如何提高大模型的确定性
在大模型时代,如何提升 AI 生成内容的确定性?本篇文章将深入探讨影响 AI 生成稳定性的关键因素,分析当前技术挑战,并提供优化策略,帮助产品经理打造更可靠的智能交互体验。

提高大模型确定性的通用方法
由于我们日常的使用大模型是通过对话的方式,我们的核心方法只能是建立在不调整大模型参数的状态下力求更好的答案,所以就是苦修提示词。提高提示词能力的细节方法。
- 提高你的认知深度和拆解能力,从而把让你的提示词足够具体。让大模型自由发挥的框被限定在一个很小的范围内,你要不断地追问自己,你要的结果到底是什么?【主题/内容风格/格式/要用到的思维方式等】比如用cursor创建代码,你如果可以清晰要使用的框架和技术等,那么大模型的生成就不会混乱。
- 引导模型一步一步思考,常见框架是:首先研究问题的核心和本质,然后基于问题去搜索大量的相关优质信息,总结相关信息,然后给出几个优质的解决方案和优缺点,然后选择一个最好的解决方案。
- 给模型设定角色和给一些引导和示例,这样打模型寻找搜索相关信息和参数就会与你设定的信息和示例进行匹配。
- 让自己对于结果好坏有一个较客观的评价标准,然后去迭代自己的提示词,提示词不是一蹴而就的,一个好的能够提高很多人效果的提示词需要不断地迭代测试。
我们在学习写作提示词的过程中也要参考别人的优秀的提示词,从而却理解别人的方法和内在逻辑,去更快的迭代自己的提示词。
还有一些很好的工具可以帮助我们迭代提示词。https://prompt.always200.com/
提高大模型确定性的超参数优化法
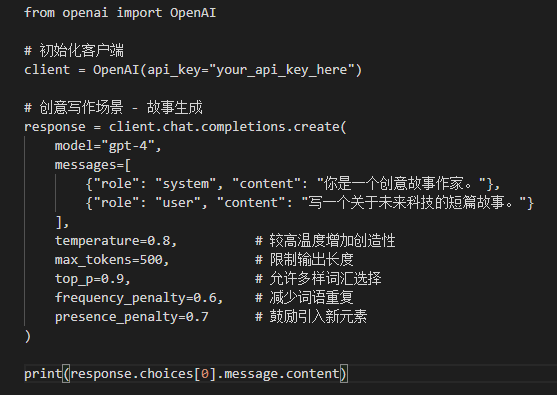
我们可以通过API接入直接调整大模型的参数,只需要简单的调整就能让大模型本身发生一些变化,下面我们介绍几个核心的超参数(人为可以设定的参数)。
1. temperature(温度系数)
取值范围:0-2
原理:控制输出的随机性和创造性。温度参数就像一个旋钮,调整概率分布的形状。低温使概率分布更尖锐,高概率词的概率更高,模型更倾向于选择最可能的词;高温使概率分布更平缓,模型更可能选择不常见词。
设置建议:
- 0-0.3:适合事实性回答、代码生成等需要精确性的场景
- 0.4-0.7:平衡创造性和一致性,适合一般对话
- 0.8-1.0:适合创意写作、头脑风暴等需要多样化的场景
- 1.0以上:产生更随机、可能不连贯的输出(谨慎使用)
2. top_p(核采样)
取值范围:0-1
原理:限制模型只考虑累积概率达到top_p值的最小词集合,从这个动态大小的词集合中采样。当top_p为0.1时,模型只会从累积概率达到10%的词库中选择下一个词。
设置建议:
- 0.1-0.3:适合精确的、确定性强的回答
- 0.5-0.7:适合一般对话
- 0.8-1.0:适合创意生成
3. frequency_penalty(频率惩罚)
取值范围:-2.0到2.0
原理:减少已出现词语再次出现的概率,控制重复程度。频率惩罚会根据token在生成内容中出现的频率来惩罚,出现次数越多,惩罚越大。值越高,模型就越不可能重复使用同一词语。
设置建议:
- 0:不惩罚重复
- 0.5-1.0:减少重复,增加多样性
- 负值:增加重复(特殊场景下使用,如需要强调某些概念)
4. presence_penalty(存在惩罚)
取值范围:-2.0到2.0
原理:减少所有已出现过的token再次出现的概率,无论出现次数多少。与frequency_penalty不同,presence_penalty只关心token是否出现过,不考虑出现频率。值越高,越可能引入新话题和新内容。
设置建议:
- 0:不惩罚已出现内容
- 0.5-1.0:鼓励模型引入新内容和话题
- 负值:鼓励重复已有内容(特殊场景下使用)
5. logit_bias(Token偏好)
取值:{token_id: bias}字典
原理:增加或减少特定token出现的概率,bias值在-100到100之间。正值增加概率,负值减少概率。
设置建议:用于鼓励或禁止使用特定词汇,需要先通过tokenizer获取词汇对应的token_id。
6. response_format(响应格式)
取值:{“type”: “text”} 或 {“type”: “json_object”}
原理:指定模型生成的内容格式,尤其是需要结构化数据时很有用。
设置建议:需要结构化数据时使用JSON格式,可以大大简化后续处理。
其他方法:选择更好的大模型
如何选择大模型,也是需要仔细思考的。
1.通过自己的业务场景判断
通过看自己的业务对应的是大模型哪一个方面的能力,数学/推理/代码生成。不同模型往往是各有所长,claud-3.7-sonnet可能代码生成能力较强。Gemini-2.5可能推理能力较强。所以要去思考自己的业务属于哪些方面,再从细分的方面去找最强的模型。
2.看评价方式和测评重点
有些是通过数学题目,有些事测评各个领域的知识,有些甚至考的是博士题,那么根据你的业务场景要去思考,你到底是要一个各个领域知识都懂的大模型,还是需要解决搞复杂性的数学题目和博士题目,还是要代码生成能力。同时也要参考英语考试和中文考试
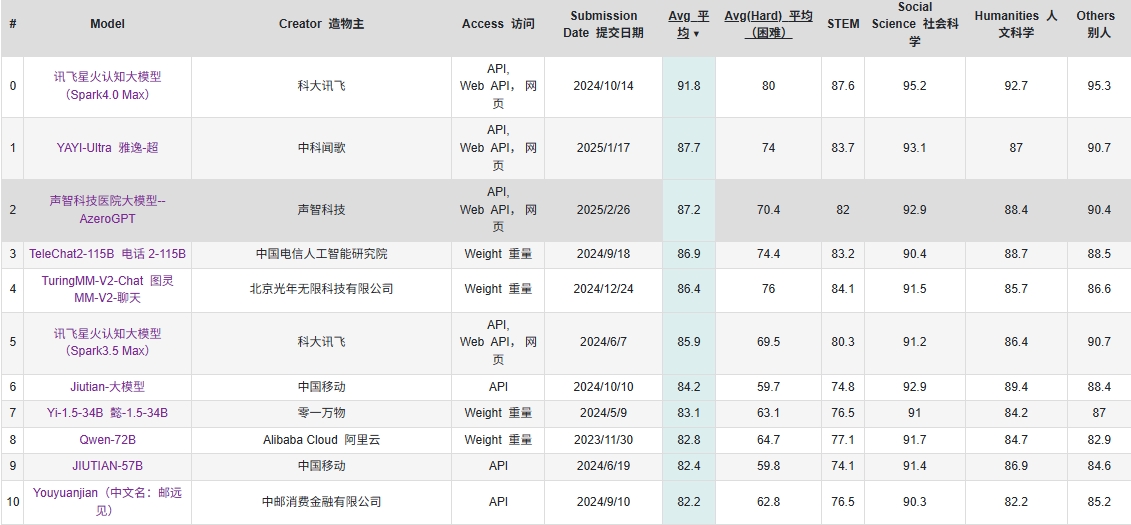
比如下面这个中文的测试 CEVAL https://cevalbenchmark.com/static/leaderboard.html
3.对于自己的业务问题做AB测试
发送同样的提示词给不同的大模型API,然后通过脚本不断地传输这些问题,让大模型反复出答案,最后对于问题有一个excel表格,然后人工对于这些问题的答案做打分,从而得出更好的大模型。
本文由 @青阳-AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务