相关标签
厉建强
发表于
2023-04-03 17:55:22
陈想读名著
发表于
2023-04-03 16:39:50
许多的小兵器
发表于
2023-04-01 10:16:47
知乎体育
发表于
2023-03-29 10:56:26
犬君拌汪酱
发表于
2023-03-27 13:49:14
王潇-潇洒姐
发表于
2023-03-24 18:59:42
小林
发表于
2023-03-24 14:55:10
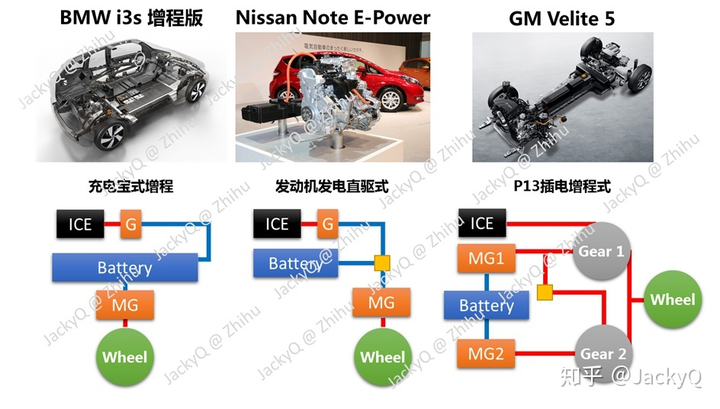
JackyQ
发表于
2023-03-24 14:46:54
阿福说车
发表于
2023-03-24 14:46:35
bank
发表于
2023-03-24 14:10:27
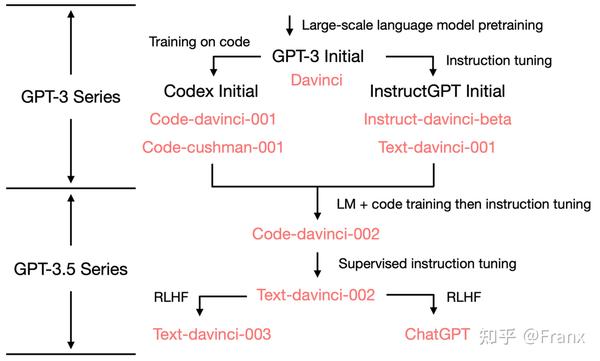
Franx
发表于
2023-03-23 21:23:03
萌酥
发表于
2023-03-23 10:52:16
夏释
发表于
2023-03-20 13:52:47
王大富
发表于
2023-03-20 12:40:36
复利大叔
发表于
2023-03-19 18:00:07
王波
发表于
2023-03-19 16:23:31
厉建强
发表于
2023-03-17 20:41:39
无月白熊
发表于
2023-03-16 18:10:51
张俊林
发表于
2023-03-15 21:09:44
知乎汽车
发表于
2023-03-14 16:59:39
王潇-潇洒姐
发表于
2023-03-14 16:46:43
弗兰克扬
发表于
2023-03-14 16:25:22
君君
发表于
2023-03-13 13:56:51
分形橙子
发表于
2023-03-12 17:48:45