Obsidian聚合显示包含关键字的段落
出于本机存储优先的需要,一直在用Obsidian做工作和个人笔记。我个人习惯的工作记录总是从每日笔记开始,每天的记录比较符合实际而且大大减轻脑负担,记录的时候不用多想这一点要怎么整理。但是每日笔记也会造成一些大跨度的项目中,信息是分散在每天的md文件里,不利于持续跟进工作。常见的解决方法应该是对项目中的关键词建立双链,每天还应该按方法论回顾笔记,从而将关键信息提炼出来写回或者是引用进项目单独的文档里。在Obsidian里对链接文件只是显示链接和一行的概要,不能直接使用,还得靠时候整理。可是人都是有惰性的,记得多、回顾整理少,甚至整理困难症,估计不止我一个,哈哈。
于是经过一番搜索,发现主要的思路是用Dataview这个插件,配合比如tag或者是类似字典数据的方式,来实现聚合看板的功能。tag感觉对每日笔记的形式并不太适合,因为每天的记录里往往夹杂着不同项目在当天的推进情况,如果打上多个tag,后期筛选使用比较麻烦。而用字典数据的方式,比如会议:: 部门周例会这样总是怪怪的,要改变个人记录习惯。最终,我把这个问题抛给了perplexity.ai,它居然真的反馈了用dataviewjs编写的脚本。起步是可喜的,但是调试过程是痛苦的。一方面我不懂js,另一方面perplexity的数据来源似乎比较多,dataview又毕竟不是一个非常严谨的项目,perplexity对dataview里函数的调用反复出现问题。一番研究后发现,似乎是某些方法在最新的dataview里已经不支持了,或者是perplexity一开始就理解错了功能。它在做搜索筛选的时候尝试了file.content.includes()、app.vault.read(),结果实际都没能成功读出文档。最后还是经过我自己的搜索,明确提示它用dv.io.load(),才解决了读文档内容的问题。(前面两个方法在dataview里编译是正常的,无法读文档的原因反正我是没搞懂了)
最后的脚本先贴一下吧:
const searchTerm = '关键字';
const currentFilePath = dv.current().file.path;
function extractRelevantContent(content, searchTerm) {
const lines = content.split('\n');
const results = [];
let isCapturing = false;
let captureLevel = 0;
let currentSection = [];
function getHeaderLevel(line) {
const match = line.match(/^(#+)\s/);
return match ? match[1].length : 0;
}
for (const line of lines) {
const headerLevel = getHeaderLevel(line);
if (headerLevel > 0) {
if (isCapturing) {
if (headerLevel <= captureLevel) {
// 遇到同级或更高级标题,停止捕获
results.push(currentSection.join('\n'));
currentSection = [];
isCapturing = false;
} else {
// 遇到低级标题,继续捕获
currentSection.push(line);
}
}
if (line.toLowerCase().includes(searchTerm.toLowerCase())) {
// 找到包含搜索词的标题,开始捕获
isCapturing = true;
captureLevel = headerLevel;
currentSection = [line];
}
} else if (isCapturing) {
// 捕获标题下的内容
currentSection.push(line);
}
}
// 处理文档末尾的情况
if (isCapturing && currentSection.length > 0) {
results.push(currentSection.join('\n'));
}
return results;
}
// 搜索整个文档库,排除当前文档,并按创建时间倒序排序
const pages = dv.pages('')
.where(p => p.file.path !== currentFilePath)
.sort(p => p.file.ctime, 'desc');
//dv.header(1, `包含 "${searchTerm}" 的章节(按创建时间倒序)`);
let matchedCount = 0;
for (const page of pages) {
try {
const content = await dv.io.load(page.file.path);
const relevantSections = extractRelevantContent(content, searchTerm);
if (relevantSections.length > 0) {
matchedCount++;
dv.header(3, `${page.file.link}`);
for (const section of relevantSections) {
dv.paragraph(section);
}
}
} catch (error) {
console.error(`处理文件 ${page.file.name} 时出错:`, error);
}
}
dv.paragraph(`共找到 ${matchedCount} 个包含 "${searchTerm}" 的文件。`);
最终的效果是,在当前文档库里搜索包含关键字的文件,并将该关键字所在段落及子段落(按标题的级别分段落级别)汇总显示出来。显示时按文件的新建时间排倒序,也就是比如开部门例会,会按最近的会议记录在最上面依次排列下来,文件名同时是可点击的链接。具体使用方法就是安装Dataview插件后,新建一个.md文件,把上面代码按dataviewjs的方式贴进去,修改第一行关键字就行了。
大概的效果可能是下面这个图这样。
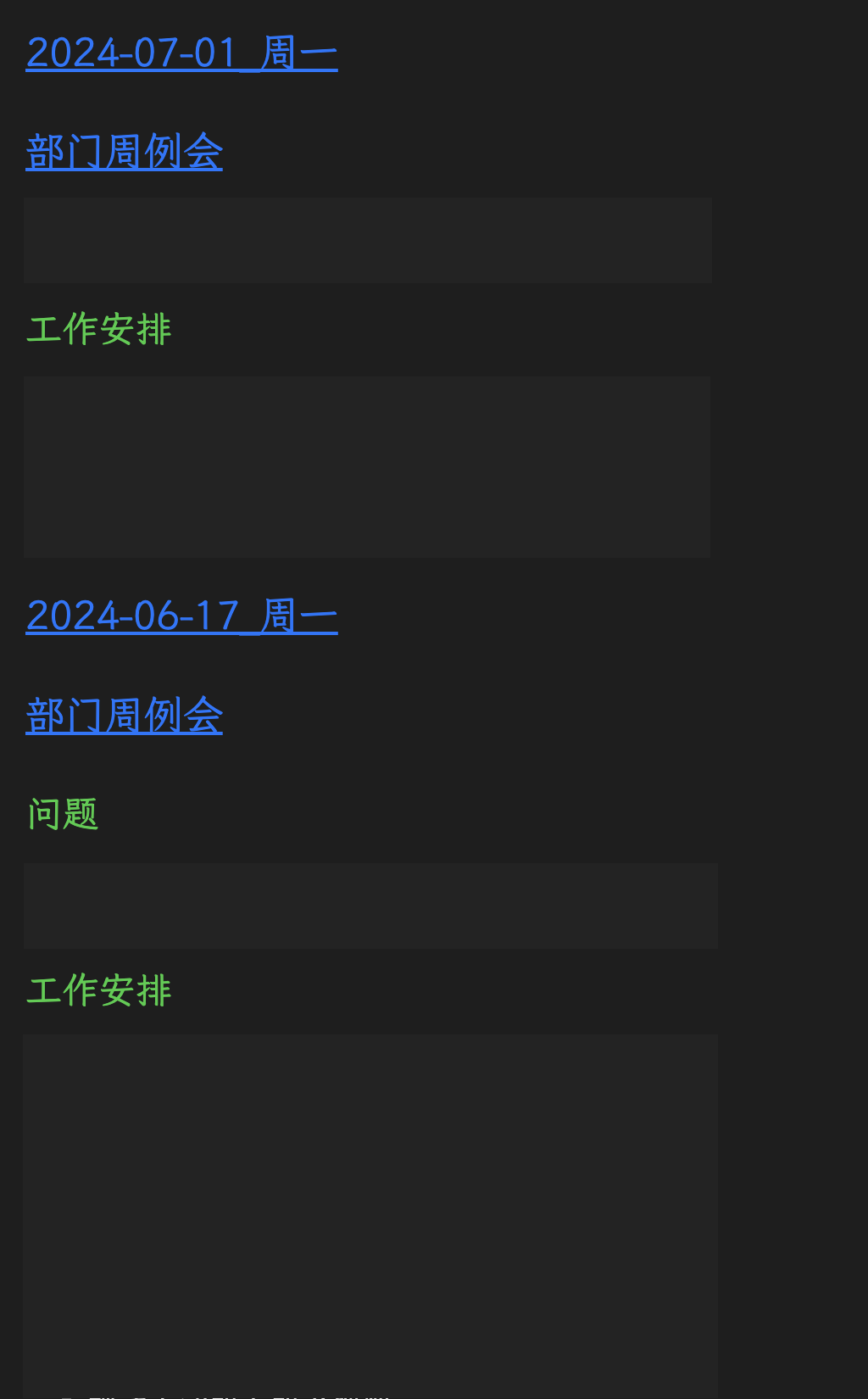
全文搜索的实现方式似乎有点低效,但目前在我一个有过百每日笔记的库里,跑起来没什么感觉,内存占用也没什么感知。具体效率如何,还有待长期观察了。
最后,在大概明白原理的情况下0语法基础写代码还是可行的,perplexity.ai的能力不错,AI几乎就是直接能跑的起步。但是它对互联网信息时效的理解还是没能跟上(网上搜到的代码也确实很多不能跑了),debug挺痛苦。