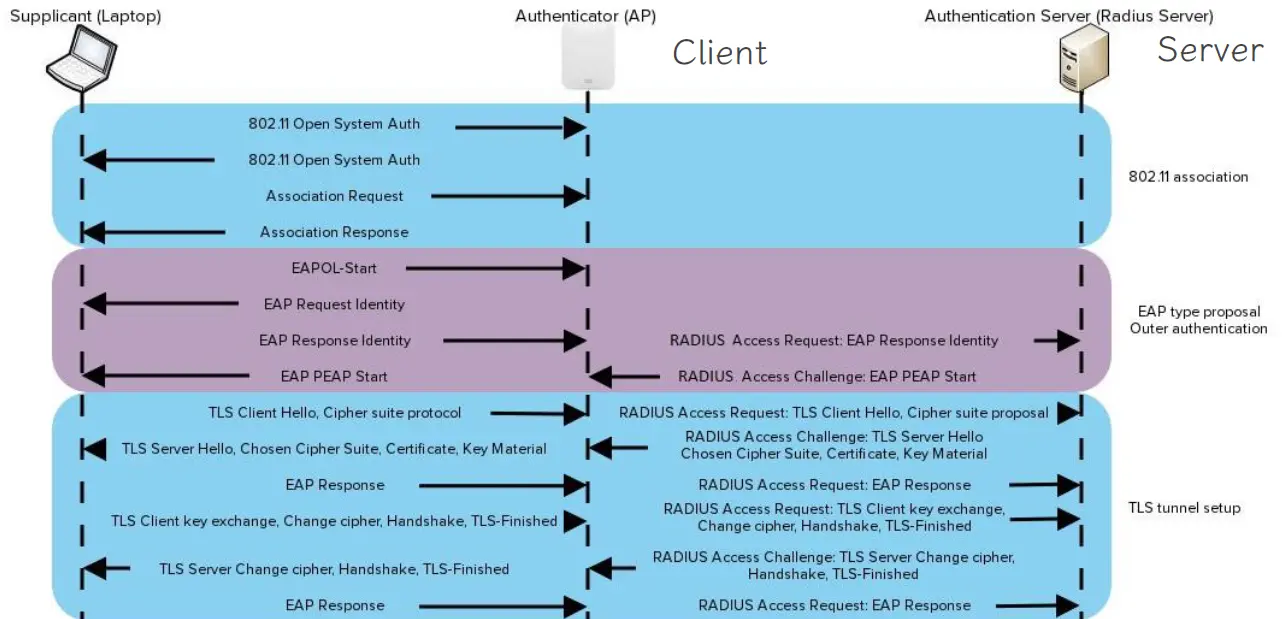
防火墙
What is the purpose of firewall? What security threats can be solved by using firewall?
防火墙的目的是什么?使用防火墙可以解决哪些安全威胁?
防火墙(Firewall)是一种网络安全设备,用于监控和控制网络流量,以保护内部网络免受未经授权的访问和恶意攻击。它控制了哪些信息允许进出网络。 防火墙用于解决未经授权的访问问题,保护网络资源。
What are the two types of firewalls?
两种类型的防火墙分别是?
防火墙可以基于不同的技术和工作原理进行分类,其中两种常见的类型是应用程序网关防火墙(Application Gateway Firewall)和数据包过滤防火墙(Packet Filtering Firewall)。
- 应用程序网关防火墙(Application Gateway Firewall):应用程序网关防火墙是一种工作在应用层的防火墙。它能够对传输层以上的数据进行深度分析(各层信息),包括对应用层协议(如HTTP、FTP、SMTP等)的理解和检查。
- 数据包过滤防火墙(Packet Filtering Firewall):数据包过滤防火墙是一种工作在网络层的防火墙。它基于预先配置的规则集对网络数据包进行过滤和处理,根据规则(ACLs)来允许或拒绝数据包的传输。数据包过滤防火墙可以根据源IP地址、目标IP地址、端口号等信息(第二第三层信息)对数据包进行过滤。这种防火墙通常比较简单、高效,并且对网络流量的处理速度比较快,适用于对网络层面的攻击进行防范。
对比起来可以发现,应用程序网关防火墙更安全,但是处理速度慢,而数据包过滤防火墙更简单,处理速度快。 我们一般称应用程序网关防火墙是有状态的防火墙(stateful),因为当有一个新的连接建立时,它会记录相关的连接信息,在接下来的数据包传输过程中,它会检查数据包是否与已经建立的连接状态匹配,并根据连接状态表中的信息决定是否允许数据包通过,我们称为两次连接。
而数据包过滤防火墙是无状态的防火墙(stateless),它在处理每个数据包时,并不会考虑其是否属于已经建立的连接,仅关注于数据包本身,我们称为一次连接。 应用程序网关防火墙一般部署在外部路由器(exterior router)和内部路由器(interior router)之间。外部路由器连接到Internet,内部路由器连接到内部网络,且只接受来自应用网关的数据包。数据包过滤防火墙一般可以部署在两端路由器上。 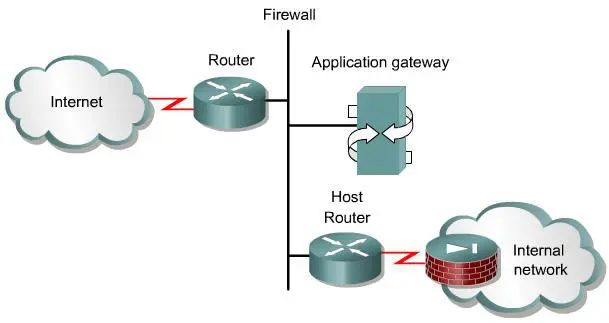
ACL
What is the structure of statements in ACLs? How can ACLs use the conditions to filter the traffic?
ACL 中的语句结构是什么?ACL 如何使用条件过滤流量?
ACL包括permit和deny两种动作,ACL中至少应该有一个permit语句。ACL的语句结构例如:
{permit | deny} {Source subnet/IP} {Destination subnet/IP}
{permit | deny} {Source subnet/IP} {Destination subnet/IP}
...
deny anyACL是顺序匹配,如果匹配成功了,后续的条目将直接跳过。在配置列表的末尾有一个隐式的deny any,表示不符合之前ACL规则的全部deny。
How inbound ACLs and outbound ACLs filter the traffic coming or leaving the router interfaces?
入站ACL和出站ACL如何过滤进入或离开路由器接口的流量?
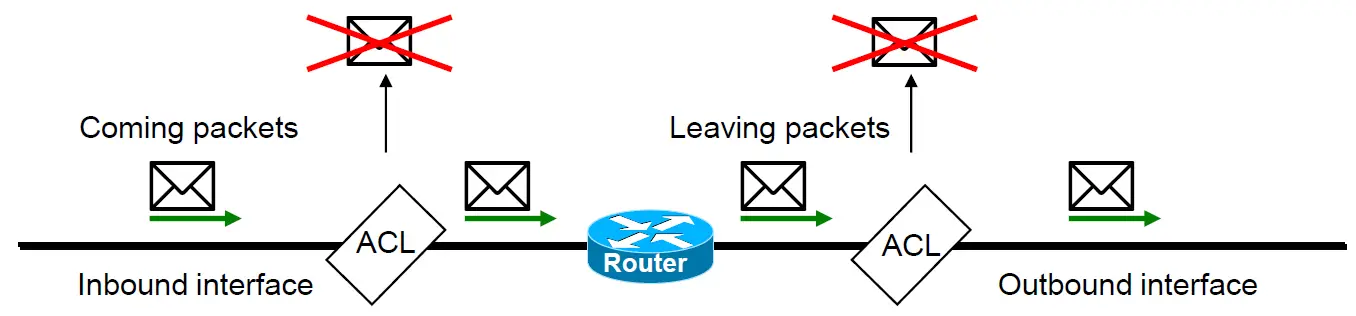
对于一个路由器而言,ACL是应用于端口上的。
- 当数据包进入接口时,如果路由器在入站(inbound)接口上具有ACL,则在数据包进入接口之前,将根据ACL中的条件对数据包进行测试。
- 当数据包离开接口时,如果路由器在出站(outbound)接口上有ACL,则在数据包离开接口之前,将根据ACL中的条件对数据包进行测试。
How to use the IP address and wildcard mask to define a group of hosts? 如何使用IP地址和通配符掩码来定义一组主机?
ACL中使用通配符掩码(Wildcard masks)来定义一组主机。通配符掩码符合:
- 与IPv4结构相同,一共32位,分成四个部分,每个部分8位。
- 0表示的位表示需要进行IP匹配。
- 1表示的位表示忽略IP匹配。
- 全部位数都不需要匹配的IP,用
any表示。 - 全部位数都需要匹配的IP用
host ip表示。
下面是一个使用IP地址和通配符掩码定义一组主机的例子: 匹配172.16.0.0/16子网中的所有单数主机(尾部为1):即前16位固定(同一子网),最后一位固定(单数),其他位忽略。
IP: 172.16.0.0
Wildcard Mask: 00000000.00000000.11111111.11111110 or 0.0.255.254下面是使用防火墙和ACL规则的一些例题。
Exercise 9.1
Q1. How to define the servers and the hosts using IP address and wildcard mask?
Q2. If an ACL denies the hosts from Internet to access the FTP server, which interface to assign this ACL and in what direction, inbound or outbound?
Q1. 如何使用IP地址和通配符掩码定义服务器和主机?
Q2. 如果ACL禁止来自Internet的主机访问FTP服务器,应将此ACL分配给哪个接口,以及是入站还是出站?
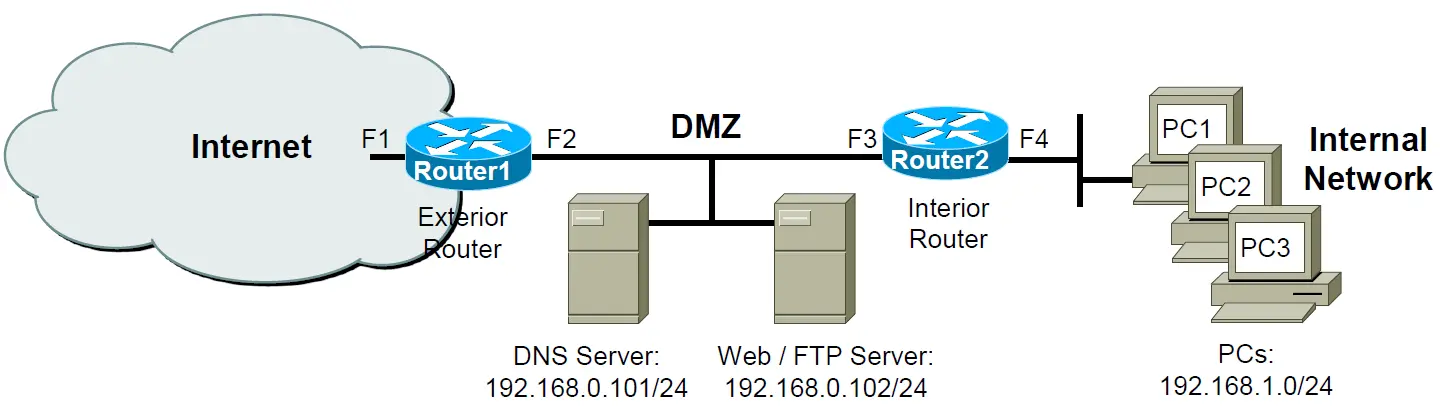 如图所示:
如图所示:
- Q1. 图中的子网192.168.1.0/24根据IP地址和通配符掩码规则可以定义为:
IP: 192.168.1.0 Wildcard Mask: 0.0.0.255DNS服务器可以定义为:
IP: 192.168.0.101 Wildcard Mask: 0.0.0.0 or host 192.168.0.101WEB/FTP服务器可以定义为:
IP: 192.168.0.102 Wildcard Mask: 0.0.0.0 or host 192.168.0.102 - Q2. 如果ACL禁止来自Internet的主机访问位于DMZ中的FTP服务器,那就应该将ACL规则部署与Exterior Router 1的F1接口上,阻止来自互联网的FTP访问请求,ACL设置为入站 (Inbound).
Exercise 9.2
Q1. 请使用IP地址和通配符掩码定义两个子网。
Q2. 阅读如下配置在Port3的outbound ACL配置,根据ACL规则的判断是否能访问。permit subnet1 server1 deny subnet1 server2 permit subnet2 server2 permit subnet1 ALL-server deny ALL-host ALL-server
- Subnet2 -> Server1
- Subnet1 -> Server2
- Subnet2 -> Server3
Q3. 除了Port3外,这个ACL规则还能放在哪?
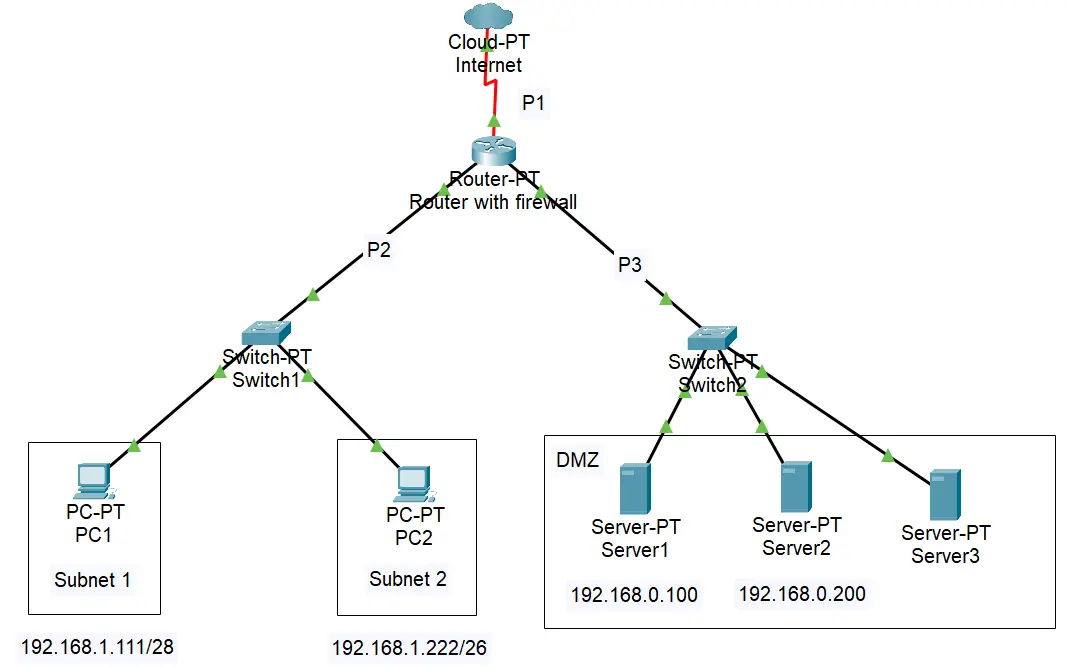
- Q1.
子网1:IP: 192.168.1.96 Wildcard mask: 0.0.0.15子网2:
IP: 192.168.1.192 Wildcard mask: 0.0.0.63注意此时显示的为一个主机的地址,并非当前子网的地址,所以需要重新计算其子网的IP地址。
- Q2. 根据ACL规则翻译:
- 允许子网1访问服务器1
- 禁止子网1访问服务器2
- 允许子网2访问服务器2
- 允许子网1访问所有服务器
- 拒绝所有主机访问所有服务器
并且根据ACL顺序规则,我们判断:
- Subnet2 -> Server1:不允许,匹配第5条。
- Subnet1 -> Server3:允许,匹配第4条。
- Subnet2 -> Server3:不允许,匹配第5条。
- Q3. 这条ACL主要是防止我们的内网访问服务器的规则,除了Port3外,我们还可以设置在Port2的入站(inbound)上,在请求入站时就进行拦截。
流量控制
流量整形
What is the difference between traffic policing and traffic sharping?
流量限速(Traffic Policing)与流量整形(Traffic Shaping)有什么不同?
流量限速(Traffic Policing)是一种确保没有流量超过配置的最大速率的方法,当流量速率达到配置的最大速率时,将会直接丢弃或标记超出部分的数据包,其流量图表现为锯齿状。 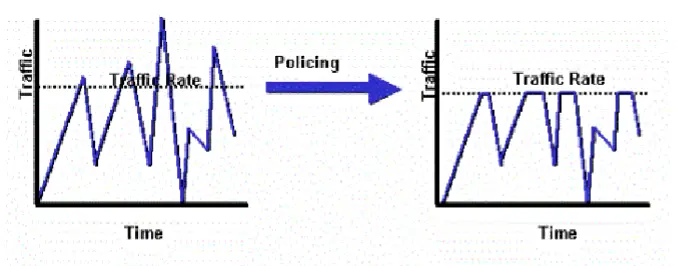 而流量整形(Traffic Shaping)使用缓冲队列来延迟数据包传输,将突发流量转换为平滑流量。它可以防止数据包丢失,使得流量图呈现得更平滑。
而流量整形(Traffic Shaping)使用缓冲队列来延迟数据包传输,将突发流量转换为平滑流量。它可以防止数据包丢失,使得流量图呈现得更平滑。 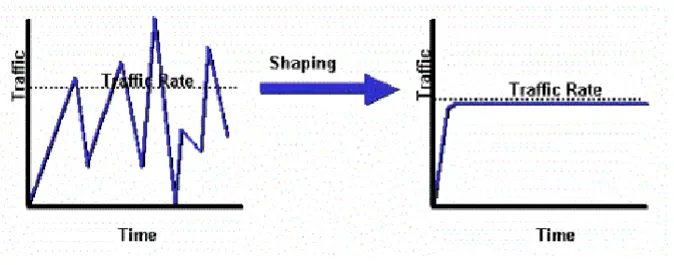
What are the leaky bucket and token bucket algorithm? How can this shaper control the traffic?
漏桶算法和令牌桶算法是什么?它们是如何控制流量?
漏桶算法 (Leaky bucket algorithm)将所有进入网络的数据包都放入一个固定容量的桶(先进先出队列)中,数据包会以恒定的速率从桶的底部漏出,相当于一个漏斗。如果桶已满,则不能接受新的数据包,可能导致数据包的丢失。如图是一个漏桶的例子,其中桶的总大小为s (size),已经存在的数据包突发量为b,桶的平均泄露率为Pout。漏桶算法以一个恒定的速率发送数据。 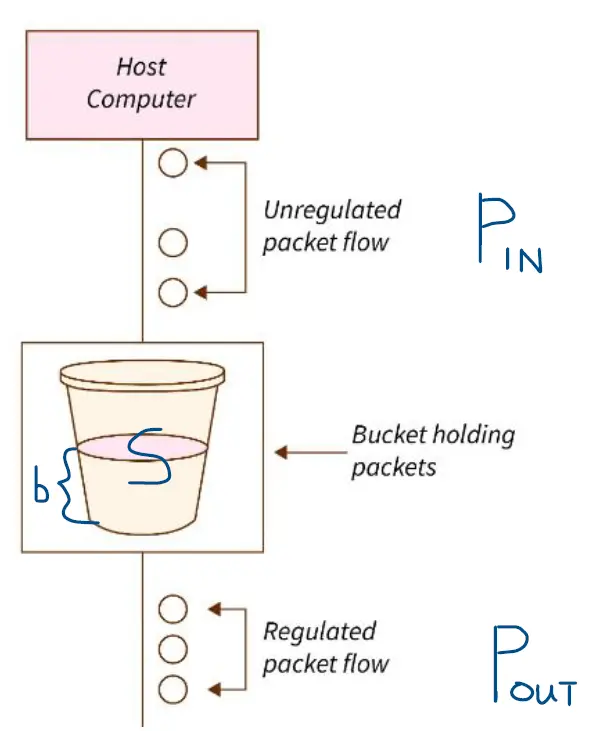 当桶没有满时,即
当桶没有满时,即b < s,此时若想不丢包,理论上桶的最大进入速率Pin = (s-b)/t + Pout。因为在特定的时间内(t),桶内能够额外接受的数据量,同时再加上桶本身的泄露率Pout,它表示了在不超过桶的总容量(s)的情况下,桶短时间内能够处理的最大输入速率。 我们通过一个例子来理解漏桶算法的基本过程:
Suppose,the buffer size = 10000 Mb , leak rate = 1000 Mb/s. Assume at some point the packets are thrown into the bucket as [200,500,400,500,200]. Now, in each iteration (per second), how to transfer the packets such that the sum of the size of each packet is not greater than the leak rate?
假设缓冲区大小 = 10000 Mb,泄漏率 = 1000 Mb/s。在某一点,数据包被投入桶中为[200,500,400,500,200]。在每次迭代(每秒)中,如何传输数据包,使得每个数据包的大小之和不大于泄漏率?
根据题目内容已知Pout = 1000 Mb/s, s=10000Mb,初始情况下,桶为空,b = 0。故在每次迭代中,传输的数据包如下(不能部分传输数据包):
- 传输200,500
- 传输400,500
- 传输200
而令牌桶(Token bucket)与漏桶的不一样,它是一个以限制的速率发送数据。令牌桶算法发送数据包时需要消耗令牌(token),每发送一个数据包就从桶中移走一定数量的令牌。只有当桶中有足够的令牌时,才允许数据包通过桶。 如图,其中桶的大小为b,令牌生成速度为r,桶如果满了,新令牌就会被丢弃。如果桶中令牌不足,那么数据包需要等待直到有足够的令牌。 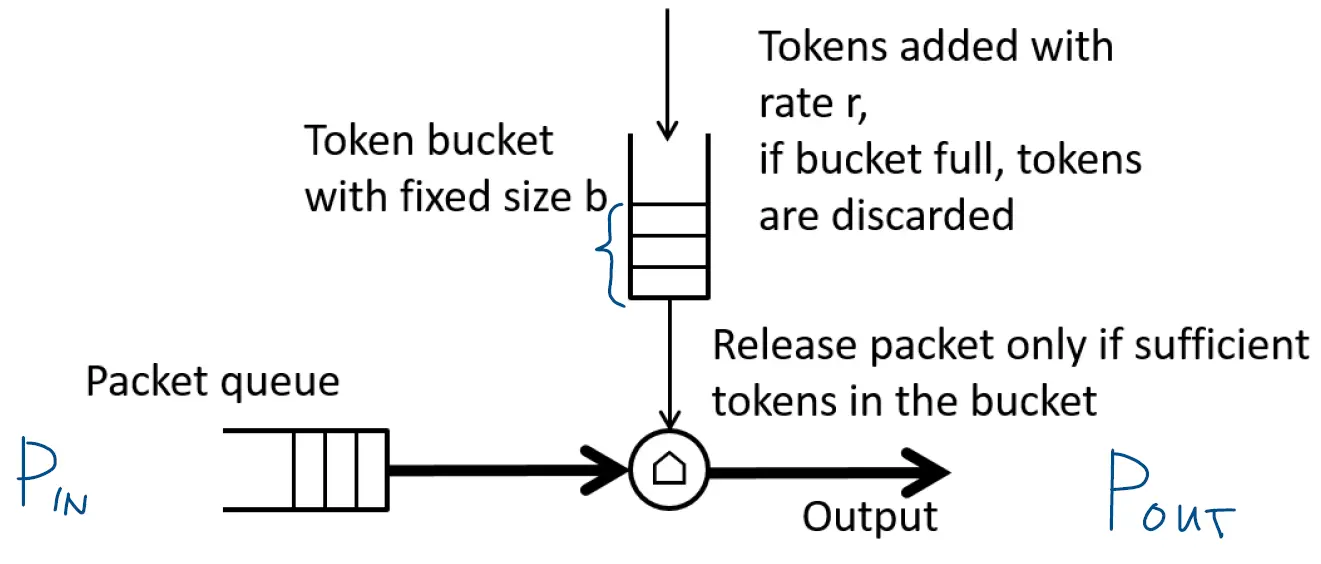 若在t1时间内达到令牌桶的上限,令牌消耗的最大数量为
若在t1时间内达到令牌桶的上限,令牌消耗的最大数量为o1 = p1t1 = b+rt1,p1=(b+rt1)/t1。在t2(t2>t1)时间内,超出令牌生成的部分数据包将会以均匀的令牌生成速度r传输,即在t2时间内传输的最大数据为o2 = p1t1 + r(t2 - t1) 。在t1时间内,数据包的传输不会超过令牌数,此时传输速率Pin = Pout,在此之后,Pout = r。 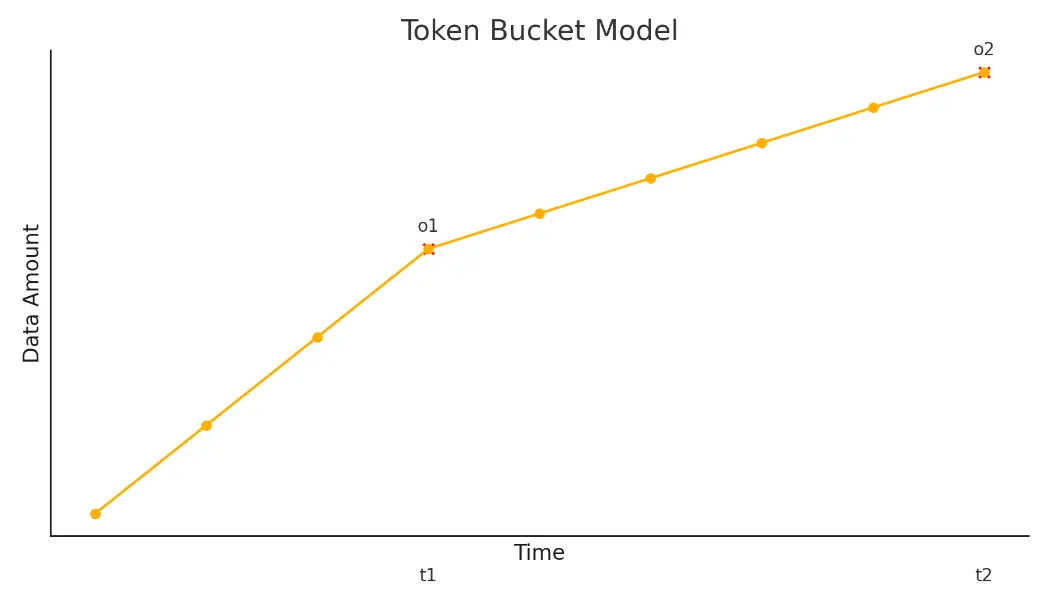 下面是一个令牌桶应用的例子:
下面是一个令牌桶应用的例子:
Exercise 10.1
A token bucket traffic shaper: Token generator with rate r = 4 (byte/s), and Token bucket size b = 8 (byte). The output rate R (byte/s). The token bucket starts out full with b tokens.
Q1. If the interval T1 = 1 s, what is the maximum of R within this interval?
Q2. If the input rate of packets P = 12 (byte/s), what is the maximum amount of traffic can be sent before the interval T2 = 2 s?
Q3. If P = 20 (byte/s), what is the maximum amount of traffic can be sent before the interval T2 = 2 s?
假设,令牌生成器的速率r = 4 (字节/秒),令牌桶的大小b = 8 (字节)。输出速率R (字节/秒)。令牌桶开始时满的,有b个令牌。
Q1. 如果间隔T1 = 1 s,那么在这个间隔内R的最大值是多少?
Q2. 如果数据包的输入速率P = 12 (字节/秒),那么在间隔T2 = 2 s之前,可以发送的最大流量是多少?
Q3. 如果P = 20 (字节/秒),那么在间隔T2 = 2 s之前,可以发送的最大流量是多少?
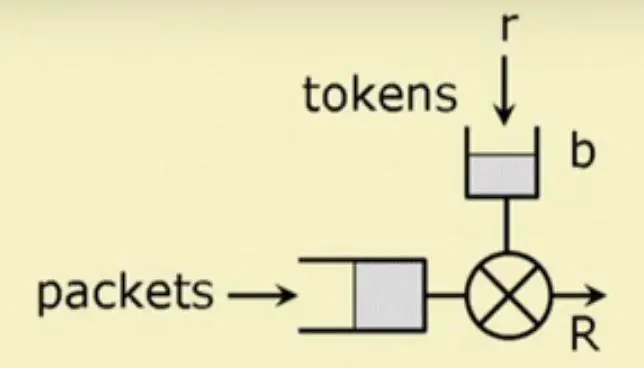
- Q1. R表示离开令牌桶时的传输速率,根据令牌桶模型的速率变化图,在T1 = 1s内最大的输出速率
R = (b+rT1) / T1 = 12 byte/s. - Q2. 若
P = 12 byte/s = Rmax,则说明其在T1 = 1s内保持最大输出速率,在T1~T2 s内保持平均速率r,则最后最大发送的流量为o = b + rT_1 + r(T2 - T1) = 16 bytes. 此时的平均速率为R' = o / T2 = 8 byte/s - Q3. 若
P = 20 byte/s > Rmax,则此时速率会被令牌桶限制,最大传输的流量也为16 bytes.
流量排队
What is the difference between the hardware queuing and software queuing?
硬件排队与软件排队有什么不同?
流量排队(Traffic Queuing)是网络中一种典型的现象,当网络中的数据包到达的速度超过了网络设备处理它们的速度时,这些数据包就会在设备的缓冲区中排队等待处理。排队算法是配置在网络设备上用于处理拥堵期间数据包调度问题的方法,它使得关键任务和延迟敏感的流量优先发送出去。流量排队可以分为硬件排队(hardware queuing)和软件排队(software queuing)。
- 硬件排队(hardware queuing),通常发生在物理设备中,如网络路由器或交换机。这些设备有专门的硬件资源(如缓冲器 buffer)用于存储和管理待处理的数据包。由于硬件排队直接在物理设备中进行,它通常能提供更高的处理速度和更低的延迟。然而,硬件排队的策略和容量通常由设备的物理设计确定,不易进行修改或优化。硬件排队又被称为缓冲(Buffering)。
- 软件排队(software queuing)则发生在计算机的操作系统或应用程序中。在软件排队中,数据被存储在计算机的内存中,并由软件优先级排序算法进行管理和调度。与硬件排队相比,软件排队具有更高的灵活性,可以根据需要调整排队策略和容量。但是由于软件排队需要计算机的处理器和内存资源,其性能可能受到这些资源的限制。软件排队又被称为重新排序(Re-order)。
通常情况下,硬件排队和软件排队是同时存在的。首先由软件排队将数据包重新排序后,再存储到计算机的缓存区中,如图: 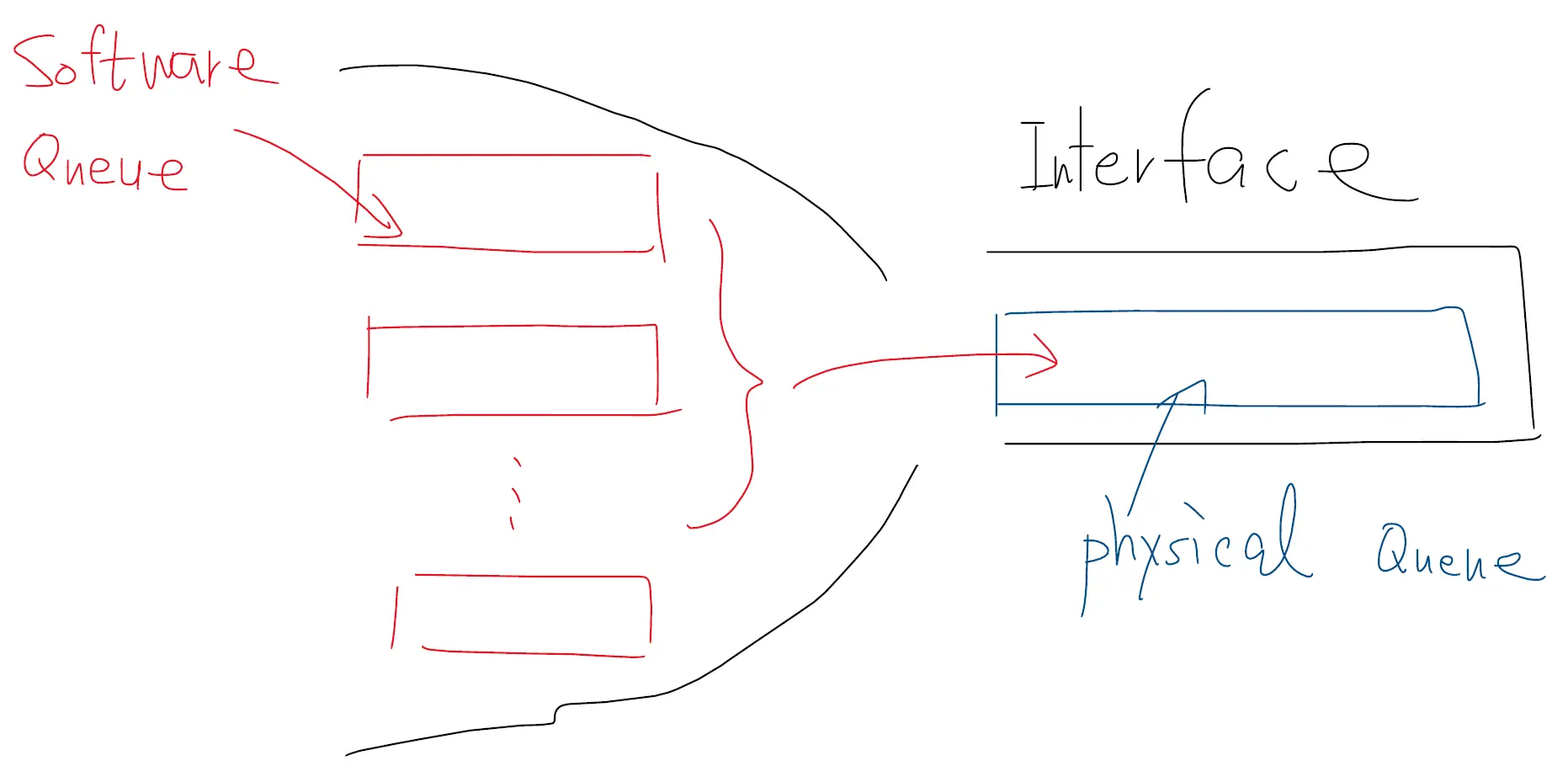
How many queuing methods, and what are the names and algorithm of them?
有多少种排队方法,它们的名称和算法是什么?
常见的排队方法有:
- FIFO(First In, First Out):FIFO 是最简单和最常见的排队方法之一。它按照数据包到达的顺序将它们存储在队列中,并按照它们到达的顺序将它们发送出去。但可能导致某些数据包在队列中长时间等待,从而增加延迟。
- WFQ(Weighted Fair Queuing):WFQ 是一种公平的排队方法,它根据数据包的流量和服务质量要求来分配带宽和优先级。它为每个数据流分配一个权重,以确保每个流都能公平地共享网络资源。WFQ 在多流量情况下能够提供较好的性能,但实现起来相对复杂。
- PQ(Priority Queuing):PQ 是一种优先级排队方法,它将数据包划分为多个优先级队列,并按照优先级顺序发送数据包。具有高优先级的队列中的数据包将优先于低优先级队列中的数据包进行发送。PQ 可以确保重要的数据优先被传输,但可能导致低优先级数据包被长时间阻塞,产生延迟。
- CQ(Custom Queuing):CQ是FIFO和PQ的结合。自定义队列CQ保证了关键任务数据始终被分配一定的带宽比例,但也确保了其他流量的可预测吞吐量。
我们主要关注PQ和WFQ的过程。 对于优先级排队(PQ),首先需要对流量中的数据包按照一些标准分类,并将他们分配给四个输出队列中:它们分别代表High, Medium, Normal, Low的优先级。当网络设备准备好发送数据包时,它首先检查优先级高的队列。一旦高优先级队列为空,网络设备就检查中优先级队列,依此类推,这个过程(从高优先级队列开始)在网络设备每次准备发送数据包时重复进行。它的过程如图所示: 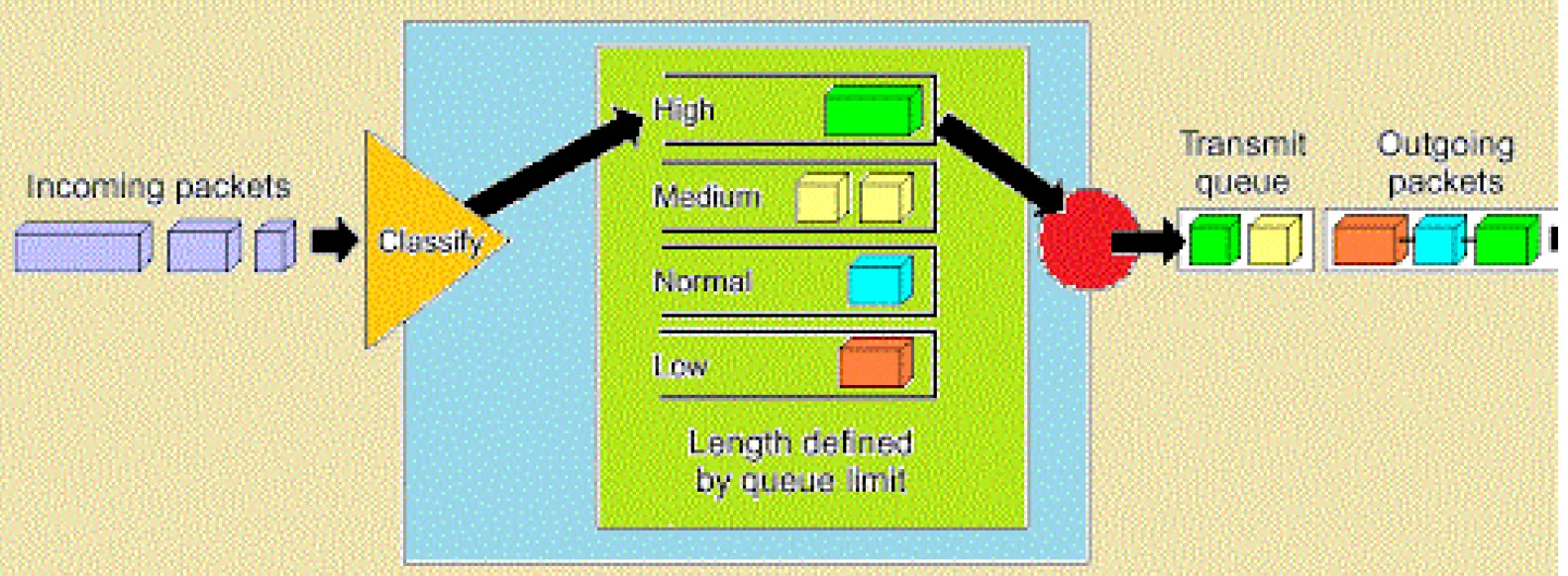 对于加权公平排队 (WFQ),它为每个流量类别分配一个权重,然后根据这些权重公平地处理数据包。具有较高权重的流量类别将获得更多的处理时间,而具有较低权重的流量类别将获得较少的处理时间。简单来说就是:各个队列根据其权重获得不同的服务比例。更高权重的队列可以发送更多的数据,即使在网络拥塞的情况下也保证了带宽的分配。我们通过一个例子来理解这个排队算法的过程: 如图所示的分组和权重分布,有17个数据包等待发送。
对于加权公平排队 (WFQ),它为每个流量类别分配一个权重,然后根据这些权重公平地处理数据包。具有较高权重的流量类别将获得更多的处理时间,而具有较低权重的流量类别将获得较少的处理时间。简单来说就是:各个队列根据其权重获得不同的服务比例。更高权重的队列可以发送更多的数据,即使在网络拥塞的情况下也保证了带宽的分配。我们通过一个例子来理解这个排队算法的过程: 如图所示的分组和权重分布,有17个数据包等待发送。 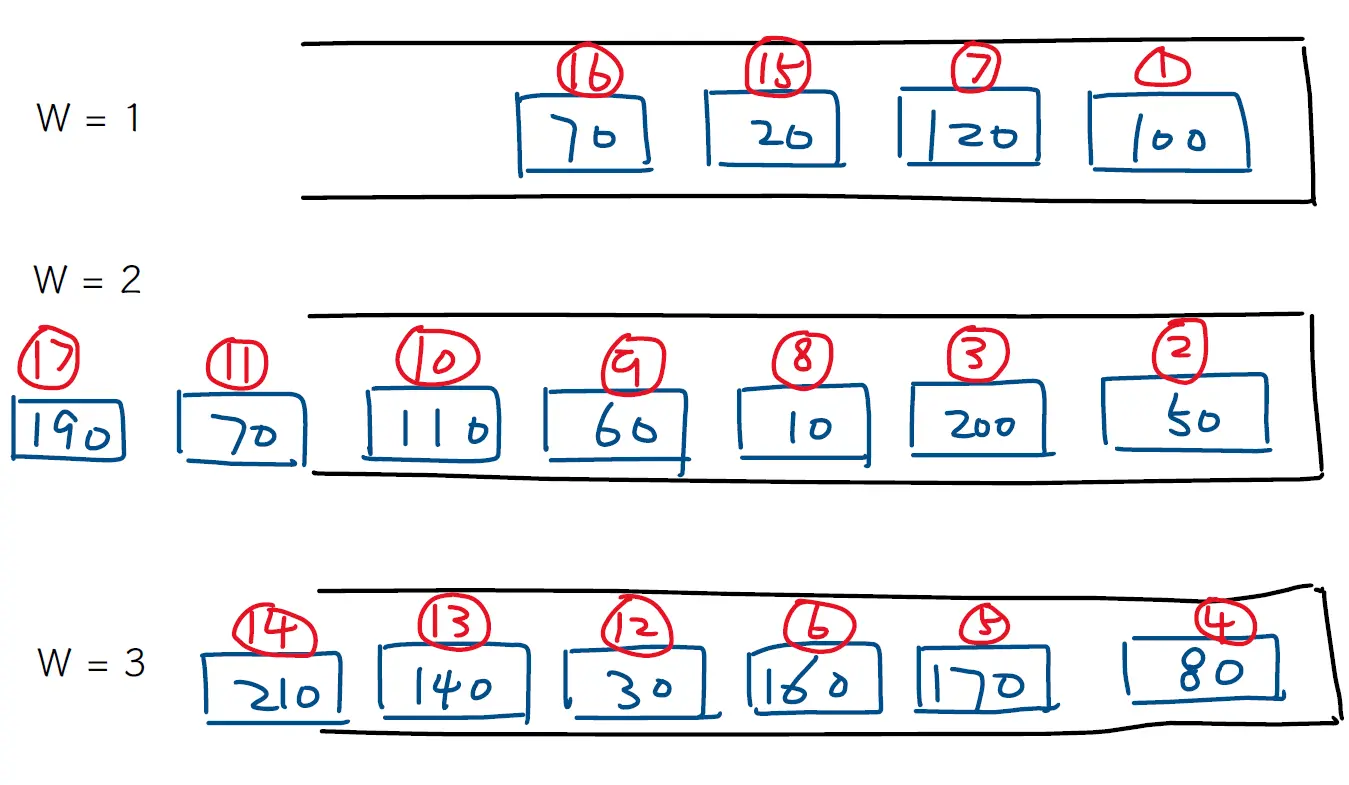 在一个调度周期中,这些队列分别可以发送的数据包大小比例为1:2:3。假设一个周期内可以发送的数据包没有限制,则权重为1的队列每次发送1个数据包,数据包的大小为
在一个调度周期中,这些队列分别可以发送的数据包大小比例为1:2:3。假设一个周期内可以发送的数据包没有限制,则权重为1的队列每次发送1个数据包,数据包的大小为k bytes,那么权重为2的队列则可以发送2k bytes,权重为3的队列则可以发送3k bytes,这个过程确保了每个队列都能根据其权重公平地获得带宽。
- 我们首先选取权重小的作为开始,首先发送数据包1,大小为100 bytes(之后省略单位),此时Counter1 = 100. 此时对于W=2的队列, 它可以发送200的数据,此时发送数据包2和3,大小为250,达到限制大小200. 对于W=3的队列,它可以发送300的数据,于是发送数据包4,5,6,大小为410,达到限制大小300。 此时的Counter情况如下:
Counter1: 100 Counter2: 250 Counter3: 410 - 接下来继续发送权重小的,数据包7,大小为120,Counter1为220. 对于W=2的队列,限制大小为440大于Counter2,则可以继续发送数据包8,9,10,11达到500. 对于W=3的队列,可以发送660的数据,于是发送13,14,达到760. 此时的Counter情况如下:
Counter1: 100 + 120 = 220 Counter2: 250 + 250 = 500 Counter3: 410 + 380 = 760 - 接着下一个调度周期,发送数据包15,Counter1为240. 而
Counter2 * 2 > Counter1,W=3的队列已全部发送,故此次没有其他数据包发送。此时的Counter情况如下:Counter1: 100 + 120 + 20 = 240 Counter2: 250 + 250 = 500 Counter3: 410 + 380 = 760 - 下一个周期中,发送数据包16,Counter1为310,对于W=2的队列,可以发送的数据为620 > Counter2,故可以继续发送数据包17,达到690. 此时的Counter情况如下:
Counter1: 100 + 120 + 20 + 70 = 310 Counter2: 250 + 250 + 190 = 690 Counter3: 410 + 380 = 760 - 最后,所有的数据包发送完毕。
整个过程中,数据包发送的顺序为:
1,2,3,4,...,17我们通过下面的一个例题来理解这些软件排队算法是如何重新排列数据包发送顺序的。
Exercise 10.2
The receiving order of each packet is listed in the queues, what is the sending order of the packets after re-scheduled by the FIFO, PQ, WFQ queuing?
队列中列出了每个数据包的接收顺序,那么通过 FIFO、PQ、WFQ 队列重新排序后,数据包的发送顺序是什么?
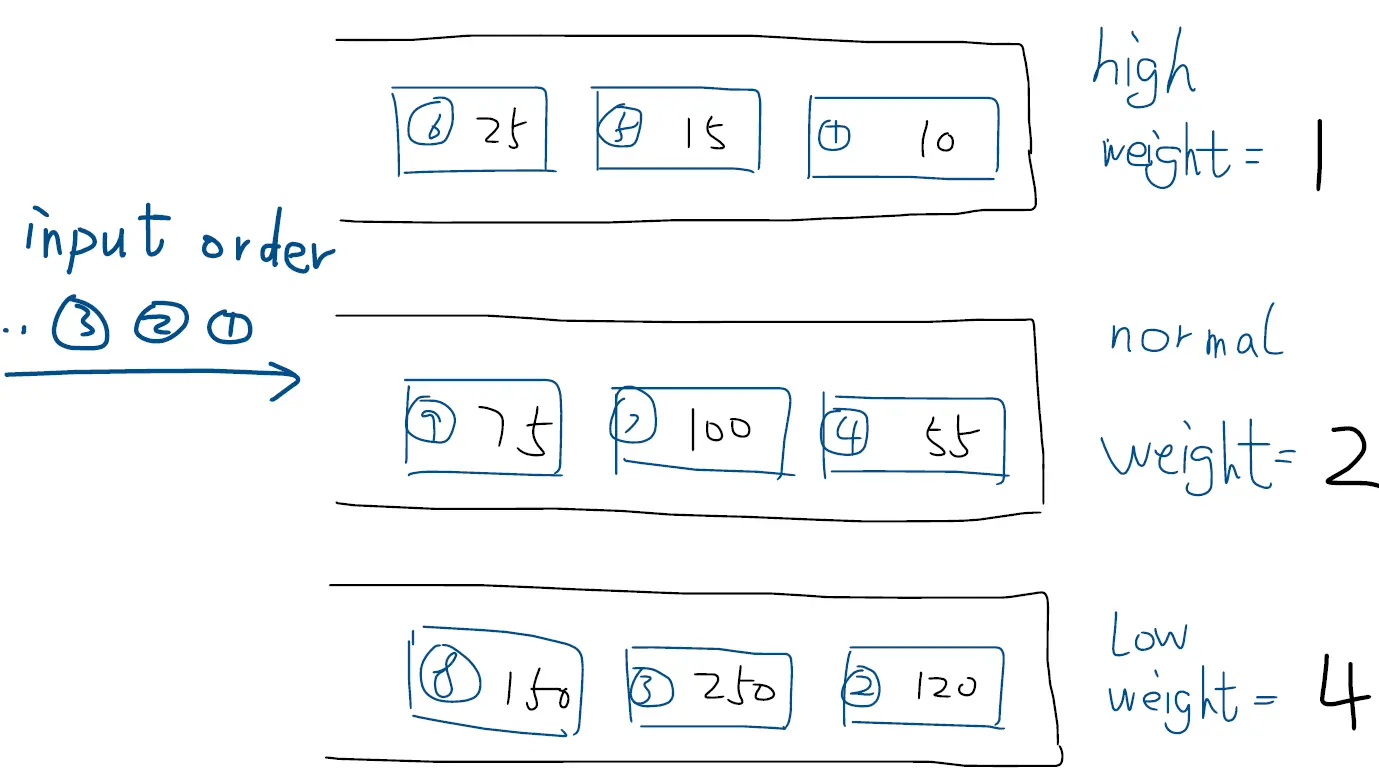 对于FIFO,它不会修改数据包的顺序,因为根据先进先出原则,它会按照接受顺序依次发送,故它的发送顺序是:
对于FIFO,它不会修改数据包的顺序,因为根据先进先出原则,它会按照接受顺序依次发送,故它的发送顺序是:
1,2,3,4,...,9对于PQ,它是根据队列的优先级发送数据包,根据图中已经提供的分组,我们可以很快的得到发送的顺序按照优先级为:
1,5,6,4,7,9,2,3,8对于WFQ,它是根据权重来决定每个调度单位时间内发送数据包的大小(而非数量)。我们一步步来看这个过程: 首先我们认为每一个队列的所能发送数据包的速率是相同的,此时一般从权重小的开始计算起。
- 在W=1的队列中,我们发送第一个数据包,大小为10 bytes。此时对于W=2的队列,它则可以发送大小为2 * 10 = 20 bytes的数据。不过当前W=2的队列还没有发送过(Counter2 = 0),于是可以尝试发送第4个数据包,大小为55 bytes,它大于了前面的限制20 bytes,于是发送完这个数据包后它就不能继续发了。同理的,对于W=4的队列,它可以发送大小为40 bytes的数据,但是此前还没有发送过数据(Counter3 = 0),于是可以尝试发送数据包2,大小为120 bytes,也超过了前面的限制,于是发送完这个数据包后它就不能继续发了。当前每个队列中的counter如下:
Counter1: 10 Counter2: 55 Counter3: 120 - 在第二个调度周期中,在W=1的队列中我们可以继续发送数据包5,大小为15 bytes。此时
Counter1=10+15=25 bytes,这W=2的队列可以发送50 bytes, W=4的队列可以发送100 bytes的数据。但是在这一周期中,Counter12 < Counter2,Counter1 4 < Counter3,W=2和W=4的队列均不能继续发送(保证公平)。此时Counter的情况:Counter1: 10 + 15 = 25 Counter2: 55 + 0 Counter3: 120 + 0 - 在第三个调度周期中,在W=1的队列中我们可以继续发送数据包6,大小为25 bytes,此时
Counter1=10+15+25=50 bytes。对于W=2的队列,它可以发送100 bytes的数据,它大于当前的Counter2,故可以继续发送数据包7。同理,对于W=4的队列,它可以发送200 bytes的数据,它大于当前的Counter3,故可以继续发送数据包3。此时Counter的情况:Counter1: 10 + 15 + 25 = 50 Counter2: 55 + 0 + 100 = 155 Counter3: 120 + 0 + 250 = 370 - 在第四个调度周期中,W=1的队列已经全部发送完毕,就从W=2的队列开始发送。此时没有了之前的限制,可以发送数据包9,Counter2则等于
55+0+100+75=230 bytes。对于W=4的队列,此时它可以发送460 bytes的数据,于是它发送数据包8,最后的Counter情况如下:Counter1: 10 + 15 + 25 = 50 Counter2: 55 + 0 + 100 + 75 = 230 Counter3: 120 + 0 + 250 + 150 = 520 - 最后,所有的数据包发送完毕。
整个过程中,数据包发送的顺序为:
1,4,2,5,6,7,3,9,8总结一下WFQ这个过程:
- 在默认情况下每个队列进入的流量是相同的,我们会以权重小的开始发送;
- 权重大的队列能发送的数据包大小需要根据权重小的来判断,且数据包的大小表示的是总体发送数据的大小,而不是单次,如第二、三、四周期的发送条件。
- 每一个队列中,只允许增加至多一个大于限制大小数据包,即可以发送达到限制大小前的所有数据包,如之前例子中的第二周期W=2的队列发送8,9,10,11数据包后才达到限制。
下面还有一道WFQ的变种问题:
如果每个队列进入的流量改用不同的速率(带宽)表示,而总发送速率只有10 bytes/s,其他的不变的情况下,该如何分配每一个队列发送数据包的带宽呢?
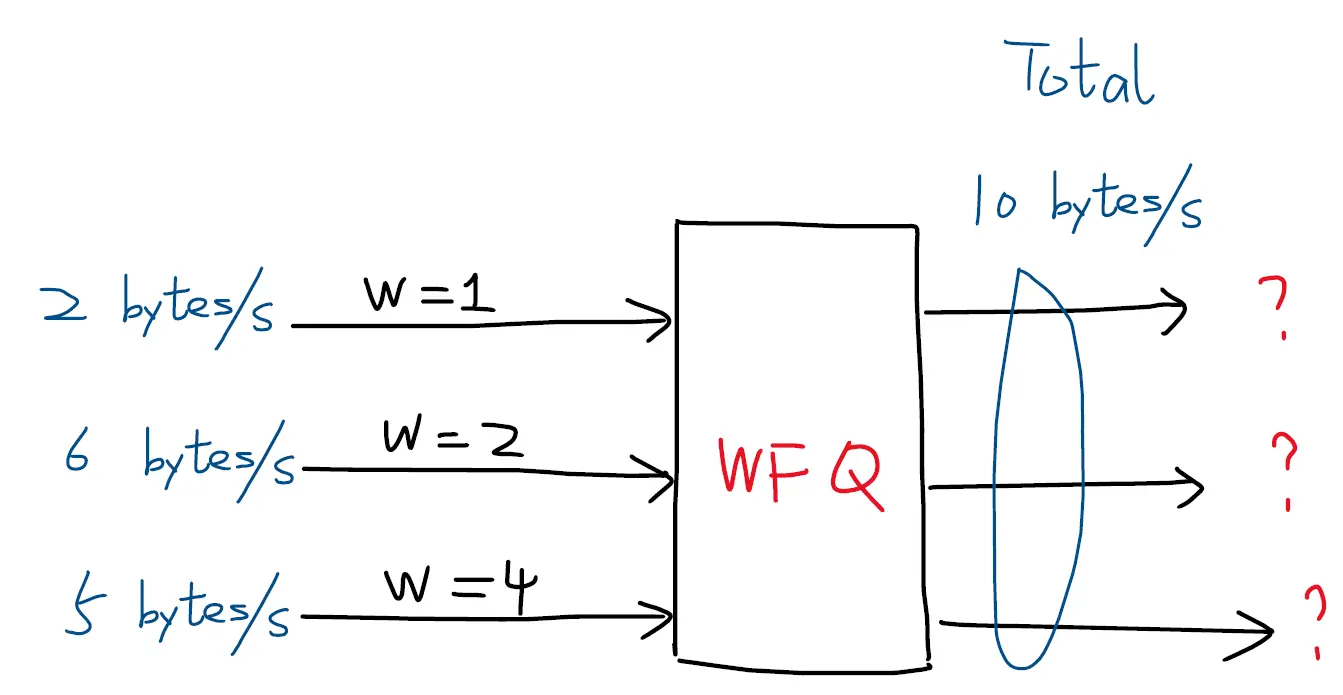 这种情况下,每个队列的速率就可以当成它要发送的中流量,我们需要考虑分配按比例公平分配带宽。按照比例,对于发送10 bytes的带宽,每个队列可以得到的带宽如下:
这种情况下,每个队列的速率就可以当成它要发送的中流量,我们需要考虑分配按比例公平分配带宽。按照比例,对于发送10 bytes的带宽,每个队列可以得到的带宽如下:
Bandwidth1: 10 * 1/7 = 1.43
Bandwidth2: 10 * 2/7 = 2.86
Bandwidth3: 10 * 4/7 = 5.71对比当前每个队列的速率我们发现,在第三个队列中得到分配的带宽已经大于了其队列带宽(带宽有剩余),故在第一个调度周期中,三个队列分别得到的带宽有:
Bandwidth1: 10 * 1/7 = 1.43
Bandwidth2: 10 * 2/7 = 2.86
Bandwidth3: 5此时存在带宽剩余,剩余的带宽为:10(1 - 1/7 - 2/7) - 5 = 5/7. 在第二个调度周期中,将继续分配剩余的带宽给没有达到上限的队列。同样的根据比例分配给第一和第二个队列,此时因为第三个队列已经达到上限,则不参与分配,本次分配中每个队列可以得到的带宽如下:
Bandwidth1: 5/7 * 1/3 = 0.238
Bandwidth2: 5/7 * 2/3 = 0.476 此时总体的带宽条件如下:
Bandwidth1: 1.43 + 0.238 = 1.667
Bandwidth2: 2.86 + 0.476 = 3.333
Bandwidth3: 5它们均小于自己队列的带宽上限,但是全部的发送带宽已经分配完毕,故最后的流量控制分配为:
Bandwidth1: 1.667
Bandwidth2: 3.333
Bandwidth3: 5