RSSBrew beta 简单介绍和使用指南
RSSBrew 是一个 RSS 处理和管理的工具。简单来说就是通过处理用户添加 original feed,系统后台获取原文章,根据用户设置进行一系列处理,把处理后的文章重新聚合生成一个新的 processed feed,然后用户订阅这个 processed feed 即可。
目前拥有以下功能:
- 可以应用于文章,标题,URL 的过滤条件和过滤组,可用来过滤文章是否进入最终的 feed 或者是否用生成摘要。
- 聚合多个 feed,生成一个新的 feed。
- 使用 AI 对用户过滤后的文章单独生成摘要,附在原文前,可自定义 prompt。
- 周报日报功能,可以将一天或者一周的文章聚合成一个文章。
安装教程请参考 INSTALL.md。安装位置需要 docker engine,需要有公网 ip 的服务器,推荐使用 vps。一个域名(可选),如果没有域名,可以使用 ip:port(默认8000) 的形式访问。
由于最近加了 huey 作为任务队列,所以不通过 docker-compose 安装的方法暂时没有更新,目前推荐 docker-compose 安装。
如果需要配置域名访问,推荐使用 caddy 或者 nginx 作为反代,这里就不做详细介绍了。
注意需要把部署的域名加入到 .env 的变量 DEPLOYMNET_URL 中才能正常通过自定义域名访问。如果没有,请把 ip:port 加入到 DEPLOYMNET_URL 中,不需要加 http:// 等协议头。
使用说明
有用户反馈想要使用说明,由于目前文档没有写好,这里简单写一下如何使用。访问应用后有四个配置项,分别是 original feeds, processed feeds, tags, app setting。因为测试阶段短时间内文档不会完成,所以我这里尽可能写的详细,请根据需要的功能跳转到对应的段落阅读。
App setting
App setting 用来配置 auth code,设置后需要在访问时在订阅源地址后面加上 ?key=your_auth_code 才能访问。
original feeds 用来添加原始的,需要处理的 atom 或者 xml feed,可以配置 url, 以及可选配置名称和 tag。 Tag 是用来方便分类管理 original feeds 的。
processed feeds 是处理后的 feed,在列表栏从左到右是名称,每次更新周期需要总结的文章数,订阅链接,以及包含了多少个 original feeds。
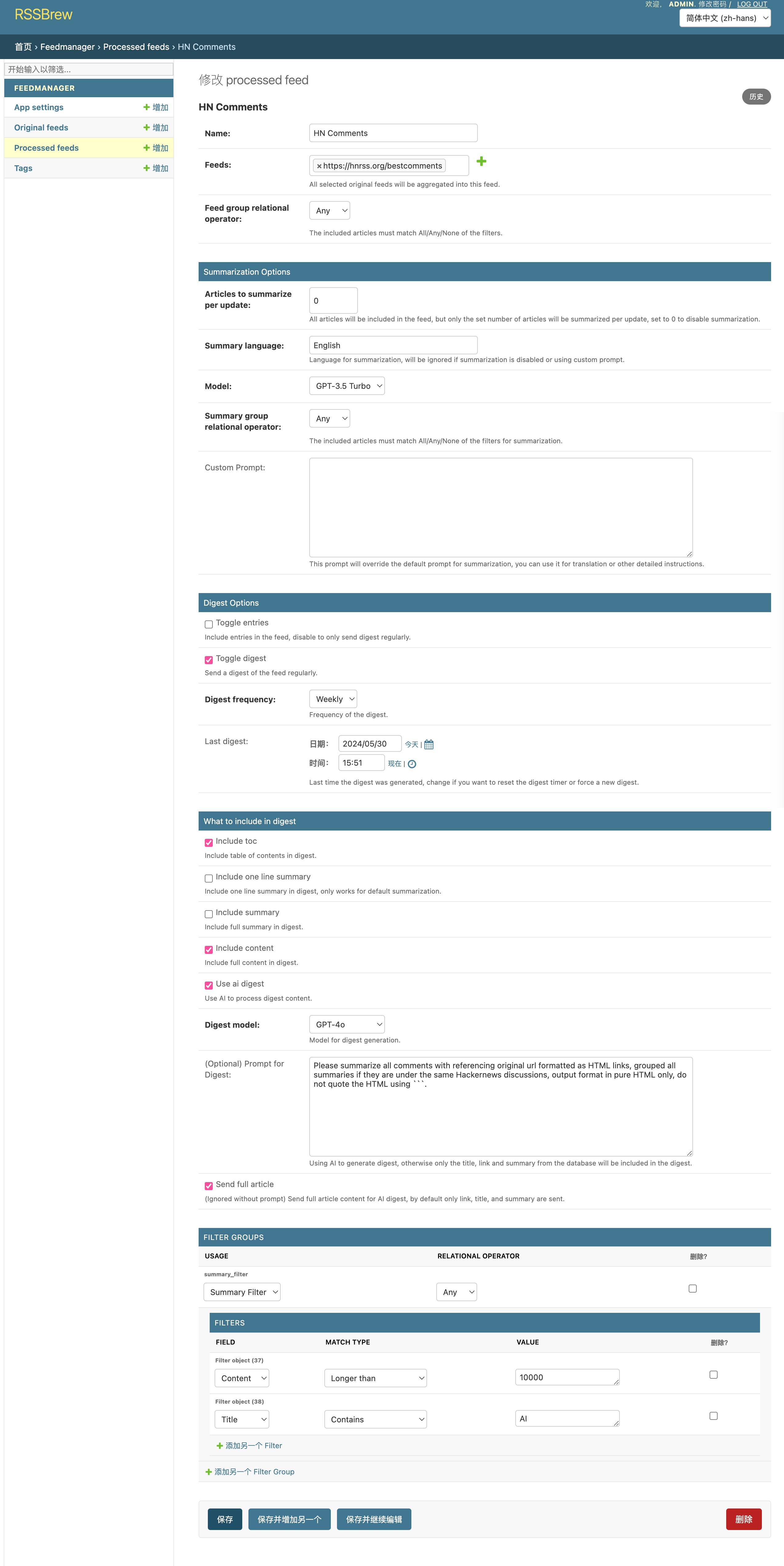
点击名称进入 processed feed 的配置页面,可以配置过滤条件,过滤组,摘要和 日周报的生成。
聚合功能
前两项名称和 Feeds 是必须的,feeds 是多选框,用来添加已有的 original feeds,最终会把所有选中的 feeds 聚合到这个 processed feed 中。有了这两个配置,理论上就可以用上聚合功能订阅了,接下里所有的配置都是可选的。
Feed group relational operator (过滤组关系) 会在后面过滤组中详细介绍。目前先不用管。
Summarization options AI 摘要功能
在 summarization options 中,可以配置每次更新(测试阶段默认是每 5 分钟,在 docker-compose.yml 中通过 cron 变量可以把周期调大一点)总结的文章数,为 0 就是不用 AI 总结功能。可以选择语言,model, 自定义 prompt。默认 prompt 会给一条一句话总结和一个稍长的总结。默认效果如下:

Summary group relational operator (过滤组关系) 同上,会在后面过滤组中详细介绍。目前先不用管。
Digest options 日周报功能
Toggle digest 是开关,开启后会生成日报或者周报。默认是关闭的。如果开启,可以配置 daily/weekly。Last digest 的时间会在后台自动生成周日报时更新,
留空即在下一次更新时自动生成 digest,后面系统会根据这个时间是否需要生成新的 digest。一般情况下,这个项不需要管,如果需要测试用手动生成周日报的功能,可以把时间调到一周前或者一日前。
勾选 toggle digest 之后,可以配置周日报格式,主要由三大部分构成:
- 周/日报目录。
目录就是一个简单的标题-链接的列表,可以一眼扫过一周更新的条目,如上显示。如果在 summarizaiton options 中开启了 AI 摘要功能并且用了默认的 prompt,除了标题和链接,还会有 AI 一句话总结。
- 条目详细内容
如上图所示,紧跟着目录是 details,可以自选包含 AI 生成的摘要(需要在 summarization options 中开启 AI 摘要功能)和原文章内容。
- AI 分析你的周/日报。
勾选 use ai digest, 可以配置 digest model (推荐使用 gpt-4 或者 4o, 我测试下来 3.5 turbo 偶尔会出现总结不全的情况) 和自定义 prompt。下面 send full articles 是指你是否想要 AI 总结周日报的文章全文,如果不勾选,为了节约 token,和防止条目过多过长,只会发送给 AI 每篇文章的标题 url 和摘要(摘要需要在 summarization options 中开启 AI 摘要功能)。
这是一个在 telegram channel rss 生成周报的效果:

以上三大部分关于周日报内容的配置都在 what to include in digest 中, 也就是 toc, one-line summary, summary, ai digest。
另外,在 toggle digest 后面有一个选项 toggle entries。如果有些 feed 你只想看每周每天扫一遍周/日报,不想要看到其他的原文章条目更新,让你的未读堆积。你可以取消勾选 Toggle entries 来隐藏原文章条目,不要怕错过,他们会在日报周报中出现。
过滤和过滤组
我们还没有讨论到过滤,如果配置了以上的内容, processed feed 会把所有的 original feeds 聚合到一起,生成一个新的 feed。但是这个 feed 会包含所有的原文章,并且不管是什么文章,都会进入周日报,进入更新的 entries, 或者发给 AI 生成摘要,如果想要更加个人化的信息源,比如说监控某些关键词,同时屏蔽另外一些关键词,或者比如说让 AI 长文总结,短文不总结,或者只总结某一个关键词文章,这需要过滤功能。
为了实现高级的过滤,RSSBrew 用了两层过滤条件。也即 过滤组(filter group)- 过滤器 (filters)。过滤组包含过滤器,负责管理组内所有过滤器的关系(任意条件 any /所有条件 all/无一条件 none = not any)满足以及过滤器的用途(用来完全屏蔽文章或者,不屏蔽文章只是过滤他是否总结)。过滤器是具体的过滤条件,比如说标题/内容/url 包含某个关键词,满足某个正则表达式,或者文章长度大于/小于某个值。
多个同用途的过滤组之间还可以共同作用,他们之间的关系就是由上面提到的过滤组关系 Feed group relational operator 以及 Summary group relational operator 来决定的。比如说你有两个过滤组 A B 都是用来 Feed Filter(用来完全屏蔽文章) 的, 且他们之间是 any 的关系。分别由两个 and 过滤器构成,那么就可以实现高级的过滤运算逻辑比如:
A or B = (A-1 and A-2) or (B-1 and B-2)
当然如果你只是想要最简单的过滤,只需要一个过滤组就可以了。即使这样你也可以在组内设置多个过滤条件,或者通过配置正则表达式让单层过滤器实现很多功能。
后期 plan 和功能
- 前端报错信息,目前很多报错只是记录在后台,没有返回给前端。出错了 debug 时需要查看 logs 日志。
- tag folder 功能完善,更好的分类管理
- opml 的批量导入导出
- 全文获取
- json feed 支持
- 完善文档
不过目前正忙着写毕业论文和找工作,所以短期内这些功能都没有 ETA。但等忙完毕业论文会把这个项目完善,也会一直维护更新。欢迎在 telegram 交流群 和 GitHub issue 中里提出建议和需求。