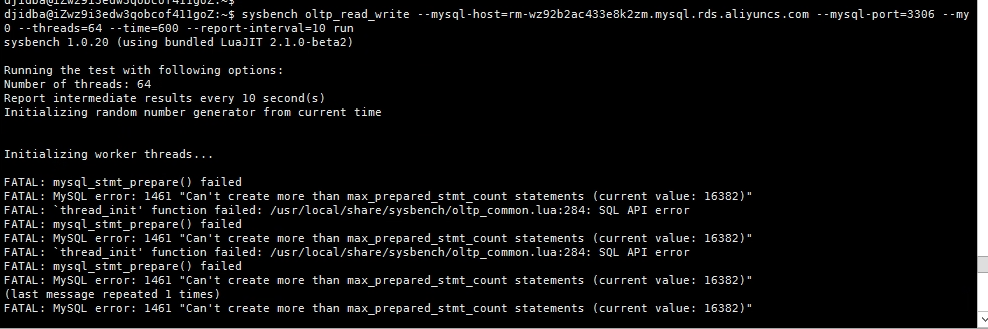
sysbench报错max_prepared_stmt_count
在一个8c16g的阿里云mysql上进行sysbench,在run 压测的时候,报错max_prepared_stmt_count不够了:
sysbench oltp_read_write --mysql-host=rm-wedtteessttm.mysql.rds.aliyuncs.com --mysql-port=3306 --mysql-user=**** --mysql-password=********* --mysql-db=testdb --tables=30 --table-size=500000 --threads=64 --time=600 --report-interval=10 run
max_prepared_stmt_count的值,可以参考下面的表格进行设置:
| 测试模型 | prepare语句数量计算公式 |
|---|---|
| oltp_read_only | 线程数 * 表数量 * 5 + 线程数 |
| oltp_write_only | 线程数 * 表数量 * 4 + 线程数 |
| oltp_read_write | 线程数 * 表数量 * 9 + 线程数 |
| oltp_insert | 0. (oltp_insert场景没有prepare语句) |
在MySQL中,可以使用prepare来进行sql的预编译处理,pg也有,oracle也有,sqlserver也有。注意这里的prepare是指prepare-statement,而不是分布式事务中二阶段提交中的prepare-transaction。
在prepare阶段,SQL经历了语法语义解析、统计信息分析、sql重写,进入下一个execution阶段。主要的作用用于一次解析,多次执行。prepare仅在当前数据库会话期间有效。会话结束时,预备语句会被销毁,或者会话结束前DEALLOCATE也可以。
举例:
mysql> PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse'; mysql> SET @a = 3; mysql> SET @b = 4; mysql> EXECUTE stmt1 USING @a, @b; +------------+ | hypotenuse | +------------+ | 5 | +------------+ mysql> DEALLOCATE PREPARE stmt1;
PREPARE usrrptplan (int) AS SELECT * FROM users u, logs l WHERE u.usrid=$1 AND u.usrid=l.usrid AND l.date = $2; EXECUTE usrrptplan(1, current_date); DEALLOCATE usrrptplan; --检查当前处于prepare状态的SQL: SELECT name, statement FROM pg_prepared_statements; --检查prepare之后语句的执行计划: EXPLAIN EXECUTE usrrptplan(1, current_date);
注意,postgresql的prepare会以两种方式运行,通用plan和自定义plan。自定义plan是根据每次的参数值不同而不同。
默认情况下(即 plan_cache_mode 设置为 auto 时),服务器会自动选择对具有参数的预备语句使用通用计划还是自定义计划。当前规则是,前五次执行使用自定义计划,并计算这些计划的平均估计成本。然后创建一个通用计划,并将其估计成本与平均自定义计划成本进行比较。如果通用计划的成本与平均自定义计划成本的差距不大,使得重复计划看起来不太可取,则后续执行使用通用计划。
可以通过将 plan_cache_mode 设置为 force_generic_plan 或 force_custom_plan 来覆盖此启发式算法,强制服务器使用通用计划或自定义计划。此设置主要用于通用计划的成本估计由于某种原因严重错误时,允许选择它,即使其实际成本远高于自定义计划。
这个有意思的特性,唐成唐老师有写过一个文章《PostgreSQL绑定变量窥视》。 这里直接说结论: 绑定变量窥视的场景,如果前面5次参数都是一个变量,产生同一个执行计划,那么后面的变量即使变成其他的,那么也会复用前者的执行计划。如果前面5次中有任何一次或者多次是别的变量,那么后续的执行计划不固定,会按照参数值来选择合适的执行计划。
create table t as select * from dba_objects; SQL> variable vid number; SQL> exec :vid := 2; SQL> select * from t where object_id = :vid;
DECLARE @P1 INT;
EXEC sp_prepare @P1 OUTPUT,
N'@P1 NVARCHAR(128), @P2 NVARCHAR(100)',
N'SELECT database_id, name FROM sys.databases WHERE name=@P1 AND state_desc = @P2';
EXEC sp_execute @P1, N'tempdb', N'ONLINE';
EXEC sp_unprepare @P1;
-- 注意一下,sqlserver中使用declare、set参数化,这还是属于adhoc语句,非prepare语句,如下面这样:
DECLARE @BusinessEntityID INT;
SET @BusinessEntityID=12;
SELECT * FROM Person.Person WHERE BusinessEntityID=@BusinessEntityID;
所以这个问题引发出来的思路是这样的,sysbench压测,报错max_prepared_stmt_count不足,这可能是sysbench压测的时候,只考虑sql的执行情况,不考虑sql的,预处理情况,所以在压测初期,就将所有的sql先进行prepare,而prepare的周期在mysql中跟session的周期一致(因为mysql无法跨session缓存解析后的信息),所以sysbench压测的thread数会关系到max_prepared_stmt_count的数。
prepare是为了“一次编译,多次执行”,这个特性在其他数据库类型中也存在,比如pg、oracle、sqlserver。但mysql和pg在完成prepare之后,不会共享解析结果,oracle和sqlserver可以,因为后两种商业数据库,有共享池,缓存解析后的信息,可以复用给同样的sql。而mysql和pg这种没有共享池的数据库,也希望复用prepare statement的sql,可以借用连接池来应对。
大致是思维导图是:

高清PDF档:prepare-statement
参考:
《MySQL · 参数故事 · max_prepared_stmt_count》
《MySQL的SQL预处理(Prepared)》
《postgresql online document- PREPARE》
《分布式 | 中间件是如何处理 Prepare Statement 和游标的》