Augmentation helps ALBEF a lot
I was trying to implement ALBEF by myself for practice. After finishing all the parts (Vision part, BERT part, including Masked Language Model), I trained the model on COCO-Captions/SBU-Captions/CC3M/CC12M dataset (actually more data than the original paper). But the result is quite weird. An old steam train was recognised as a building, and a few fish were recognised as statues.
To solve these weird mistakes, I reviewed the code many times and finally noticed a sentence in the paper:
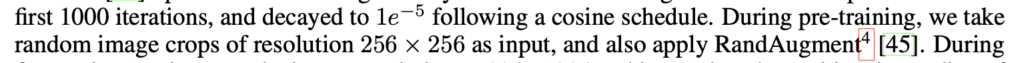
Although it’s just a normal sentence in the paper, the augmentation could improve the ALBEF model significantly. After randomly cropping the 256×256 raw image to 224×224 and also using the RandAugment, I finally got a more stable and suitable model. Let’s see some examples:



Previously, the fish had been recognised as “shoes”, and the bedroom as “city”. They all become very well after augmentation.
But there are still some interesting bad cases:


Adding a prefix of “A picture of” could help the ALBEF model improve its recognition capability, or actually, there is a lot of text like “A picture of XXX” in the CC3M or CC12m dataset.
Anyhow, I finally implemented and trained a workable ALBEF model by myself, and my RTX-3080Ti card.