发表于
2017-02-26 04:32:55
写在老梁事件发生之际

发表于
2017-02-15 01:23:00
克罗恩病

发表于
2017-01-19 05:19:00
LeetCode题目解答——第311到371题
发表于
2016-12-25 20:44:34
一些前端框架的比较(下)——Ember.js和React

发表于
2016-12-23 00:11:07
一些前端框架的比较(上)——GWT、AngularJS和Backbone

发表于
2016-12-21 18:45:07
技术光谱

发表于
2016-12-03 15:41:02
文档那些事儿
发表于
2016-11-19 04:10:43
游戏中的货币和通货膨胀
忽然想谈谈这个话题,是因为最近开始接触一款游戏《Path of Exile》。它可以说是市面上最接近暗黑II的游戏,甚至比暗黑III还要接近。作为一个暗黑II的十多年的爱好者,它自然引起了我的兴趣。我渐渐发现它有许多吸引我的地方,而其中关于游戏中货币的设计和对通货膨胀的压制都很值得玩味。不可否认《暗黑破坏神II》影响了一代人,也影响了无数后续的游戏设计制作人,其中不少独创性的设计都让人印象深刻。比如从1.10开始成熟的技能树和技能加成系统,比如地图自动生成系统,比如怪物、武器装备的生成规则(前缀、后缀等等),再比如真实化打击感的设计(打击感即便放到今天依然先进)等等。毫无疑问我从太多的游戏后辈中看到了暗黑的影子。比如《泰坦之旅》,比如《Fate》,比如《火炬之光》,甚至一度在国内大热的《传奇》和《秦殇》。《Path of Exile》未必是这些后辈中最有名的,但却是风格上最接近的,而且有许多很有意思的创意设定。比如发扬光大的庞大技能树系统,每个角色都有更容易修炼的技能树分支,但是却没有严格的限制,因此角色的发展是自由的。货币体系则是另一个非常有创意的设计。首先,暗黑II,甚至包括接下来的暗黑III,金币往往失去了它本该具备的意义。尤其是暗黑II,有句话叫做“最不值钱的就是钱”——大量的金币无处消耗,似乎游戏中的“赌博”是唯一一个值得投入的地方,但是在后期能够通过赌博得到对角色有价值
...继续阅读
(60)
发表于
2016-11-16 05:33:36
写在孩子出生以后
发表于
2016-10-25 04:16:02
从工具使用的痛苦说开去

发表于
2016-09-15 05:13:39
谈谈月饼事件

发表于
2016-09-06 03:12:29
关于奥运会,一点印象和看法

发表于
2016-08-19 07:28:59
工作流系统的设计
发表于
2016-07-08 23:54:16
又到一年引援时

发表于
2016-06-21 05:56:12
写给实习生的第一天

发表于
2016-06-19 16:10:20
保卫萝卜

发表于
2016-06-11 17:36:53
亲历美国医疗
发表于
2016-05-21 18:48:38
Spark性能优化——和shuffle搏斗

发表于
2016-04-28 05:38:21
记录一种工作流心跳机制的设计
发表于
2016-04-07 05:56:09
副业?副业才有趣,才精彩

发表于
2016-03-29 05:31:13
生活不止眼前的苟且,还有诗和远方
生活不止眼前的苟且,还有诗和远方的田野。你赤手空拳来到人世间,为找到那片海不顾一切。这就是高晓松写的歌,许巍唱的歌。没有漂亮的修饰,没有华丽效果,始终偏执地保持风格,简单、安静、述说,触动心弦。我记得在十多年前,写过一些文字,祭奠民谣、诗歌和九十年代。如今听到高晓松的歌,如今回忆起故事、欢笑和逝去的时光,在旧有的感怀和失落的同时,还有一丝快慰。九十年代有那么多有理想的音乐人,那些音乐伴着我们一起长大。我们学会了珍惜,学会了倾听,也学会了扬起头,守护心里面那一小点微弱而坚强的信念。因此,我们是幸福的,我们有朴树,无印良品、老狼、Beyond、罗大佑……想想现在的孩子们,这方面他们无疑是不够幸运的,他们只能每天被那些爱来爱去的快餐歌曲如水从双耳倒灌。连情怀和怜悯都已经被拿来赚钱了,长大以后,我们认识这个世界越多,越发现现今自己的可悲。生活变好了,如今的物质条件已经比九十年代好很多。但是我们有营养的思考在变少。生活的妥协越来越多,不由自主也越来越多。大多数时候,我们忙起来就忘记了初衷。多说无益,谨以此短短的文字,给自己一点激励,努力去活出诗和远方的生活。(以下是这首歌的YouTube视频)文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接《四火的唠叨》===================下面是分享到代码=====================分
...继续阅读
(53)
发表于
2016-03-11 08:38:04
从淘汰Oracle数据库的事情说起

发表于
2016-03-07 05:25:16
Notes: Spark metrics
发表于
2016-02-16 06:22:45
三次性能优化经历

发表于
2016-02-11 06:52:03
研发团队的角色和构成

发表于
2016-02-04 03:10:16
历史,科学,还有艺术

发表于
2016-01-22 02:13:42
沈阳、南京、北京和西雅图

发表于
2016-01-17 04:44:45
谈谈百度血友病吧被卖事件

发表于
2015-12-21 06:55:27
Spark的性能调优
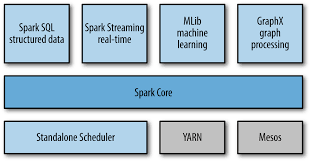
发表于
2015-12-16 06:56:59
LeetCode题目解答——第227到310题