System Design Interview and beyond 10 - Deliver Data at large scale
Partition
How to scale message consumption
Single consumer vs multiple consumers
Problems with multiple consumers(order of message processing, double processing)
-
Scale horizontally: more machine or vertically better machine
-
Single consumer: message order is preserved but unreliable(restart, network issue...) ;
-
Multiplen consumers : high availability ; but messages can be processed out of order; and higher change of processing the same messages multiple time.
-
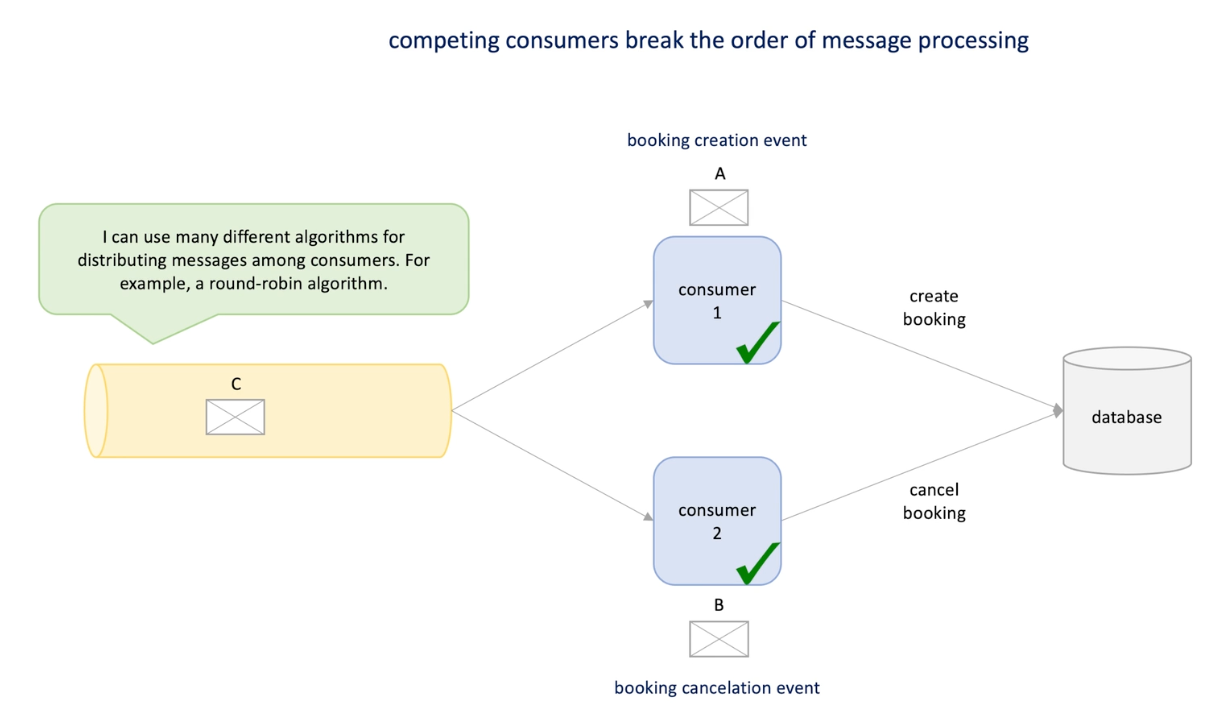
Out of order issue demonstration: push model:
-
I have a queue and two consumers 1 and 2 messages are dispatched in a round robin manner ;
-
I have three messages A, B and C. A to consumer 1, B to consumer 2....
-
One day the message A is processed in the consumer but slower than B is processed, while A is a create booking , B is cancel booking
-
Here we cancel first and then create, resulting in booking is still not canceled.
-
-
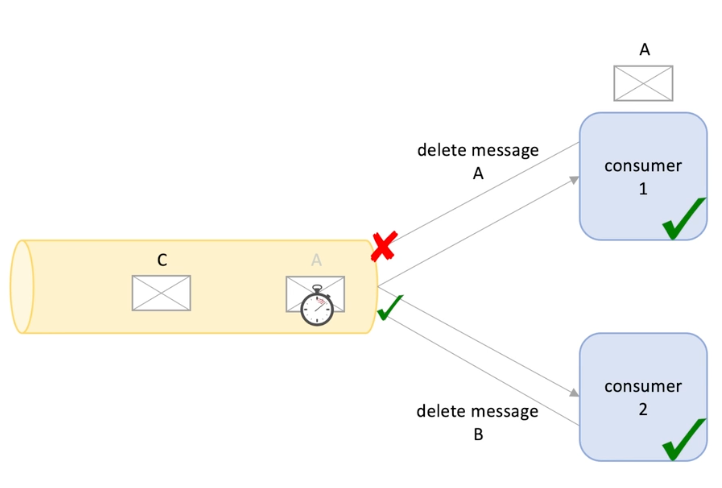
Double processing : pull based
-
I have a queue and two consumers 1 and 2; I have three messages A, B and C.
-
Consumer 1 pulled A and consumer 2 pulled consumer B; messages are marked invisible
-
However consumer 1 processed message A but failed to send the ack to the queue;
-
So after the visibility timeout, A become available again and pulled by consumer 2;
-
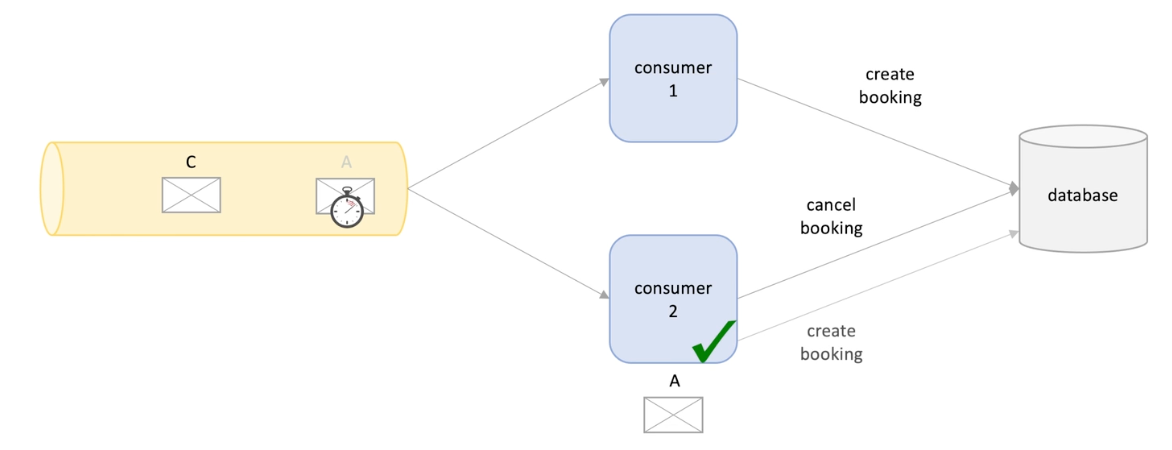
Same example for message A and B, A is booking create and B is cancel. Here consumer A create a booing, B cancel a booking
-
But consumer 2 proceeded A again so the booking created again.
-
-
One solution is to use a deduplication cache shared by all consumers,
-
One more example multiple consumer, log-based messaging :
- Each consumer manages its now offset and messages are not immediately deleted -> no competing one a singe queue
-
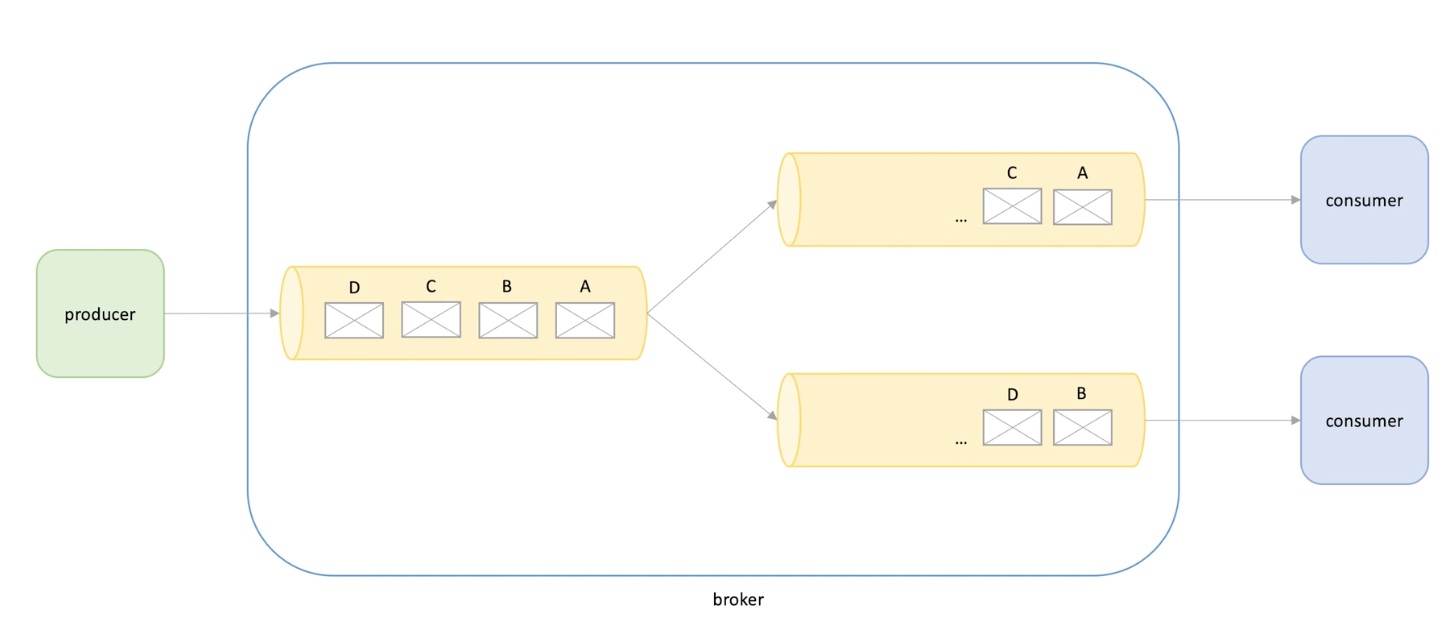
Solution: data partitioning (sharding): multiple queues for each consumer
- The order of messages among queues is trivial but the messages order in a queue is important and should be ordered in some manner (for a single user)
Partitioning in real life systems
Pros and cons
Applications
-
Pros and cons
- High scalability (add shard when data grows )
- Performance (each shard can parallel process )
- Availability (one shard failed, others continue serve)
-
Applications
-
Messaging system - RabbitMQ - shared queues
Producer send messages to a single queue and then partitions to multiple regular queues, shards. Each shard has a single consumer. Total order is lose, but order is guaranteed in shard level
-
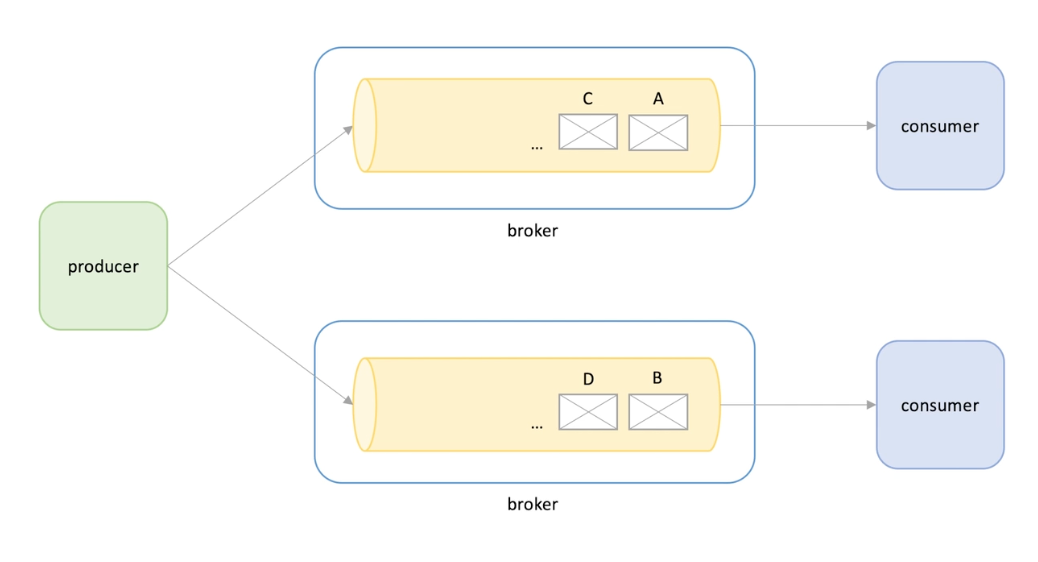
Log-based messaging system Kafka, Kinesis
Divide incoming messages into partitions , each partition is processed by its own consumer. -> no competing consumer -> so you want to parallelize message processing we create more partitions.
-
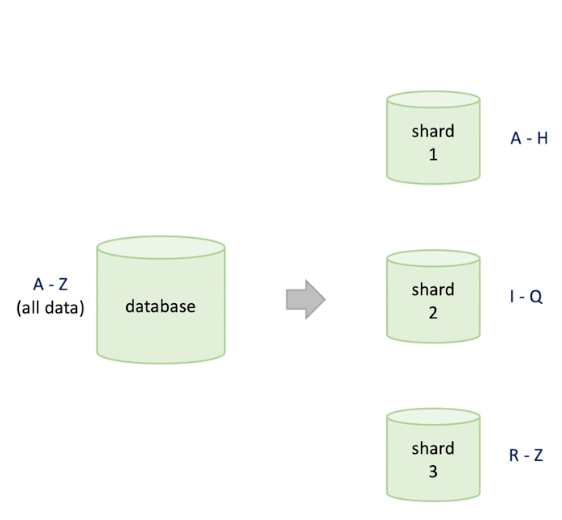
Database
Each shard(also called node) holds a bunch of data. -> new issues raise
- Which node should we write data
- How to pick a shard when reading data
- How to ensure data is evenly distributed among the nodes;
- What is evenly distributed ? -> same volume of data or same read and write requests.
-
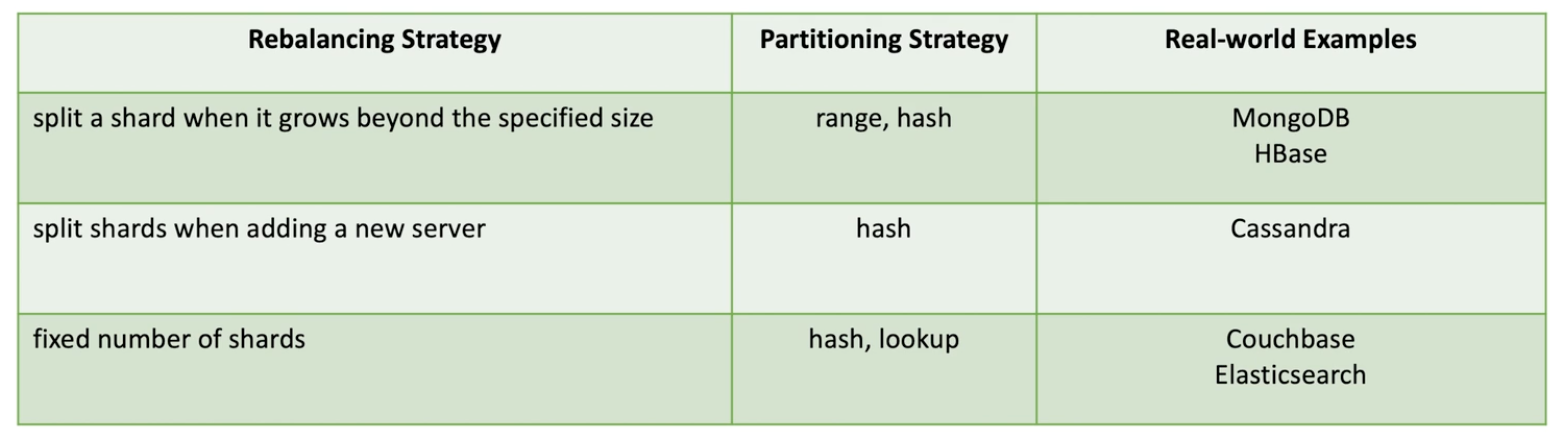
How to partition data
-
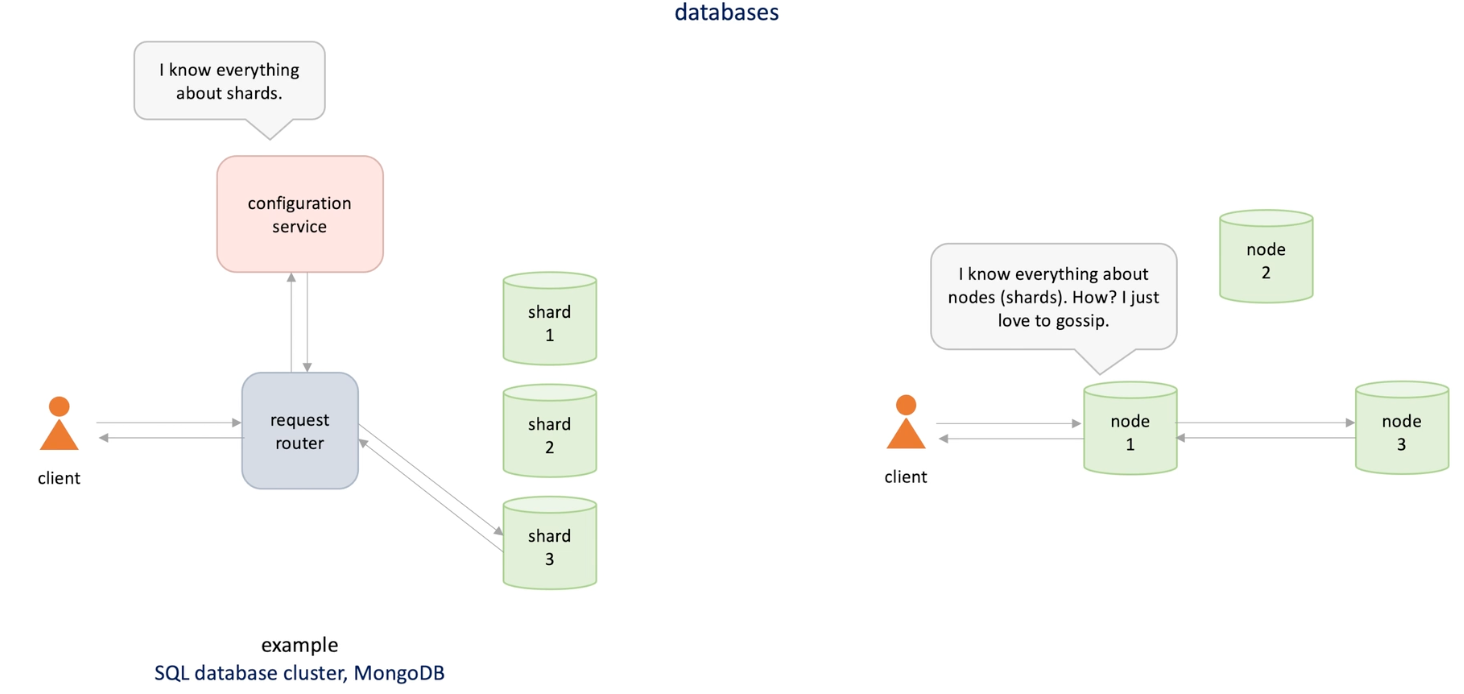
Configuration service: how many shards and which data in which shard -> client requests comes to request router and router check configuration service to check which shard is to use. -> SQL and NoSQL database
-
Avoid additional components, allow nodes to communicate to each other on how to split data and route request -> Dynamo and Cassandra
-
-
Shard can be used a distributed cache system
- Database sahrd -> cache shard
- Store in mem
-
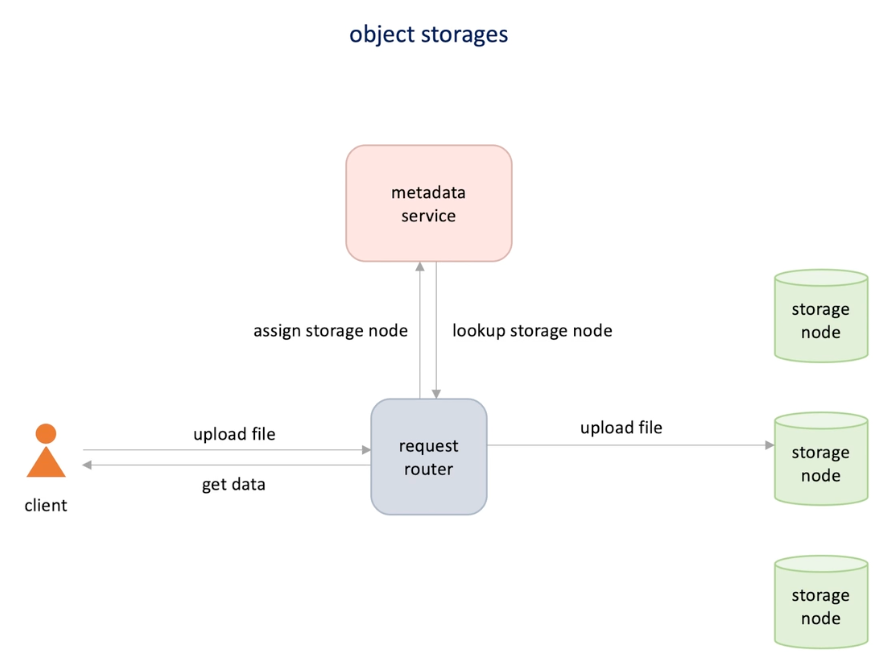
Object storage -> S3, google cloud storage, Azure Blob ...
-
When we upload file, one node is selected and store file there ;
-
Metadata is stored in the configuration service .
-
When get file, request router check the metadata service and forward the request to the node.
-
Partition strategies
Lookup Strategy
Range strategy
Hash strategy
-
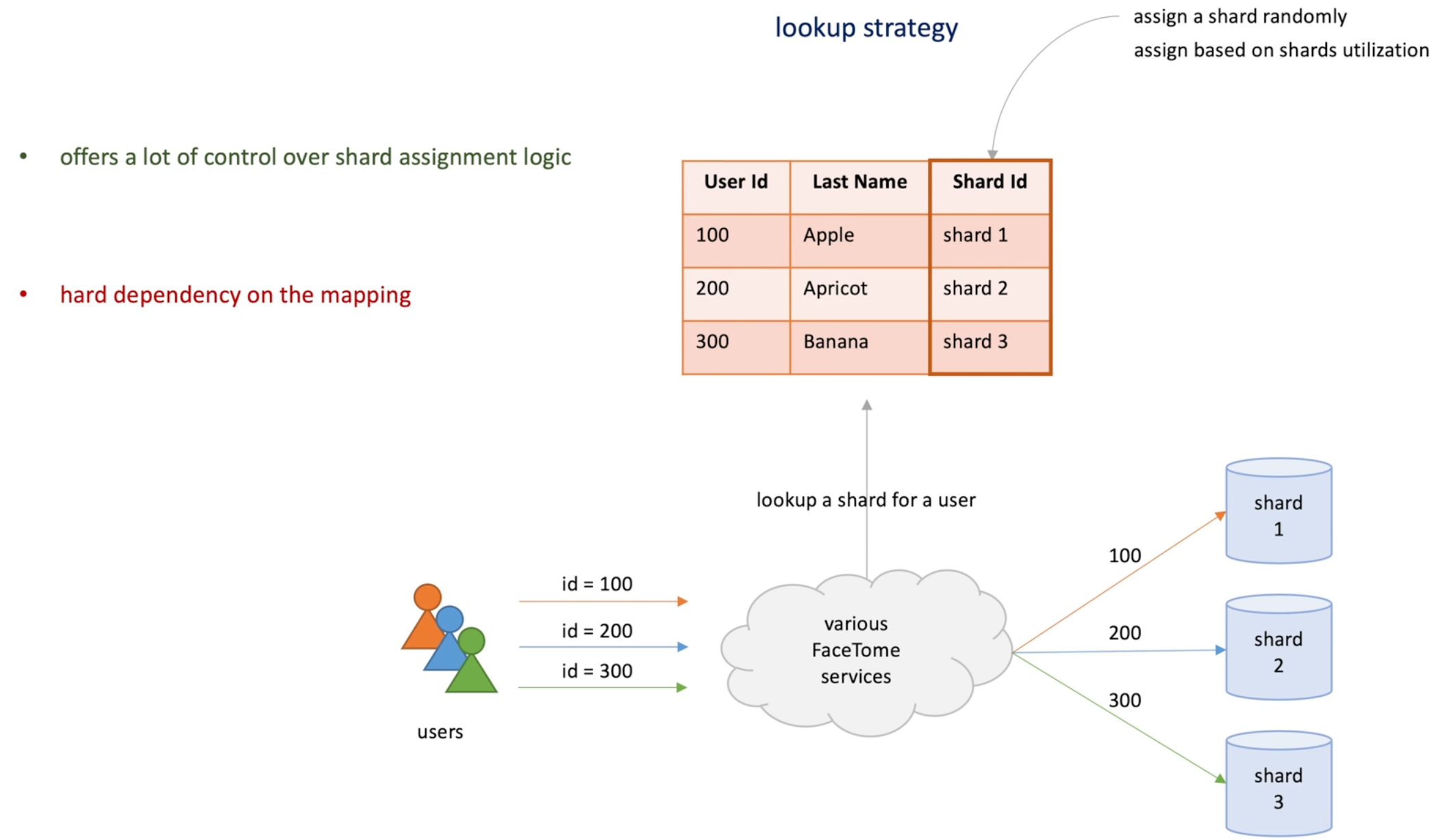
Lookup strategy : create a mapping ourselves , and assign a shard randomly to a user .
- Pro: control over shard assignment logic (randomly or based on shard utilization)
- Con: hard dependency on the mapping : for every read and write from users, we need to look up a shard that contains user's data.
- New issue arise: how make it highly available? Fast? Scalable ? Consistent? -> as the data grows, it's common to partitioning the lookup tables.
-
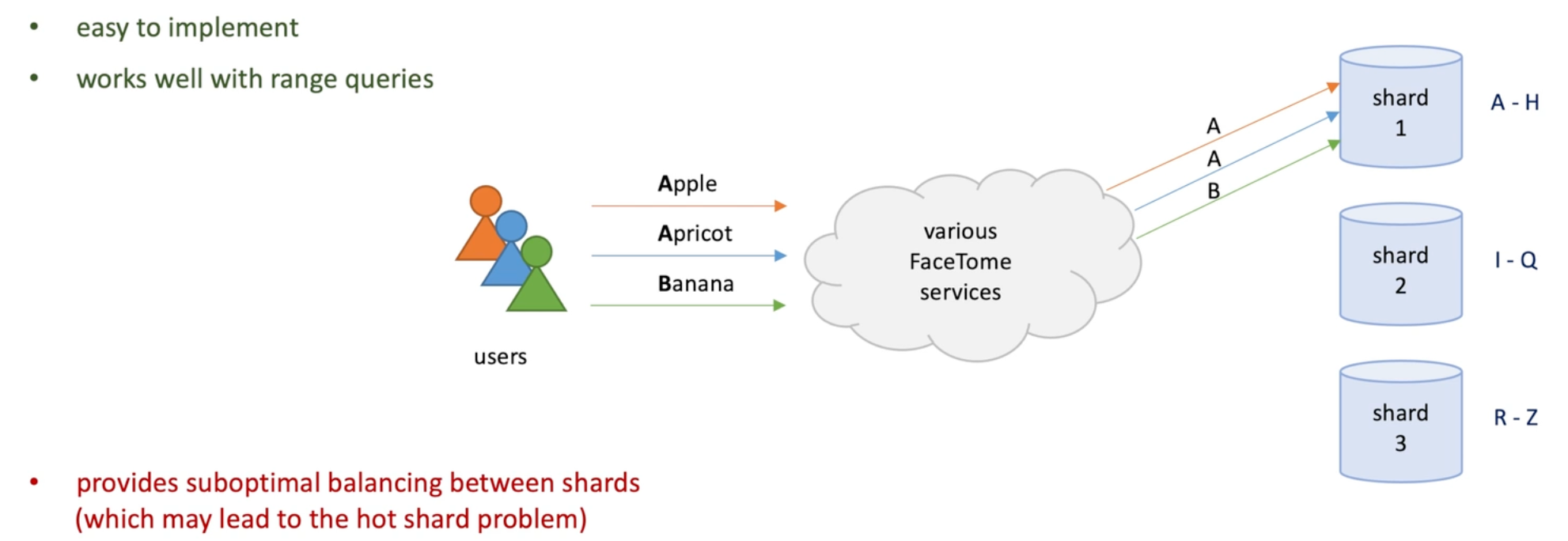
Range Strategy: shard responsible for a range of continuous keys.
-
Pros: easy to implement, works well with range queries.(orders in a month)
-
Cons: provide suboptimal balancing between shards (which may lead to hot shard problem-> single shard get much higher load than others)
-
-
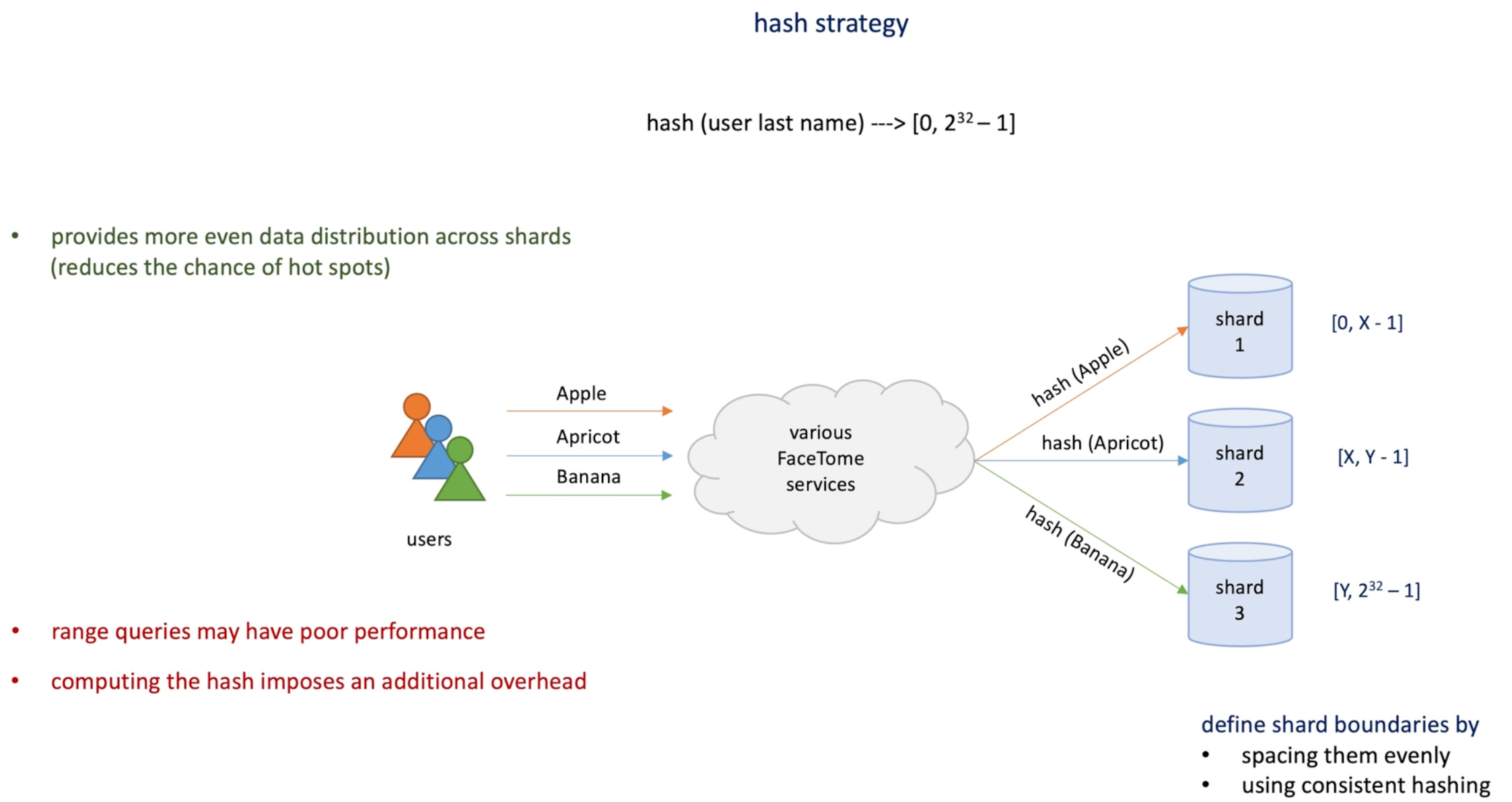
Hash strategy: based on users last name, take the string and compute a hash number.
- Sharding boundaries: spacing them evenly or consistent hashing
- pro: helps distribute data more evenly across shards
- Cons: range query have poor per and compute the hash imposes an additional overhead.
-
Request routing
Physical and virtual shards
Request routing options
-
Physical machine vs virtual shards : a physical hard can hold multiple virtual shards
-
Request routing service : identify the shard that's stores the data for specified ket and forward the request to the physical machine that host the identified shard -> a mapping
-
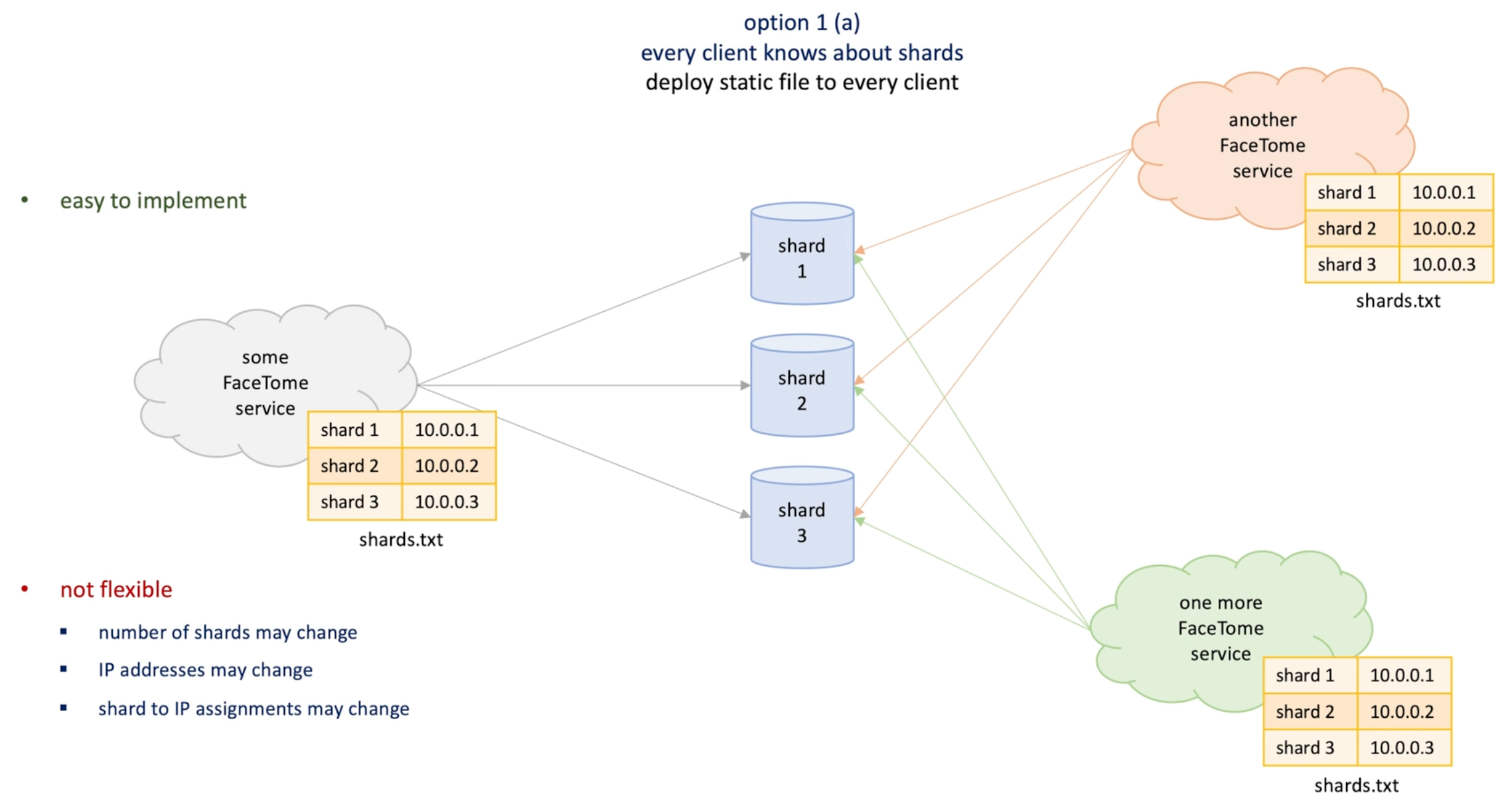
The mapping has the shard name and ip of shard live on. -> where to put the info?
-
Option1 : static field deployed every machines
-
Lack of flexibility , update (number of shard, IP, shard to IP ) will requires redeployment
-
-
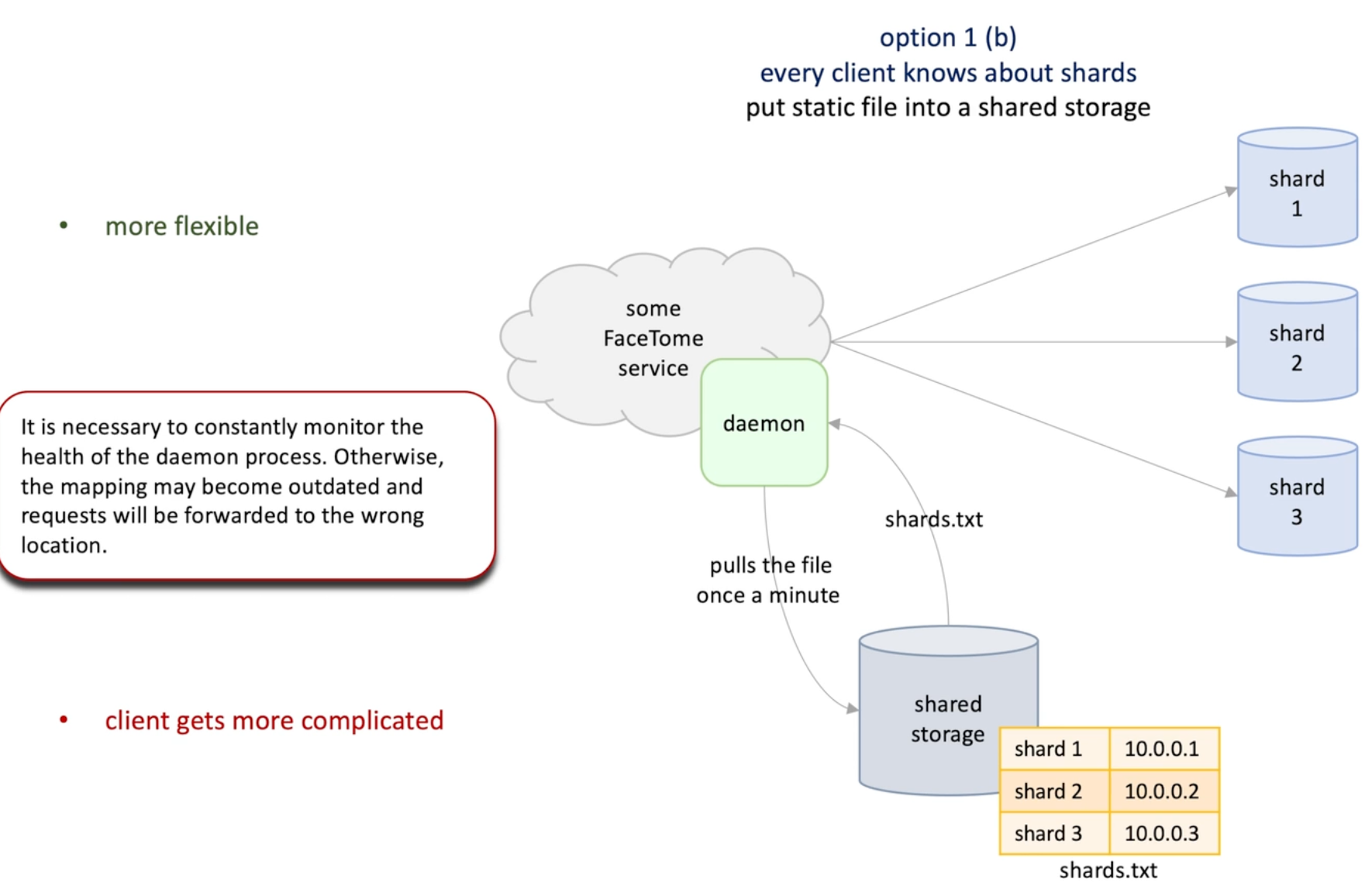
Option2: shared storage : S3 and daemon process pull the info from S3 periodically,
-
More flexible compare to option1
-
But increase complexity of client ,
-
Daemon process is vital here otherwise the mapping may be come outdated and request forwarding is wrong
-
-
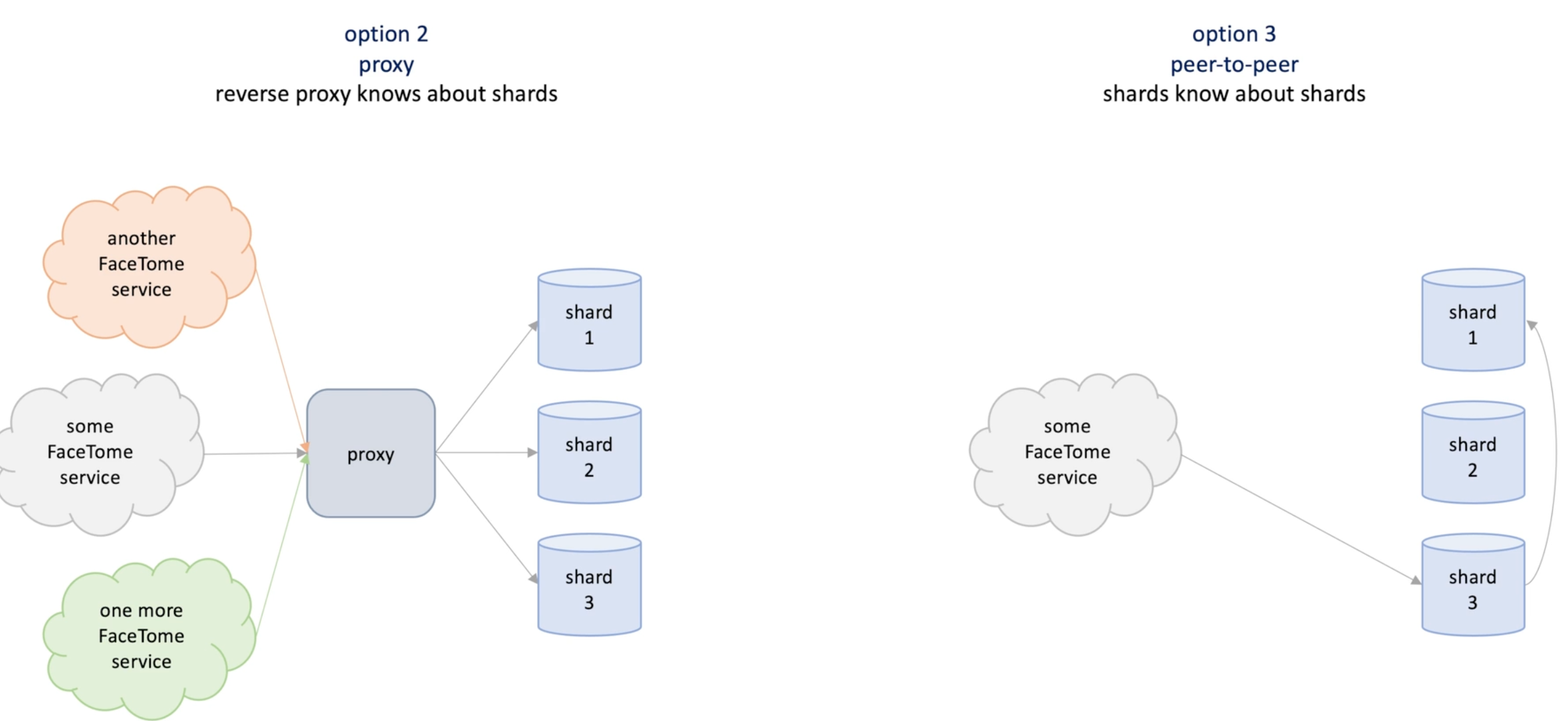
No updating client -> proxy option and p2p option
- Proxy has a mapping , clients make a call to proxy and proxy make call to the shard
- P2p: client make a call to random node and node redirect request to the right node(node know each other)
-
This mapping doesn't change frequently-> If we have small number of servers, we can share the list via DNS; if we have many server, we can pul LB between clients and servers.
-
How proxy machine find shard server on the network or shard server find each others -> service discovery
- Static list of IP addresses of whole shard machine, put them to a small number of proxy machines (in case of proxy option) or shard machines (in case of P2P option); use a daemon process to fetch the list from a shard storage(S3); or shared through DNS
- Service registry (classic client-sided discovery mechanism)
- Gossip protocol
Rebalancing partitions
How
-
Why rebalancing -> uneven load (number or requests ) on shard servers -> uneven data distribution/hot keys/share server failure(handover) -> Rebalancing
-
Option1 : split when shard size exceed a limit -> auto or manually -> clone shards(while handle all request) and updates metadata
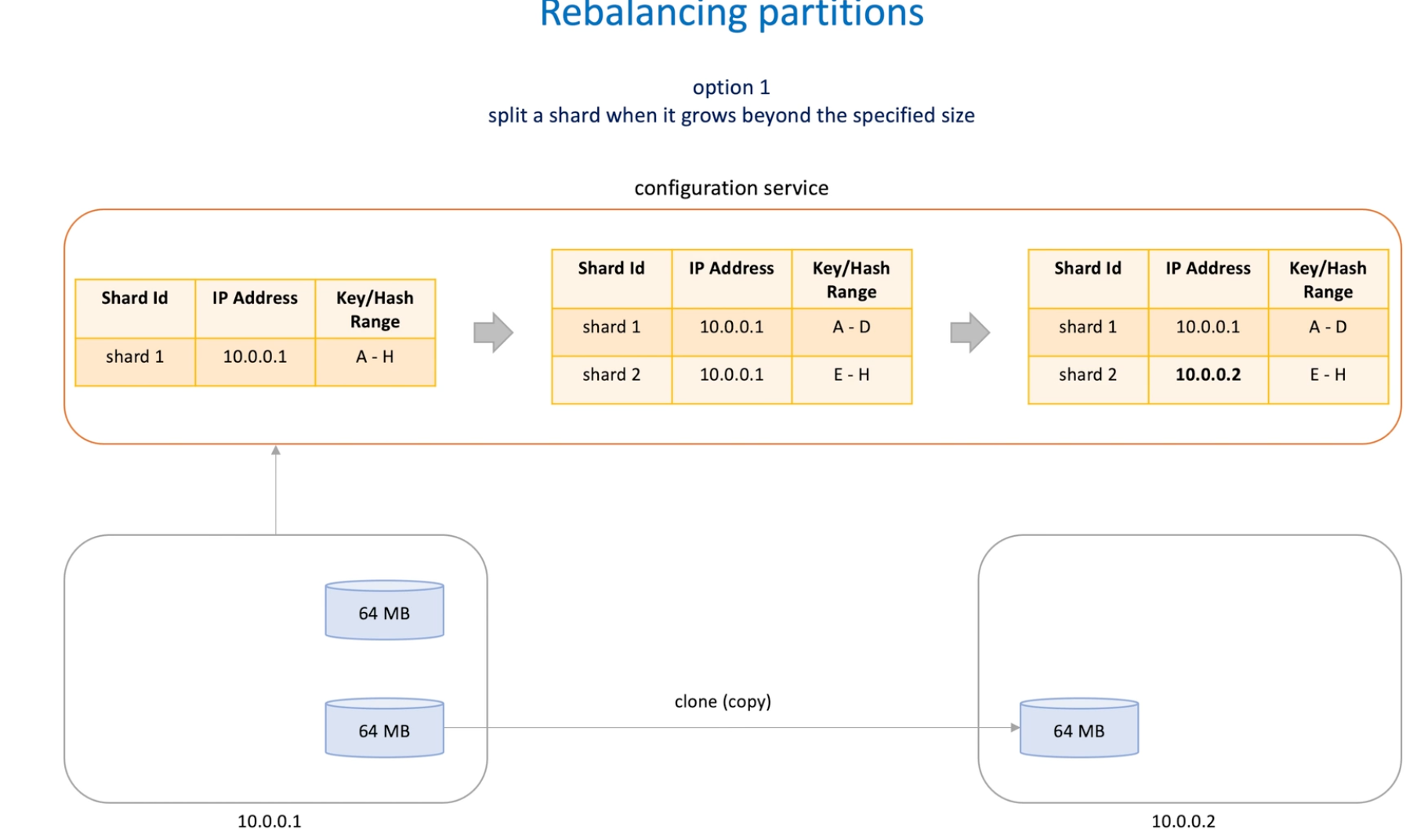
- This is a just metadata change and doesn't cause immediate data migration between shard servers
- Whether we need to redistribute the shards between servers is decided by another processor , the balancer.
- It's a background process that monitors the number of shards on each server. If largest and smallest shards exceed a limit, balancer start to migrate to reach an equal number of shards per server.
- Adding new server to cluster triggers the balancer to start sard migration process;
- Removing server is the reverse process.
-
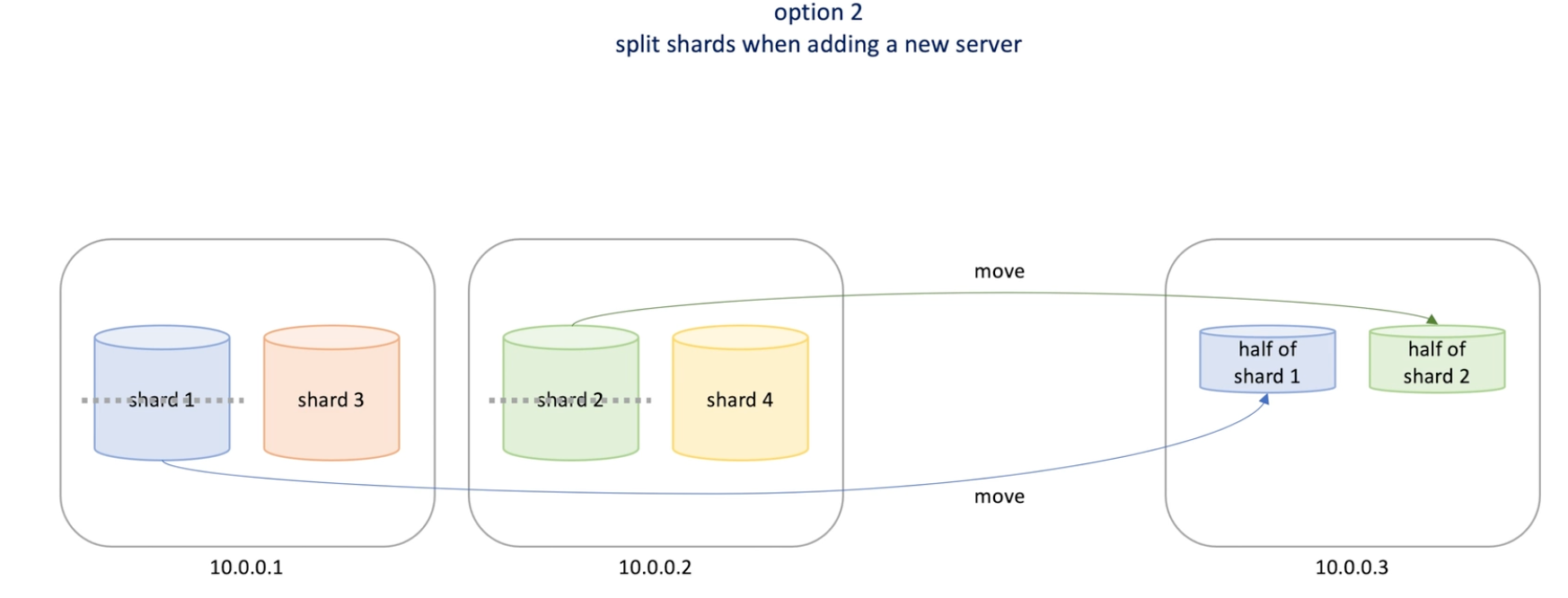
Split shard when adding a new server.
-
Shard owns a small range of hash keys , shard number fixed. ->fix number partition strategy
- Say we have 1024 shards, distributed to 64 shard server machine , shard will grow bigger but we can put it into some machine that has smaller shard
- When a new machine is added to a cluster , every machine move some shard to the new machine
- Simple to implement and maintain
- Hard to choose the initial number of shards ; another drawback is some shard grows really large
-
Consistent hashing
How to implement
Pros and cons
Virtual nodes
Application
- How to implement
- Boundaries for each shard (a range of hashes each shard owns )
- Where each shard lives(which physical server each shard lives on)
- How to rebalance shards(pick and implement a rebalancing strategy)
- Consistent hashing partitioning
- Hash function -> integer -> for each request -> we need it fast
- Cryptographic hash functions (SHA)(expensive) vs non Cryptographic hash(general, e.g. Murmurhash)
- How to split the range into smaller hash intervals and how to assign each interval to a server.
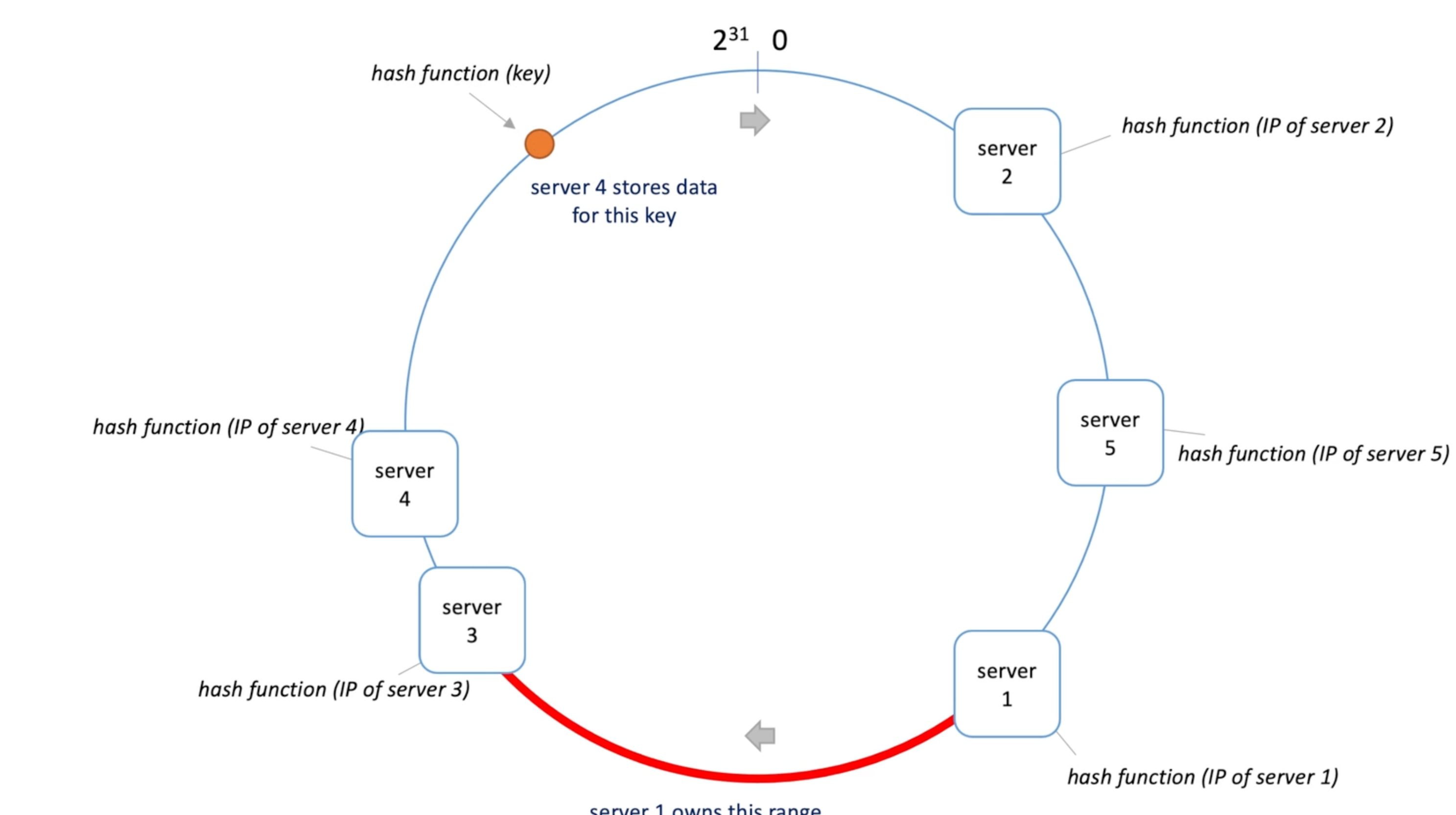
- Cosnsitent hashing -> circle, pick a random position as 0;
- Move clockwise one the circle
- Take a list of servers and calculate their hash values based on hostname or IP,
- Each server owns the has value between itself and it next one(clock wise)
- Easy to implement (simplicity and speed)
- List of server identifiers,
- Apply the hash function
- Get has range for each server
- Sort the list of hash ranges
- Share this ordered list with clients (request counting techniques)
- Using binary search, client can quickly find its server to send request to
- Client forwards the request to the server
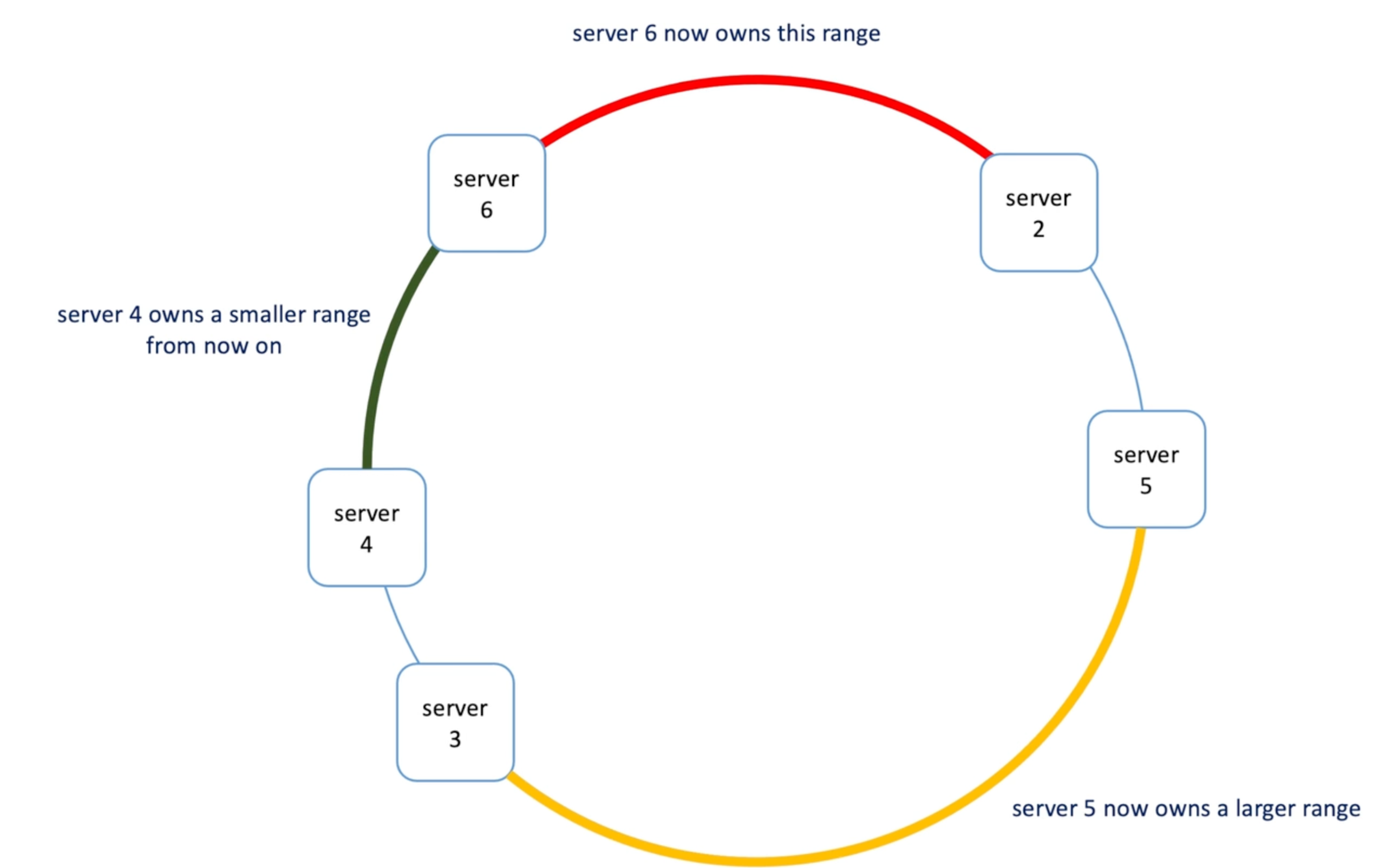
- How to rebalancing in consistent hashing
- When adding or removing a single server only impact it's neighbor
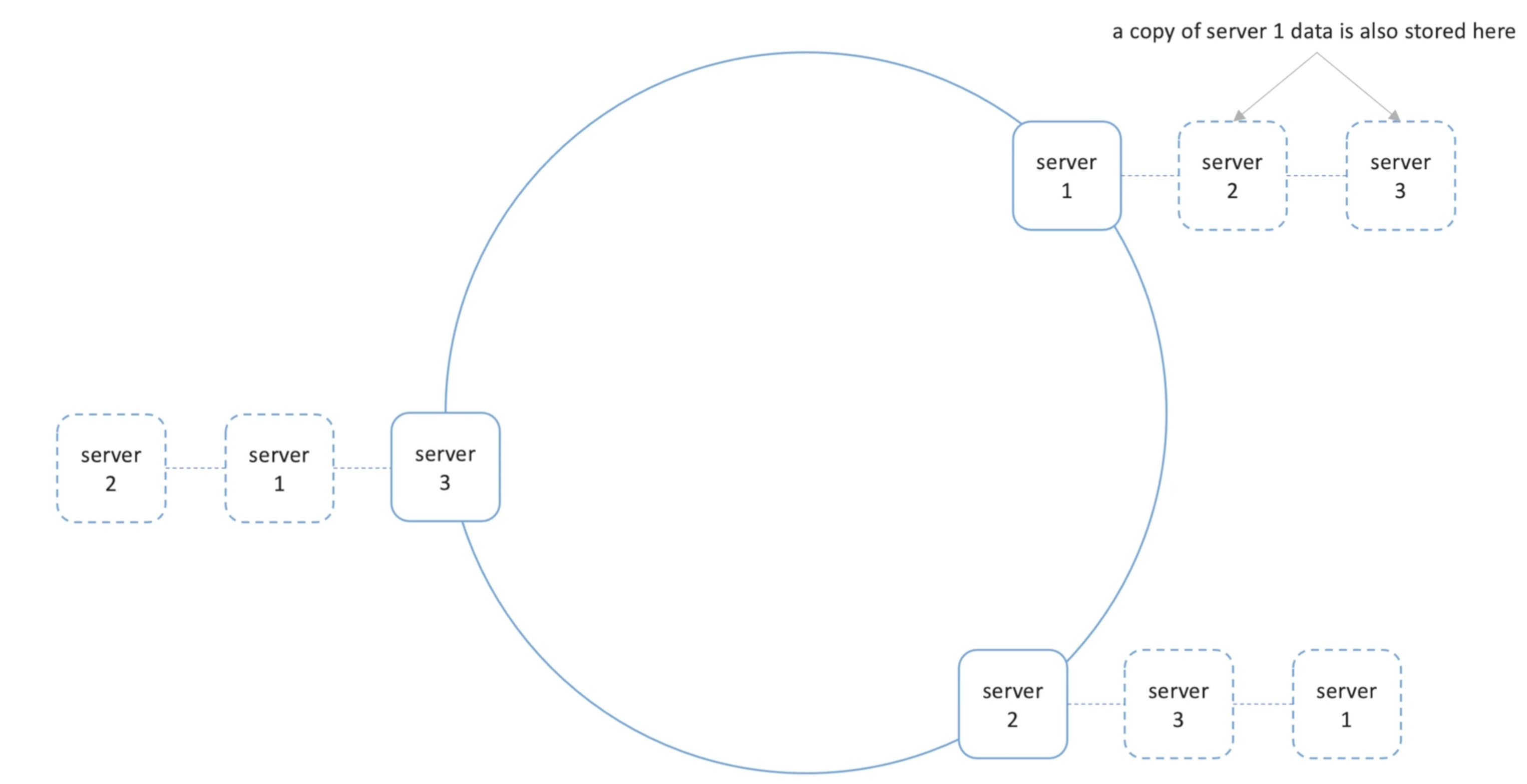
- Data is stored on neighbors (replica) to avoid data loss
- Issue 1 : Domino effect : when a serve is down due to high load or something, its load moves to the next neighbor, and next one is down due to same reason and continue passing the huge loads make one by one down.
- Issue 2: servers don't split the circle evenly
- When adding or removing a single server only impact it's neighbor
- Two address these two issue -> virtual node
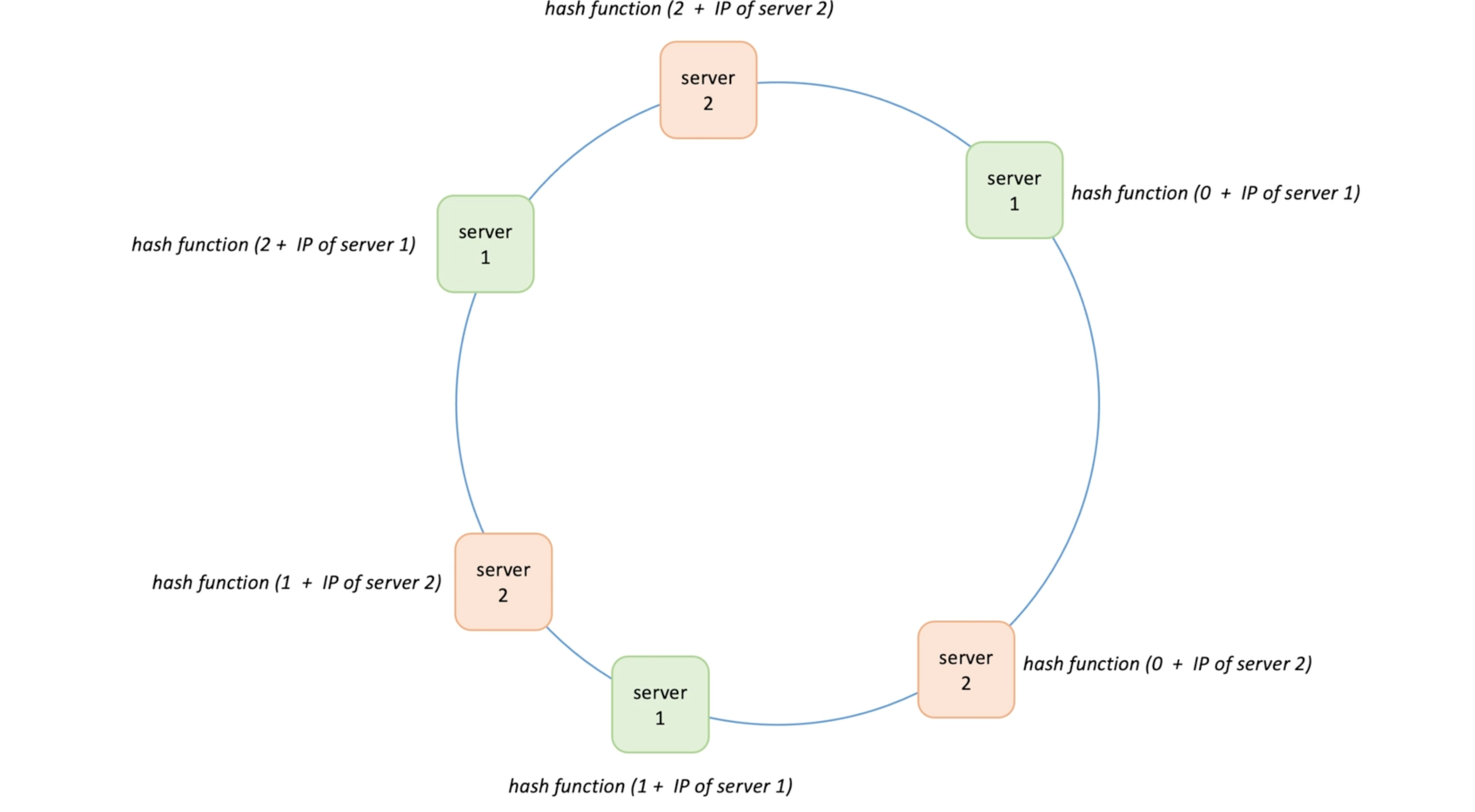
- Now each server are responsible for a set of range -> more evenly (although more memory to hold and find vnodes)
- Application
- Datavase (Cassandra, CouchBase, Riak, Voldemort)-> help evenly distribute data to shards and rebalancing and minimize data movements
- Distributed caches (client libraries, e.g. Ketama)
- CDN(Akamai)
- Network load balancers (Maglev)-> help LBs distribute connections among backend servers ; and when backend server is unavailable, only connection on this server will be reshuffled
- Chat applications (Discord) user -service
- Messaging systems (RabbitMQ)
- If data are short lived and doesn't need to move around for rebalancing -> basis partition-> simple mod is enough.