发表于
2015-10-20 10:58:03
出门问问宣布完成由Google投资的C轮融资,累计融资7500万美金
注:出门问问是我们的老朋友,创始人李志飞也是NLP和机器翻译领域的大牛,今天出门问问拿到了Google的C轮融资,志飞兄第一时间和我分享了这条新闻,太牛了。人工智能创业公司出门问问(Mobvoi),于近日完成了由Google投资的C轮融资,累计融资7500万美金。现有投资方包括红杉资本、真格基金,SIG海纳亚洲、圆美光电、及歌尔声学。此轮投资Google并不控股,出门问问团队依旧有绝对控制权。此次由Google投资的C轮融资,能够保证出门问问在人工智能领域长期持续深耕,专注核心技术上的进一步研发,在可穿戴、车载以及机器人领域拓展新的人机交互产品形态,更深入地完善用户体验,在吸引全球顶尖技术与商务人才上更具优势。对于海外市场的扩展,此次融资也将发挥非常重要的作用。Google 企业发展部副总裁Don Harrison 说到选择投资出门问问的原因:“出门问问研发了非常独特自成体系的语音识别与自然语言处理技术。我们被他们的创新科技与发展潜力打动,所以我们很迅速地决定用投资的方式帮助他们在未来快速成长。”红杉资本全球执行合伙人沈南鹏评价:“出门问问一直处于高速的不断创新过程中,从移动app到硬件产品到语音搜索平台,不同形式的产品背后是团队长期以来形成的强大技术核心,获得Google的投资是对这种中国原创能力的最好肯定。我很高兴Google这样的巨头看好出门问问,并和我们一起投入到这支高速创
...继续阅读
(42)
发表于
2015-09-14 04:43:54
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络
发表于
2015-08-25 15:10:26
用MeCab打造一套实用的中文分词系统(四):MeCab增量更新
最近在处理NLPJob的一些数据,发现之前训练的Mecab中文分词工具包还有一些问题,所以想到了为NLPJob定制一个MeCab中文分词器,最简单的方法就是整理一批相关的词条,可以通过词条追加的方法加到原有的Mecab中文分词词典中去,这个可以参考《日文分词器Mecab文档》中介绍的“词条追加”方法,既可以放到系统词典中,也可以放到用户词典中,很方便。不过这个还不是最佳方案,之前有用户在《用MeCab打造一套实用的中文分词系统》中留言:你好, 我在win7上训练的时候mecab-cost-train的时候会崩溃,请问下我能每次只训练一小部分,然后最后一起发布嘛?我google了一下,发现MeCab的作者Taku Kudo在google plus上给了一个增量更新的方案:https://plus.google.com/107334123935896432800/posts/3g83gkBoSYE当然这篇文章是用日文写得,不过如果熟悉Mecab的相关脚本,很容易看懂。增量更新除了可以解决在小内存机器上分批训练模型外,也可以很容易在一个已有的基准分词模型上定制特定领域的分词器,既更新词典,也更新模型,这才是我理想中NLPJob中文分词器的定制之路。按照这条路子,我预处理了一下NLPJob中的数据,包括提取和校正了公司名,在已有的Mecab-Chinese中文工具包的基础上,手工标记一批N
...继续阅读
(116)
发表于
2015-07-15 09:31:40
斯坦福大学深度学习与自然语言处理第三讲:高级的词向量表示
斯坦福大学在三月份开设了一门“深度学习与自然语言处理”的课程:CS224d: Deep Learning for Natural Language Processing,授课老师是青年才俊Richard Socher,以下为相关的课程笔记。第三讲:高级的词向量表示(Advanced word vector representations: language models, softmax, single layer networks)推荐阅读材料:Paper1:[GloVe: Global Vectors for Word Representation]Paper2:[Improving Word Representations via Global Context and Multiple Word Prototypes]Notes:[Lecture Notes 2]第三讲Slides [slides]第三讲视频 [video]以下是第三讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。回顾:简单的word2vec模型代价函数J其中的概率函数定义为:我们主要从内部向量(internal vector)$v_{w_I}$导出梯度计算所有的梯度我们需要遍历每一个窗口内的中心向量(center vector)的梯度我们同时需要每一个外部向量(external vector
...继续阅读
(224)
发表于
2015-06-04 13:59:25
斯坦福大学深度学习与自然语言处理第二讲:词向量
发表于
2015-05-21 09:52:45
斯坦福大学深度学习与自然语言处理第一讲:引言
发表于
2015-04-28 13:59:14
用MeCab打造一套实用的中文分词系统(三):MeCab-Chinese
我在Github上发布了一个MeCab中文分词项目:MeCab-Chinese, 目的是提供一个用于中文分词和词性标注的MeCab词典和模型数据,类似MeCab日文IPA词典(mecab-ipadic),并且提供一些我自己用到的特征模板和脚本,方便大家从源头开始训练一个MeCab中文分词系统。自从上次在愚人节的时候发布了一个mecab中文词典和数据模型之后(《用MeCab打造一套实用的中文分词系统(二)》), 收到了一些反馈,而这些反馈又促使我深入的review了一下mecab,重新设计特征及特征模板,加入了一些新的词典数据,重新训练模型,感兴趣的同学可以先试试这个0.2版本: mecab-chinesedic-binary (链接:http://pan.baidu.com/s/1gdxnvFX密码: kq9g)注:目前所有发布的版本均默认utf-8编码,并且在Mac OS和Linux Ubuntu下测试有效,windows没有测试,感兴趣的同学可自行测试)了解和安装mecab仍请参考:日文分词器 Mecab 文档用MeCab打造一套实用的中文分词系统这里再补充一点,由于google code废弃的缘故,MeCab这个项目已经搬迁至github,但是一些资源反而不如之前那么好找了,可参考两个MeCab作者维护的页面:MeCab日文文档:http://taku910.github.i
...继续阅读
(112)
发表于
2015-04-01 15:05:48
用MeCab打造一套实用的中文分词系统(二)
虽然是愚人节,但是这个不是愚人节玩笑,最近花了一些时间在MeCab身上,越发喜欢这个来自岛国的开源分词系统,今天花了一些时间训练了一个更适用的模型和词典,打包提供给大家使用,因为数据和词典涉及到一些版权问题,所以打包文件里只是mecab用于发布的二进制词典和模型文件,目前在mac os和linux ubuntu系统下测试无误,其他系统请自行测试使用:链接:http://pan.baidu.com/s/1sjBfdXr密码: 8udf了解和安装mecab请参考:日文分词器 Mecab 文档用MeCab打造一套实用的中文分词系统使用前请按上述文档安装mecab,下载这个中文分词模型和词典之后解压,解压后得到一个mecab-chinese-data目录,执行:mecab -d mecab-chinese-data扬帆远东做与中国合作的先行扬帆 v,*,*,*,*,*,扬帆,*,*远东 ns,*,*,*,*,*,远东,*,*做 v,*,*,*,*,*,做,*,*与 p,*,*,*,*,*,与,*,*中国 ns,*,*,*,*,*,中国,*,*合作 v,*,*,*,*,*,合作,*,*的 u,*,*,*,*,*,的,*,*先行 vn,*,*,*,*,*,先行,*,*EOS上述第二列提供了词性标注结果。如果想得到单行的分词结果,可以这样执行:mecab -d ./mecab-chinese-d
...继续阅读
(84)
发表于
2015-03-12 13:13:25
中英文维基百科语料上的Word2Vec实验
最近试了一下Word2Vec,GloVe以及对应的python版本gensim word2vec和python-glove,就有心在一个更大规模的语料上测试一下,自然而然维基百科的语料进入了视线。维基百科官方提供了一个很好的维基百科数据源:https://dumps.wikimedia.org,可以方便的下载多种语言多种格式的维基百科数据。此前通过gensim的玩过英文的维基百科语料并训练LSI,LDA模型来计算两个文档的相似度,所以想看看gensim有没有提供一种简便的方式来处理维基百科数据,训练word2vec模型,用于计算词语之间的语义相似度。感谢Google,在gensim的google group下,找到了一个很长的讨论帖:training word2vec on full Wikipedia,这个帖子基本上把如何使用gensim在维基百科语料上训练word2vec模型的问题说清楚了,甚至参与讨论的gensim的作者Radim Řehůřek博士还在新的gensim版本里加了一点修正,而对于我来说,所做的工作就是做一下验证而已。虽然github上有一个wiki2vec的项目也是做得这个事,不过我更喜欢用python gensim的方式解决问题。关于word2vec,这方面无论中英文的参考资料相当的多,英文方面既可以看官方推荐的论文,也可以看gensim作者Radim Ře
...继续阅读
(436)
发表于
2015-03-07 10:05:47
HMM相关文章索引
HMM系列文章是52nlp上访问量较高的一批文章,这里做个索引,方便大家参考。HMM学习HMM学习最佳范例一:介绍HMM学习最佳范例二:生成模式HMM学习最佳范例三:隐藏模式HMM学习最佳范例四:隐马尔科夫模型HMM学习最佳范例五:前向算法HMM学习最佳范例五:前向算法1HMM学习最佳范例五:前向算法2HMM学习最佳范例五:前向算法3HMM学习最佳范例五:前向算法4HMM学习最佳范例五:前向算法5HMM学习最佳范例六:维特比算法HMM学习最佳范例六:维特比算法1HMM学习最佳范例六:维特比算法2HMM学习最佳范例六:维特比算法3HMM学习最佳范例六:维特比算法4HMM学习最佳范例六:维特比算法5HMM学习最佳范例七:前向-后向算法HMM学习最佳范例七:前向-后向算法1HMM学习最佳范例七:前向-后向算法2HMM学习最佳范例七:前向-后向算法3HMM学习最佳范例七:前向-后向算法4HMM学习最佳范例七:前向-后向算法5HMM学习最佳范例八:总结HMM学习最佳范例全文文档PDF百度网盘-密码f7azHMM相关wiki上一个比较好的HMM例子几种不同程序语言的HMM版本HMM应用HMM词性标注HMM在自然语言处理中的应用一:词性标注1HMM在自然语言处理中的应用一:词性标注2HMM在自然语言处理中的应用一:词性标注3HMM在自然语言处理中的应用一:词性标注4HMM在自然语言处理中的应用一
...继续阅读
(64)
发表于
2015-01-31 05:38:19
PRML读书会第十四章 Combining Models
发表于
2015-01-31 05:29:32
PRML读书会第十三章 Sequential Data

发表于
2015-01-31 04:49:12
PRML读书会第十二章 Continuous Latent Variables
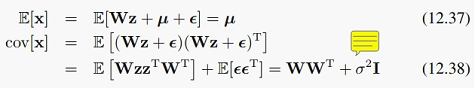
发表于
2015-01-31 04:40:38
PRML读书会第十一章 Sampling Methods
