开放透明是我们信仰的核心价值之一
这两天,代码储存的服务商 Gitlab 出了个大新闻,刚好最近两个星期都在看 Git 相关的资料。在试用了 Github 和 Gitlab 的服务后,鉴于目前我的使用需求,最后是在虚拟机上开了个 Ubuntu 16.04,然后装了 Gitlab CE 版本。
回过头来说说 Gitlab 的大新闻,简单说就是同Linux 用户执行了那个知名的删除全部的命令一样,把整个生产平台上的数据库给删掉了,没有全删完,发现的时候总共300GB的数据,就剩下4.5GB了。就同完全删除没有什麽区别了。
出问题,或者说出现人为的故障都并不可怕,可怕的是用户完全不知情,被蒙蔽。 Gitlab 在处理这次危机的时候,做的非常漂亮,虽然并不能完全从故障中无损的恢复,就过程来说,是完全的透明开放的。让用户,让使用者有充分的知情权。
回顾一下这个过程。
故障一
2017年1月31日 6PM UTC,起初只是发现有 spammers 对 snippet 的频繁操作让数据库不稳定。他们开始寻找问题所在并试图解决它。
2017年1月31日 9PM UTC,情况更加严重了,导致数据库写操作被锁,间接的就宕机了。
Gitlab 执行了这些操作:根据IP地址阻挡 spammer;删除了一个用户,该用户把一个库当成CDN来使用,造成47000个ip地址同时登入账号(造成数据库高负载);把反复创建snippets的spammer 删掉。
故障二
2017年1月31日 10PM UTC, 他们收到消息,数据库复制操作落后太多,导致复制停止。看上去是 db2 的写操作出现问题。
Gitlab 采取的措施:试图修复 db2,这时 db2 大约落后4GB的量;之后就是一系列的调整 PostgreSQL 的参数,db1 同 db2 之间的同步始终无法恢复。这时 tm1 说要下班,当时他当地时间已经过了23点了,但是因为这个突发故障,就继续工作了。
故障三
2017年1月31日 11PM UTC,tm1 认为不能同步的问题,可能是因为 pg_basebackup 拒绝工作的缘故,决定删除该目录,几秒钟后他发现他是在 db1.cluster.gitlab.com 上操作,而不是在预想的 db2.cluster.gitlab.com。
2017年1月31日 11:27PM UTC, tm1 终止了删除操作,但是已经太晚了,300GB数据只剩下 4.5GB了。
在这个时间点上,Gitlab把网站下线,并且在 Twitter上公布了消息。
事情的前因就是这样。在错误的服务器上执行了删除操作。工作时间过长,导致的眼花,手抖。
之后的事情就开始透明报告了, Gitlab 在 twitter 上不断报告调查的情况,之后直播恢复的过程。
tm1,tm2,tm3 是工作人员。
在恢复过程中主要遇到的问题。
- LVM 默认的快照,24小时一次。 tm1 搞好在故障前6个小时手动做过一次。
- 常规备份也是24小时一次, tm1 一直没有找到备份的所在。根据 tm2 检查,常规备份失效,只有几个字节。
- tm3: pg_dump 失效,原来应该用 PostgreSQL9.6的,却实际上运行的9.2版本。
- 在 Azure 的磁盘快照是由 NFS 服务器默认的,但是并不包括数据库。
- 同步数据到 staging 服务器的过程会去掉 webhooks, 除非从最近24小时的常规备份中能恢复这些 webhooks。
- 复制的过程非常脆弱,很容易就出错,文档记录也不好。
- 备份到 S3 的设置显然也不工作,目录是空的。
- 总之,五种备份措施,都没有用。
- 最后从一个6个小时前的备份中恢复。
恢复的过程如下:
- 2017年2月1日 00:36 备份 db1.staging.gitlab.com 数据
- 2017年2月1日 00:55 挂载 db1.staging.gitlab.com 到 db1.cluster.gitlab.com
- 复制数据,从 staging 服务器的 /var/opt/gitlab/prostgresql/data/ 到生产平台的的相同目录
- 2017年2月1日 01:05 nfs-share01 服务器被指定为临时储存给 /var/opt/gitlab/db-meltdown/
- 2017年2月1日 01:18 复制剩下的生产数据。
- 2017年2月1日 8:54 PST 数据库的数据都恢复了。恢复的过程在 Youtube 全程直播约8个多小时。
- 2017年2月1日 9:49 PST 在1月31日 17:20 UTC 之前创建的 webhooks 都恢复了。
- 之后 恢复复制以及调整了数据库的设置。
- 删除了800,000个垃圾 snippets。
到目前为止,主站 gitlab.com 是 302 跳转到 about.gitlab.com 的,已经可以常规的操作了。
有一些有趣的对话,我想贴在下面,蛮有意思的。
* Who did it, will they be fired?
Someone made a mistake, they won't be fired.
* Why is the restore so slow?
We're limited by the disk speed of a non-production machine.
* Size of the DB?
310GB
* What is your stack?
Ruby on Rails with some Go. Postgres and Redis.
最终的影响:
- 6个小时的数据损失。
- 大约 4613个项目,74 forks,以及350个imports 丢失了。
- 大约 5000个留言损失。
- 707个用户丢失。
最为有意思的一条 tweet,后面的回复大多很正能量,我想这应该就是开放透明的告知用户,对于恢复用户信心非常重要。
We accidentally deleted production data and might have to restore from backup. Google Doc with live notes https://t.co/EVRbHzYlk8
-- GitLab.com Status (@gitlabstatus) February 1, 2017
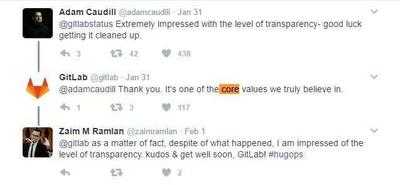 Transparency is one of the core values we truly believe in. --- Gitlab
Transparency is one of the core values we truly believe in. --- Gitlab
G2links Web Directories