开放宇宙、企业家与挨千刀的概率论

长文慎入。
这一天,阳光明媚 。某幼儿园大一班经济学知识竞赛女子组正在如火如荼地进行着。贾佳小朋友已经PK掉了一起参赛的易依、邴冰冰两位小朋友,如果再能回答对下面三个问题,她就能获得冠军,奖品是一枚上写着“你真棒”的小红花和一整盒大大泡泡糖。
此刻,贾佳小朋友呼吸急促,一滴汗珠顺着后脖领子一直流到屁股上。
“请听题:何谓厂商的市场势力?”
“如果厂商具有一定的定价权,那么它就有市场势力,有市场势力的企业才会面对一个非水平的需求曲线,这也是厂商获得非零利润的必要条件。”
“回答正确。不过要提醒你哦,纯粹垄断的厂商没有需求曲线哦~”
掌声中夹杂着易依和邴冰冰的冷笑声,意思是,输给你这个只看过曼昆的人真是羞耻,老娘可是研读过MWG……的目录的人呐。站在旁边的本届本赛顾问,著名经济学家朱明心中暗说:“文人相轻,还得从娃娃抓起啊!”
“请听第二题:市场势力可以帮助企业获得利润,那么这种利润是正义的吗?“易依对邴冰冰说,“哼,这是MWG第一章就讲过的,这个小狐狸精肯定不会。”
邴冰冰说:“姐,MWG第一章讲得是偏好与选择,那目录咱俩一块儿看的,别蒙我。”
”怎么,你居然帮小狐狸精说话,你前男友丁鼎不是被她抢走的啊!“远处角落里的丁鼎小朋友打了个喷嚏,然后用手背抹了一下流出来的鼻涕。
贾佳:”这个问题……嗯,如果是寻租行为导致的市场势力,当然是不正义的,比如说,中……“
”好了,直播呢,请遵守知乎的规定,你就说不是寻租行为的吧。不信,你听……“主持人额头渗出豆大的汗珠。
”企业获得正利润有时候是正义的,那就是,企业家负责在市场中创新,比如乔布斯的苹果公司就革新了移动设备,获得了垄断地位,那么如果政策制定者相信垄断无论如何都是不正义的,拆分了乔布斯的公司,那以后还有谁每天呕心沥血研究怎么给消费者更好的用户体验呢?那以后iPhone除了变大还会有什么进步呢?“
掌声经久不息,在座的观众们轻抚着身旁的iPhone20,据说这款手机可以当电热毯用。
“总而言之,不能因为企业优秀就说它不正义。”
易依小朋友偶然摆头看见邴冰冰惊叹得下巴已经快要脱臼了,翻了个白眼,酸溜溜地说,”哼,小狐狸精,你知道什么叫塔吉克定理吗?“
邴冰冰猛然醒神,赶紧打断,说:“姐,别出洋相了,那叫Kuhn-Tucker定理,塔吉克是个国家!”
“请听第三题,答对这个问题就可以拿到小红花了哦:曾几何时,企业家与利润的关系是若干古典经济学大咖们最喜欢讨论的问题,为什么到了现在这个问题很少被人研究了?”
“因为概率论这个数学神器把经济学家们骗了,他们觉得,搞定不确定性与经济学的交叉只需要找一本儿本科水平的概率测度课本就齐活了,他们太天真了。”
“回答正确,加十分。”
雷鸣般的掌声。易依和邴冰冰留下了悲愤的泪水:“贾佳,以后再也不和你玩儿了!”
“请我们的顾问著名经济学家朱明教授点评。”大家此刻还不知道,朱明教授曾经以为概率测度这种高深的数学知识只有自己知道,今天他才发现本科生就有概率测度的课程。
朱明:“你给我讲讲,什么叫西格玛-艾奥摘不拉!我就不信你能这么牛!”
”啥玩意儿?“贾佳毕竟是东北人,”如果你说的是代数的话,那就是满足……性质的一个集合类啊!你个山炮。“
朱明教授当场吐血,在座的小朋友此刻脑海中浮现出一个历史人物——文状元对穿肠。只有易依冲上前去……
”爸爸,爸爸!爸爸我错了,我不该跟妈姓!爸爸……“
遗传学万岁。
一、关于概率测度理论的一点科普
这篇文章是想举出一个关于”数学是如何谋杀经济学“这个经济学票友们非常喜欢的论断的例子,不过,笔者从来没有认为数学就没用以及学不会数学就可以做经济学研究。抱歉,跟你们不是一个战壕。
这一节我准备先科普一下概率测度的知识,给那些没有数学背景的读者,有的话请跳过,怕被你们挑出错来……
令表示任意一个集合,其中的元素
(咦好神奇啊知乎的公式编辑居然和Latex是一样的耶!)表示一个”随机结果“。这里对这个随机结果的要求是对逻辑或运算”不可分“。举个例子,扔一枚骰子,那么有
,那么”骰子的点数是1“就是一个随机结果,而”骰子的点数小于5“就不是,因为它可以被拆解成”点数是4“或”点数小于4“。
记为集合
全部自己的全体,比如,如果
,那么
这东西一般被称作的幂集,什么味道?里面的元素通常被称作一个事件。
定义:事件是一个
-代数(西格玛-艾奥摘不拉),如果:
,
- 如果
(也就是说
),那么
,
- 如果可数事件序列
满足
对任意自然数n都成立,那么
(如果只要求有限多个就叫Booglean代数。)
定义:给定任意一个
,
,
- 对任意至多可数的事件
,满足对任意
,
,有
有人说,妈蛋,概率不就是频率的极限吗!整这么复杂干嘛呀!你们数学家自娱自乐!还要祸害我们经济学家!
这里面问题多了去了。
频率的极限叫做”概率的古典定义“,另外还有概率的”几何定义“,眼熟吗?是不是想起了高中数学?这两种定义都有问题,不细说了,以下摘自百度贴吧,懒得写了
在这种背景下,柯尔莫哥洛夫于1933年在他的《概率论基础》一书中第一次给出了概率的测度论式的定义和一套严密的公理体系。这一公理体系着眼于规定事件及事件概率的最基本的性质和关系,并用这些规定来表明概率的运算法则。它们是从客观实际中抽象出来的,既概括了概率的古典定义、几何定义及频率定义的基本特性,又避免了各自的局限性和含混之处。这一公理体系一经提出,便迅速获得举世的公认。它的出现,是概率论发展史上的一个里程碑,为现代概率论的蓬勃发展打下了坚实的基础。
记住这个时间点,1933年。
二、奈特不确定性
翻开任何一本关于金融、风险控制和保险的初级教科书,老先生们会告诉你,当未来有不被偏爱的结果发生的可能性时,我们就有“危险”,而当危险的概率分布已知时,危险也叫做风险。换言之,风险是一种对关于危险的知识有充分掌握的状态。
一个问题:人类一开始是怎么知道扔一枚硬币某一面出现的概率是0.5的?
这个问题往根儿上说涉及到了康德经验主义和休谟经验主义的区别:人类的知识到底是演绎出来的还是归纳出来的?
不过,也可以这样回答:结合流体力学的知识,抛硬币的结果是敏感地依赖于抛硬币的人给的初始力的大小和方向的,而由于发力是高度随机的,所以结果就是一个“确定性混沌”。不过这个解释比较牵强,因为毕竟流体力学和混沌理论的成熟最远也就是近一百年的事情,远远晚于人类知道硬币结果的概率分布是一个以0.5为参数的伯努利分布。
所以,只有一个答案:做实验。可能历史上真的有人吃饱了饭没事儿干扔了几百次发现确实有这样的规律,虽然那个人真的挺无聊的。这种实验的特点是保证每次重复都满足独立同分布——哪怕只是稍微掌握了一点粗浅的计量经济学(比如我),就不难发现,要估计一个静态概率分布的未知参数,我们对样本的要求是:独立,同分布。
这就是所谓的概率的古典解释:概率是频率的极限。人们可确知的是频率,通过重复实验得到随机样本的频率,当样本足够大时,频率因大数定律收敛于概率。现代统计学和计量经济学就是根据这样的逻辑构建起来的。
那么,有一个自然的问题:这种频率收敛于概率的逻辑是否穷尽了人类关于不确定性的全部知识?不禁要问,当盖茨决心辍学设计windows系统之前,他知道这个系统能给他带来多少财富吗?肯定不知道,这个产品有不被市场接受的可能性,也就是说,他面临不确定性或者“危险”。
那他知道通过这个系统所能挣到的财富的概率分布吗?或者说,他有知道这个概率分布,即获取知识的可能性吗?
经济学家认为,人类有三种获取知识的方式:主动获取、被动接受、有意试错。
那么,他能花钱找人告诉他结果吗?不能,除非他相信算命先生,否则没有人比他自己更清楚windows的市场价值。
他能被动等待别人设计出windows然后看结果吗?不能,一来可能也没有什么人能够设计出一个一模一样的东西,再者就算有了你也只有一个样本点,拿一个样本点做回归,到学术会议上早让人喷死了。
有意试错呢?肯定也不行,因为这个东西是不能够做实验的。他不能涉及并发表windows五千次,构成一个大样本,然后统计出概率分布,再决定是不是设计windows。首先,连续实验五千次是不可能的,因为市场上有windows时windows的销量,与没有windows时的销量肯定不是独立同分布的。再者,他受限于时间的不可逆性——盖茨不能穿越到未来五千次,看结果然后再穿越回来决定是不是做这件事。
这就是企业家面临的独一无二的核心问题:企业家的核心职能是为创造,为了获得超额利润,企业家必须原创性地做出能够满足消费者欲望的产品。这个产品必须是别人没有想到过的,企业家才能获得由于其原创性而获得的租值。而创造性行为,不能够做实验,一旦实验过了,idea就不是原创的了。
这就是芝加哥学派的鼻祖Frank Knight在1921年的那部《风险、不确定性与利润》当中区分风险和不确定性之间的关系所基于的知识背景。Knight从而论证,企业家在市场中获得高额利润,并不只是因为他们承担了市场活动的风险(事实上哪怕股民也承担着风险),而是因为他们承担了创造性活动的不确定性,这种不确定性是不可能知道概率分布的,因为创造性活动不可能做实验。
后世的经济学家管Knight定义的不确定性作“奈特不确定性”。
奈特不确定性解释了为什么乔布斯这样的人,即便在市场中获得了“不合理”的报酬,但依然是推动社会进步的力量。这也解释了政府为什么不能对垄断企业的暴利持无原则的对抗态度,因为这将扼杀原创的精神。这个观点就是贾佳小盆友答题时所说的。
当然,有人会问:如果一个人试图成为企业家的努力是在“奈特不确定性”的基础上做出的,那么企业家们成功与否是不是主要取决于运气呢?
答:不好意思,就是这么回事。所以企业家的个人传记和演讲我通常不看。
引用阿尔钦1950年那篇著名的“不确定性、演化和经济理论”里面的观点:引入不确定性后,“利润最大化”作为行动指南的意义就没有了,企业也有了一个所谓的“均值-方差”效用函数。但这篇文章接下来的两个标题弥补了这里面的逻辑缺憾,他说:“判断成功的标准是结果而非动机”,“运气是实现成功的手段”。所以说,企业家的行为是否成功是基于他的创造是否偶然间契合了市场的需求,市场上的达尔文过程能够筛选出谁成功。关于这一点,初学者可以去买一本《当经济学遇上心理学和生物学》作为科普。
去年JEP上的一篇文章综述了关于企业家收入的一系列研究,结果和很多人的直觉相左:企业家的收入分布是具有极高偏度(Skewness)的,正所谓“张村有个张千万,旁边九个穷光蛋”,企业家是一个成材率极低的职业。平均来看,在美帝,自我雇佣的劳动力的平均收入低于为别人打工的劳动力,超过50%的新盈利机构(当然也算上了小区里买冰棍儿的大妈)都挺不过5年。
那么,看起来,企业家有超额利润这件事似乎不成立:是否他们的暴利只是因为他们运气好拿到了风投的钱,又运气好获得了成功?
显然不是,因为决定自我雇佣,也就是有勇气在奈特不确定性存在时冒险,是能够碰触这种好运气的先决条件,一辈子委身体制内的人永远没有这种运气。虽然暴利来自运气,但拥有好运可能性的先决条件是企业家敢于挑战奈特不确定性。
当然,人们为何喜欢这种有极大偏度的收益分布,是行为经济学家的工作。比较靠谱的理论是Quiggin在1982年提出的排序依赖的期望效用理论。
总结:企业家的超额利润=市场对不畏奈特不确定性而敢于创新的勇气的奖赏+市场对好运气或者毫无理由的远见的奖赏。
其中,勇气比运气更重要。
三、贝叶斯决策理论与埃尔斯伯格悖论
细心的读者应该已经注意到一个问题:Frank Knight的理论提出于1921年,柯尔莫哥洛夫的现代概率测度体系建立于1933年,也就是说,当Knight提出自己的理论时,他本人并不知道概率论还可以这么玩儿。
换言之,Knight所理解的概率还是“频率的极限”。
那么,是不是奈特不确定性可以被现代概率测度公理体系解决掉呢?
在这个问题上,有一些经济学家曾经做出过一些早期贡献,其中就包括了天妒英才拉姆齐和鲜有人知也是概率论专家的凯恩斯。不过,这个问题真正被彻底数学化是1954年萨维奇的贡献。
跑个题:事实上,长期以来,人们对概率就有两种截然不同的理解,一种叫频率主义,另一种叫贝叶斯主义。
大家学的计量几乎都是频率主义的东西:假设存在一个真实的参数,比如消费者对汽车和电瓶车的替代弹性,然后通过样本去估计这个参数。
贝叶斯主义不同,贝叶斯统计学家从来不认为这个真实的参数存在,他认为这东西最多只是一个概率分布,然后样本构成了进行贝叶斯推断的信息。
可是,做任何一个推断都是一个“后验概率”,都需要一个“先验概率”作为基础。通常,如果我们在处理数据之前对这个分布一无所知,统计学的惯例是取一个均匀分布(因为经济学中的变量多数是连续变量,如果是类似于计数变量一般取多项分布)。
要我说,这么做多少有些懒,如果我们不认可先验概率是均匀分布,那么,最早的那个“先验概率”从何而来?贝叶斯学派的数学家们会告诉你,这玩意儿是主观的。
因为先验概率的选取,如果样本不大,会影响最终的推断,所以贝叶斯推断是一个十足的主观的东西。这也是两大学派上百年痛快撕逼的根源。
为什么要跑题说贝叶斯概率论,因为拉姆齐、凯恩斯和萨维奇的努力恰好是要把概率主观化,核心的假设是人们拥有一个高于传统理性概念的“贝叶斯理性”。
在萨维奇的那本《统计学基础》中,他原创性地将“行为”定义为一个从“外在状态”集合到结果集合
上的映射。这样,如果行为集合上的偏好
满足七个公理,其中包括“臭名昭著”的sure-thing principle,那么就可以找到一个概率测度
和一个Bernoulli效用函数
,使得对任意一个行为
和
,有
这就是著名的“主观概率期望效用理论”(SEUT)。Kreps在《决策理论讲义》里面评价这个模型:他应用于全部概率都是主观的情况。而到了1960年代,Anscombe和Aumann发展了这套理论,把行为定义做到
上的全部概率分布
的映射。因为集合
是一个线性空间,因而新理论的公理化建构变得特别简单,而且里面不仅有主观概率,也有客观概率。也就是说,
其中是当自然状态
实现时
的概率分布。
现代决策理论最基本的理论框架就是Anscombe-Aumann体系,想了解的朋友可以参阅MWG,6.E-6.F,或者Kreps(2013),第五章。
萨维奇和A-A体系暗含了所谓的“贝叶斯理性”,这算是主流经济学对奈特不确定性的一种回应:虽然人不知道某个事件出现的概率,但是人有足够的理性可以对任何一个事件发生的可能性有一个估计,而且这个估计,作为一个测度函数,满足一个概率测度的所有要求。
应用在我们上面说的企业家与创新问题上,盖茨虽然不知道Windows给他带来的财富的客观的概率分布,但是他对这个分布有一个主观的预测,并根据这个主观预测行动。换言之,盖茨一定是主观地认为windows系统能让他过上非常好生活的概率极大,他才会这么做,尽管这个估计可能是没有任何证据支撑的。
这套理论就叫贝叶斯决策理论。
至于这个主观概率是怎么来的,决策理论家和经济学家表示不care,经济学要做的是给定偏好,看约束变动如何影响行为,而不是给定约束看偏好变化怎么影响行为(心理学),更不是做“偏好的起源”这种生物学研究。究竟这个主观概率的决定是生理结构决定的、是文化决定的、是冲动和情绪决定的,还是像我现在做的研究那样把它看做一个效用最大化问题的解,正统经济学家是不管的。Martin Perterson在他的书的开篇写道(译文,括号里面是吐槽):
”不久之前,一个我女神向我求婚。我惊呆了。结婚?现在?你特么在逗我!忒早了吧!我还没到四十岁呢亲!(歪果仁的婚恋观)但是,因为这样那样的原因我决定不把我自己阴暗的直觉反应告诉她(肯定是怕拒绝了之后炮友都没得做呗)。我说本屌有点儿乱,虽然我特惊喜,但是我需要缓缓。第二天一大早我踏上了冲向学校图书馆的路。我借阅了所有我能找到的决策理论的书。当天下午我已经对现代决策理论是个神马东西大概了解了,然而并没有什么卵用,我还是不知道该怎么回复她。(注定孤独一生……)“
这段文字直击了贝叶斯决策理论的软肋,它不能交给人们如何决策,或者说如何形成主观概率。经济学家们做的是:不管主观概率是怎么来的,只是假设这个东西存在。
但是,贝叶斯决策理论里面有一个问题,就是在这套理论里面,所谓风险和奈特不确定性没有什么区别,唯一的区别是概率到底是主观的还是客观的。因为期望效用这个依概率线性的效用函数形式没变。显然,如果奈特不确定性真的存在,贝叶斯决策理论就是不够的,反过来,如果贝叶斯决策理论正确,奈特不确定性就不存在。
打破这个坚冰的是一位叫做埃尔斯伯格的经济学家,他做了这样一个实验(下面的版本轻微改编过):
假设你有一个筐,里面有总共90个球,如果任意拿出来一个,他可能是红的,可能是黑的,也可能是黄的。现在已知有三十个红球,但黑球和黄球的数量未知(奈特不确定性)。
给你两个GAMBLE:
- A:取出红球得100刀,取出其他颜色的球没有奖励;
- B:取出黑球得100刀,取出其他颜色的求没有奖励。
如果你和大多数人的选择一样,你会选择A,根据SEUT,或者说根据sure-thing principle,你这样选择说明你主观上认为黑球的数量不到三十个,这是因为取出红球的概率是已知的0.3333……。有兴趣的朋友可以拿上面那个式子自己验证一下。
好,那么,再给你两个选择:
- C:取出红球或黄球得100刀,取出黑球没有奖励;
- D:取出黑球或黄球得100刀,取出红球没有奖励。
如果你再次和大多数人的选择一样,你会选择D。那么,知道sure-thing principle是什么的人应该看出问题了,因为如果选择D,那么根据SEUT,你一定是认为“黑球或黄球”的概率大于“红球或黄球”的概率。但因为取出球的颜色这个随机事件彼此独立,根据概率测度的可加性,实际上宣告了你认为红球的概率小于黑球的概率。
埃尔斯伯格的实验告诉我们,如果SEUT成立,你在不同的决策问题中对同一个随机事件的概率估计可能是不一样的!这构成了大名鼎鼎的埃尔斯伯格悖论,这激励了决策理论家在后面半个世纪的研究。
不过2011年已近人生晚期的埃尔斯伯格在一个会议上非常”贱“地说,”你们都误解了我的意思!“
脑补一下与会的经济学家们心中都有一万只XXX在奔腾的盛况吧。
四、模糊厌恶和信念的数学表达
埃尔斯伯格悖论问题出在哪?仔细看看上面给的ABCD四个选项,你会发现,A和D选项中你获得100刀的概率是已知的,分别是三分之一和三分之二,而B和C选项中这个概率是未知的。
于是,一部分人提出了模糊厌恶(Ambiguity Aversion)的概念:两个行动,一个概率分布已知,另一个未知,但有与第一个行动客观概率分布相同的贝叶斯先验,那么已知概率的行动更被偏爱。当然,这个定义并不那么严格,因为在经济学家看来,主观概率不可观察。在严格的决策理论文献中,经济学家通常会用一个叫做”对冲“(hedging)假设的东西代指不确定性厌恶,即两个行动的线性组合比单独某个行动更好。
自1980年代开始的二十年里,如何解释埃尔斯伯格悖论中表现出的行为倾向变成了决策理论当中一个不能再重要的课题。与此相关的A-A期望效用理论的替代性假设包括(下面所有的行动都按照A-A框架假设,其中
是集合
的一个客观概率分布):
- Max-Min期望效用理论:Gilboa and Schmeidler (1989)
这里集合是集合
上全部可能概率测度
的一个子集,可以从偏好中被识别出来。函数的意义是在一个概率测度集合里拿出每一个概率测度,算期望效用,然后取最小的那一个。当然这种偏好仅能刻画模糊厌恶的情形,如果是模糊喜好偏好,就把那个最小值函数改成最大值函数(Max-Max)即可。
- Choquet期望效用理论:Schmeidler (1989)
这里,函数表示一个
上的不可加概率分布,也就是说,独立事件概率的可加性在这里被放宽了。因为函数
不可加,所以就可以讨论凹凸性,说函数是凸的也就是说对任意互斥事件
,
。函数是凸的(凹的、线性的)当且仅当决策者是模糊厌恶(喜好、中性)的。
当然,也因为函数不可加,所以勒贝格积分不存在,这里外面的一层积分用的是Choquet(近似可读作”烧盖“,法语)积分,所以这个理论也叫Choquet期望效用理论。
- 二阶期望效用理论:Ergin and Gul (2009); Nau (2006); Neilson (1993)
这里相当于对已知概率分布的风险的期望效用作为自变量再求一次自然状态的期望效用,故名。这里,函数就是所谓的二阶Bernoulli效用函数,它是凹的(凸的、线性的)当且仅当决策者是模糊厌恶(喜好、中性)的。
- 微分期望效用理论:Maccheroni et al. (2006a)
其中,函数是一个在弱*拓扑下下半连续的凹函数。这个偏好的理论意义在于它解决了Max-min期望效用中集合
如何确定的问题,最小化只需要在全部概率测度集合而非其子集中找就可以了。
- 乘子期望效用理论:Hansen and Sargent, (2001)
这两位作者如今都是诺奖得主了。这个偏好又丰富了微分效用里面的函数,这里
是另一个概率测度,可以认为是一个”参考先验“,而函数
表示两个概率测度之间的相对熵。这个熵越大,概率测度
对应的函数值就越大,那么这个概率测度在最小化之后被选中的可能性就越小。好像两年前弊校另一个学院一位老师在《经济研究》上发表了一篇大概叫奈特不确定性与资产定价的文章,理论模型就是基于乘子效用。
- 信心效用理论:Chateauneuf and Faro (2009),
这个模型比较复杂,函数是概率分布
的”信心指数“,而指标
是一个概率分布被纳入考量所要求的最低信心标准。模型的含义是从所有概率分布中找到对这个概率分布信心足够大的那些,算出期望效用并除以信心,最后取最小的那一个。这里,信心越大,分母越大,那么这个概率分布就越有可能被选中。
好啦,亲爱的读者,如果你硬撑着看到了这里,我想请你思考的是:
第一,这些模型在挑战什么?我们重新看萨维奇 A-A体系,我们发现,”信念“这个描述我们”对事件可能性的主观判断“的概念,是用一个叫做”主观概率“的东西刻画出来的。而在上述模型当中,除了二阶期望效用,其他的理论中这个前提都被放宽了。比如,Max-Min、微分、乘子、信心四个理论中,信念是由一族概率测度,而非一个概率测度,而Choquet期望效用理论中,信念是一个不可加测度,而概率分布是可加的。
正是把”一个信念“和”一个概率“这两个概念分开了,模糊厌恶这种行为倾向才被完整地刻画了出来。这样,运用比较复杂的数学知识,决策理论家把信念这样一个极深刻的东西描述了出来。
第二,这些模型隐含地假设了什么?因为效用最大化这个形式依然保留着,也就是说,给定任何一个行为的集合,最优行为依然是通过
给出的。那么,决策者也就被假设是理性的,毕竟,理性人才会最大化。不过,Economics and Philosophy杂志一篇2009年的文章中,两位西北大学的经济学家指出,埃尔斯伯格悖论中体现出的行为是不理性的,例如,遵从这种行为会考虑沉没成本。更一般地,Hammond (1987) 年的经典文章证明,不考虑沉没成本当且仅当sure-thing principle成立,也就是说,SEUT成立。所以说,这些理论虽然在静态中是理性的,但放在动态(序贯决策)的角度看就是不理性的。
第三,也是最重要的:我们关于奈特不确定性的讨论走到这一步似乎得到完美解决了,风险和奈特不确定性被剥离了。金融中我们常常提到”溢价“这个词,那么对于任何一个溢价,我们已经可以把它分解成风险溢价和不确定性溢价了,很多人解释equity premium也可以用这个模型了,风险厌恶和不确定性厌恶可以独立发挥作用了,企业家的高收入可以解释了。
可是,有心的你应该会发现一个问题,在这一节中,我不顾可能造成的误解,刻意规避使用了“奈特不确定性”这个词,而是改用“模糊”。这个区别在某些数学家眼里是不存在的,比如弊校数学系的彭院士及其团队,但是,有一个问题:
虽然我们可以用非贝叶斯决策理论描述概率分布未知的情况了,可是“创新”造成的概率分布未知,与非贝叶斯决策理论中描述的概率分布未知,是一回事吗?这些理论中的“模糊”,就是奈特所说的“不确定性”吗?
不是。
五、小世界假设与残差项中的开放宇宙
问一个问题:经济学为什么要考虑决策问题?经济学对市场结果的直接预测是通过“均衡”的形式给出的,无论均衡是马歇尔的、瓦尔拉斯的还是纳什的。考虑决策问题,无非是所谓方法论个人主义的体现,是求解均衡性质的准备工作。那么,要看非贝叶斯决策理论与奈特不确定性的区别,最直接的方法是把非贝叶斯决策理论用到市场问题当中去——毕竟,奈特提出的并不是决策理论,而是经济理论。
一旦遇到市场,非贝叶斯理论的问题就暴露出来了,特别是遇到创新问题。
我们以纳什均衡为例,假设:一个双寡头垄断市场,两个厂商一开始都生产同样的产品,为了击败对手,双方都试图对自己的产品进行革命性的升级,但是由于双方的保密工作都很严密,所以双方都不知道对手革新出了一个什么东西。现在,双方同时考虑是否要把新产品投入市场,此时,他们面临奈特不确定性。
那么,传统的博弈模型,哪怕是假设了非贝叶斯决策理论,能分析这种情况吗?我们猛然发现,博弈论模型(演化博弈除外),无论怎样定义知识结构和均衡,都有一个先决条件,即事先知道对手所有可能的策略。否则,这一套完整的优化技术全部失效,均衡都不知道怎么定义。
可是如果这样,我作为A公司的总经理,根本就不知道B公司要出什么招数。我不仅不知道他“会怎样出招”,更不知道他“有什么招可出”。这就像面对泰拳高手的王语嫣一样,任她翻遍自家所有武学典籍,也可能想不到对面那个怪人的杀招是头和膝盖。
这种“不知道对手有什么招数可出”的状态,不仅仅是因为“知道很困难”,更是因为逻辑上就不可能:因为B公司所做的是一个创新,那么从逻辑上只有对手自己知道这个革新是什么,如果A能想象出来,那么B公司的新产品就不能算创新了。换言之,创新的东西一定是其他人想象都想象不出来的东西,否则就不叫创新了。
我们回头看萨维奇 A-A体系和上述所有非贝叶斯决策理论,我们能发现一个奇怪的东西,那就是,换言之,经济中所有可能的外部状态是已知的,而且是有限的。这个假设被萨维奇本人称作“小世界”假设。
集合有限且已知,这种假设对数学家来说再自然不过了,但是放在经济学问题当中就产生了数学家预想不到的问题。有限尚且好办,决策理论家已经证明,上述结论可以在一些假设成立时至少被推广到可数多个,但是“已知”这个假设非常难办。从上面的企业创新的例子中我们看到了,只要集合
的结构是博弈双方的共同知识,那么创新就不存在,毕竟,对手的行动本质上构成了自己决策时的
。而
中的每一个
是什么,决定了双方的支付函数,而在这一前提下不可能知道当
发生时任何一方的效用。
有人会问:那把这个假设拿掉不就是了?
可是,回想第一节(我写那个第一节真的是有目的的!),我们发现了一个东西:一个上的测度
是概率测度必然使得
!结合可加性,我们必然有
现在假如我知道,而
里面到底还有什么我一无所知,还有多少不可分的状态?每个状态都是什么?都不知道。那么,我们只能知道
这句话告诉我们,是
中的一员的概率,加上它不是其中一员的概率,等于一。我们能知道的仅此而已。
因此,在创新问题当中,我们不可避免地遇到一个残差项,这个残差项中包含着所有我们想象不出来的自然状态,一个除了所有我已知的自然状态之外的事件。这个事件不是不可分的,里面包含着逻辑上可能无穷多的不可分状态。
我们不可能说当这个残差事件发生时我们的payoff就是多少,就像A公司的经理不能断言如果B公司革新了自己的产品A公司的利润就是多少一样,毕竟,革新本身并不包含关于“如何革新”的任何信息。
用经济哲学大师宾默尔的话说,这表示“开放宇宙”,而当这个残差项不存在时,叫做“封闭宇宙”。这里的概念和数学里的开流形、闭流形很像,毕竟,物理学里面管闭流形宇宙就叫封闭宇宙。而在开放宇宙中,传统概率论必然无用。
概率是用来度量事件可能性的工具之一,按理说,对任何一个测度,只要对任意事件
,满足
,那么只要这个测度满足单调性,即
,它就足以构成一个这样的工具。
为什么人们不用任意的测度,而选择概率作为正统的分析方法呢?因为概率有很好的性质,一个事件发生的可能性越大,它的互补事件发生的可能性就越小,这是由两个事件概率之和等于一决定的。
在一个开放宇宙中,“互补事件”这样一个东西就不存在,只存在“条件互补事件”。两个事件取或关系是否就是整个根本无从得知,我们知道的只有“所有我们能想象出来的自然状态的概率之和不大于一”,至于到底是几,没人知道。
英国经济学家Shackle说,概率方法……
“仅代表了某一种表达判断的方法,这种方法隐含地假设了,只有那些已经被穷举出的互斥假设才是与决策相关的。因此,主观概率作为一种语言只能在这种确定的含义下被使用。而另一部分含义(受限于概率语言)必须被排除在外,这是武断而愚蠢的''。
往大处说,这也是整个数学的局限,数学描述的是给定的封闭环境,把一个系统中的所有东西都定义清楚,是数学工具分析问题的前提。但创新就不在这个范围里面,因为创新不可能被这样一个系统穷尽掉,理论家绝不可能先于企业家想出企业家会做什么,否则谁还甘愿拿那几千块工资天天撸数据呢?
那么,是不是就没办法了呢?不是。Shackle自1942年起的一系列研究,据我所知,是在解决这个问题上(哲学上)走的最深刻的理论。当然,(技术上)走得最远,也就是提出了最多技术细节的理论,叫Dempster-Shafer决策理论。
Shackle的博士论文导师是大名鼎鼎的哈耶克,所以他的作品带着浓郁的奥地利学派的风格。不过,最为人津津乐道的是,他在毕业之前接触到了当时同在LSE的凯恩斯及其团队。他迅速被凯恩斯的理论所吸引,所以,现在有人提到Shackle时,都管他叫“后凯恩斯主义者”,甚至以我微薄的知识,如果把卡尔多这些边缘人士剔除,他似乎就是后凯恩斯主义唯一的代言人,他的理论被誉为“用奥地利学派的方法推导出了凯恩斯主义的结论”。有意思吧~
Shackle的想法很简单,如果概率不是一个好的工具,那么就提出一个新工具,这个工具的关键在于能够不依赖于所有状态可能性之和等于某个数。也就是说,每个状态的可能性应该与其他事件的可能性无关。只有这样,创新才能与人的认知结合在一起。
可是这样做的话,没有了概率提供给我们的好的性质,决策怎么做就是一个大问题。上面也论证过,任给一个测度,好像都能满足要求,但是这个测度能不能帮我们发展出一套易操作的决策模型,就要打一个大问号了。
先说这个测度的挑选。Fishburn(1986)综述了概率的公理化性质,也就是说,概率本身是一个序数变量的基数表达,这与偏好和效用的关系是一样的。如果我们效仿偏好构建一个上的二元关系
,对任何事件
,
表示事件
与事件
”至少一样可能“。那么,给定几个基本的公理,可以找到一个函数
起到和效用函数一样的作用。一言以蔽之,概率是一个序数变量。
Shackle在1953年的文章中敏锐地捕捉到了这样一个事实,概率是序数的,但信念未必。他argue道,一个变量是基数的还是序数的,主要在于我们是否能够找到一个零点和一个量纲,只要[0,1]区间能够被良好的定义出来,这个变量就能被称作基数的。对比一下,温度就是一个基数变量,0摄氏度就是水结冰的临界点,而量纲“摄氏度”无非是水结冰的临界点和水沸腾的临界点之间水银汞柱变化的一百分之一。而效用就是一个序数概念,因为首先0效用是一个很令人费解的状态,另外,我们也很难给所谓“快乐”找一个单位。
那么信念呢?如果我们用主观概率表达信念,它当然是序数的。但Shackle想到了另一个度量,叫做“潜在惊讶”。简单说,如果主观上一件事发生的可能性很大,那么,当这件事发生时,我不会感到太惊讶,如果这件事发生的可能性很小,那么,如果这件事发生我会非常惊讶。当然,任何人都不能预见事情真的发生了我能有多惊讶,但是人牛X的地方就是能做反事实的想象,我能问“如果某件事发生了我惊讶吗”这种问题。于是,惊讶构成了事件“不可能性”的一个测度,惊讶越大,越不可能。
Shackle首先论证,潜在惊讶是一个基数变量,因为,首先,“一点儿也不惊讶”是一个非常自然的东西,零点有了。另外,惊讶肯定有上限,这没问题,因为惊讶过度了人类肯定会死,于是量纲有了。发现它是一个基数变量带来了一个方便,那就是潜在惊讶这个测度在不同的事件之间完全没有替代关系:抛一枚硬币,人可以对两个可能的结果都不感到惊讶,但在概率语言中,两者概率之和必为一。
在这套理论中,知识即是某个特定行动与某个特定结果之间的因果关系,而人具有的对某件事情感到惊讶的能力,恰恰就是波兰尼意义下的”身体知识“,抑或哈耶克意义下的”默会知识“,是不依赖于人类引以为荣的”认知能力“而存在的知识系统。这与概率这一套依赖于严格数学建构的逻辑知识不同,也就因此存在很多逻辑漏洞。针对潜在惊讶对行为进行建模的困难可想而知。不过,Shackle自己还是提出了一个后世看来问题最小的理论。
首先,依据”惊讶“的逻辑,可以画出这样一张图:
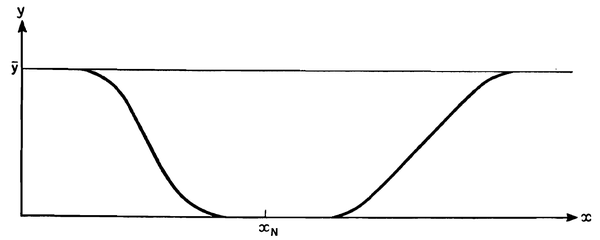 这里横轴代表结果,纵轴代表结果对应的潜在惊讶指数。其中,存在着一个潜在惊讶为0的点,与这个点偏离越大,潜在惊讶也就越”不小“。有人会问,这不就是把一个概率密度函数倒过来吗?不是,抛开其他差异不谈,潜在惊讶根本不要求整个函数积分出来是一个定值。更重要的是,这个函数,根据定义,不是一个可加测度,也就不能求勒贝格积分,期望效用也就无从谈起(参考前文的Choquet期望效用)。
这里横轴代表结果,纵轴代表结果对应的潜在惊讶指数。其中,存在着一个潜在惊讶为0的点,与这个点偏离越大,潜在惊讶也就越”不小“。有人会问,这不就是把一个概率密度函数倒过来吗?不是,抛开其他差异不谈,潜在惊讶根本不要求整个函数积分出来是一个定值。更重要的是,这个函数,根据定义,不是一个可加测度,也就不能求勒贝格积分,期望效用也就无从谈起(参考前文的Choquet期望效用)。
那么,决策怎么制定呢?
我们发现,潜在惊讶的最小值把整个横轴分成了两半,直观看,左边可以称之为”失望“,左边可以称作”惊喜“,因为,以左边为例,任何一个曲线上的点都代表着正的惊讶水平和低于不惊讶水平的收入,就是一种”不好的惊讶“,也就是失望。Shackle从他多年从事银行工作的经验中内省出这样一个三步的decision rule:
第一步,打开冰箱门……哦不,引入一个叫做注意力的函数:
,也就是说,对于任何一个财富水平x和这一财富水平对应的惊讶程度y,存在一个注意力的大小A(x,y)。
第二步,在”惊喜“和”失望“两个区段内分别求导致最高注意力的那对儿x和y,也就是
再
这里,是求解出的”焦点收益“,即收益中最让决策者倾注注意力的一个,对称的,
就表示”焦点损失“。e和d这两个下表借鉴了Gul(1991)的”elation-disappointment分解“的用法。
第三步,假定存在上的效用函数
,对第一个自变量递减,对第二个自变量递增。此时,由于行动与潜在惊讶函数是同胚对应的,因此,就有了
看吧,一个不依赖于期望、概率和小世界假设的决策理论诞生了。
来源:知乎 www.zhihu.com
作者:陈茁
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载