发表于
2018-05-12 09:23:02
Python 字典的原理及高级用法
算算时间有段时间没写技术类的文章了,部分原因是最近过得确实比较忙。当然,也并没有忙到完全抽不出时间写博客,根本原因还是没有找到啥好的写作素材,随随便便糊弄一篇我又有点不好意思发上来,于是乎,就一直搁置到现在。对于字典这一基础的数据结构来说,其对 Python 的程序重要性是无可替代的,在《代码之美》一书中,作者是这么描述的:字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它。——A.M.Kuchling在 Python 程序里,无论是模块、函数、还是对象,均有自己的「命名空间」,而这命名空间即为一个字典(dict),key 就是变量名,value 就是变量值,除去「命名空间外」,对象的函数(方法)关键字也是存放在字典中,此时的 key 就是函数(方法)名,value 就是该函数(方法)的引用。可以采用 __builtins__.__dict__ 来查看这些函数(方法)。字典的原理Python 的字典是依据散列表(也叫哈希表)来实现的,首先简单介绍一下散列表的原理。散列表中的每一个单元称为表元。在 dict 的实现里,每个 key-value 均占用一个表元,其中 key 为键的引用(这里是键的引用,而不是键本身,因为 key 可以为任意可散列对象),value 为值的引用。因为是引用:表元大小均一致,所以可通过偏移量来读取某个表元。在 Python
...继续阅读
(46)
发表于
2018-05-12 09:23:02
Python 字典的原理及高级用法
算算时间有段时间没写技术类的文章了,部分原因是最近过得确实比较忙。当然,也并没有忙到完全抽不出时间写博客,根本原因还是没有找到啥好的写作素材,随随便便糊弄一篇我又有点不好意思发上来,于是乎,就一直搁置到现在。对于字典这一基础的数据结构来说,其对 Python 的程序重要性是无可替代的,在《代码之美》一书中,作者是这么描述的:字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它。——A.M.Kuchling在 Python 程序里,无论是模块、函数、还是对象,均有自己的「命名空间」,而这命名空间即为一个字典(dict),key 就是变量名,value 就是变量值,除去「命名空间外」,对象的函数(方法)关键字也是存放在字典中,此时的 key 就是函数(方法)名,value 就是该函数(方法)的引用。可以采用 __builtins__.__dict__ 来查看这些函数(方法)。字典的原理Python 的字典是依据散列表(也叫哈希表)来实现的,首先简单介绍一下散列表的原理。散列表中的每一个单元称为表元。在 dict 的实现里,每个 key-value 均占用一个表元,其中 key 为键的引用(这里是键的引用,而不是键本身,因为 key 可以为任意可散列对象),value 为值的引用。因为是引用:表元大小均一致,所以可通过偏移量来读取某个表元。在 Python
...继续阅读
(18)
发表于
2018-04-19 18:11:12
《代码整洁之道》读书笔记
相对于任何宏伟愿景,对细节的关注甚至是更为关键的专业性基础。首先,开发者通过小型实践获得可用于大型实践的技能和信用度。其次,宏大建筑中最细小的部分,比如关不紧的门、有点儿没铺平的地板,甚至是凌乱的桌面,都会将整个大局的魅力毁灭殆尽。这就是整洁代码之所系。本书「序」中的这段话完美的诠释了作者写本书的意义。(简评在最后)序神在细节之中。5S 哲学包括以下概念:整理(Seiri)整顿(Seiton)清楚(Seiso)清洁(Seiketsu)身美(Shitsuke)整洁代码有人也许以为,关于代码的书有点落后于时代——代码不再是问题:我们应当关注模型和需求。……扯淡!我们永远抛不掉代码,因为代码呈现了需求的细节。在某些层面上,这些细节无法被忽略或抽象,必须明确之。将需求明确到机器可以执行的细节程度,就是编程要做的事。而这种规约正是代码。勒布朗(LeBlanc)法则:稍后等于永不(Later equals never)。多数人都知道一幅画是好还是坏。但能分辨优劣并不表示懂得绘画。能分辨整洁代码和肮脏代码,也不意味着会写整洁代码!Bjarne Stroustrup(C++ 语言发明者):我喜欢优雅和高效的代码。代码逻辑应当直截了当,叫缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,高处一堆混乱来,整洁的代码只做好一件事。G
...继续阅读
(38)
发表于
2018-04-19 18:11:12
《代码整洁之道》读书笔记
相对于任何宏伟愿景,对细节的关注甚至是更为关键的专业性基础。首先,开发者通过小型实践获得可用于大型实践的技能和信用度。其次,宏大建筑中最细小的部分,比如关不紧的门、有点儿没铺平的地板,甚至是凌乱的桌面,都会将整个大局的魅力毁灭殆尽。这就是整洁代码之所系。本书「序」中的这段话完美的诠释了作者写本书的意义。(简评在最后)序神在细节之中。5S 哲学包括以下概念:整理(Seiri)整顿(Seiton)清楚(Seiso)清洁(Seiketsu)身美(Shitsuke)整洁代码有人也许以为,关于代码的书有点落后于时代——代码不再是问题:我们应当关注模型和需求。……扯淡!我们永远抛不掉代码,因为代码呈现了需求的细节。在某些层面上,这些细节无法被忽略或抽象,必须明确之。将需求明确到机器可以执行的细节程度,就是编程要做的事。而这种规约正是代码。勒布朗(LeBlanc)法则:稍后等于永不(Later equals never)。多数人都知道一幅画是好还是坏。但能分辨优劣并不表示懂得绘画。能分辨整洁代码和肮脏代码,也不意味着会写整洁代码!Bjarne Stroustrup(C++ 语言发明者):我喜欢优雅和高效的代码。代码逻辑应当直截了当,叫缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,高处一堆混乱来,整洁的代码只做好一件事。G
...继续阅读
(19)
发表于
2018-03-31 15:03:31
Nextcloud 搭建私人云服务教程
我一直很不相信国内的那些云服务提供商(尤其是在李彦宏发表的讲话「中国用户对隐私问题没那么敏感,在个人隐私方面更加开放,一定程度上愿用隐私换方便和效率」后),因为怕隐私得不到保障,故而我的一些隐私数据都是存放在国外的云盘(如 Dropbox、Drive 等)上。可这俩在国内都被墙了,而手机翻墙总是显得有些不够方便,与是我就琢磨着自己搭建一个云服务,随后就发现了 Nextcloud 这一开源云服务。而网上的教程都太过复杂了,对新手太过不友好,于是乎——一篇近乎傻瓜式的 Nextcloud 教程诞生了。安装这里采用 Docker 容器方式来安装 Nextcloud,这样就不用担心各种环境依赖了(Nextcloud 的依赖简直多得吓人,而 Dockerfile 会帮你把依赖都配置好)安装 Docker注:Docker 仅支持 64-bit 的系统Docker 现已被各大发行版的仓库收入,采用正常安装命令即可:yum -y install docker随后,启动 Docker 守护进程:# systemctl
systemctl start docker
# Service
service docker start安装 NextCloud自动安装有了 Docker 后,就可以几行代码安装 Nextcloud 了:# clone nextcloud 的 docker 容器
git clone
...继续阅读
(44)
发表于
2018-03-31 15:03:31
Nextcloud 搭建私人云服务教程
我一直很不相信国内的那些云服务提供商(尤其是在李彦宏发表的讲话「中国用户对隐私问题没那么敏感,在个人隐私方面更加开放,一定程度上愿用隐私换方便和效率」后),因为怕隐私得不到保障,故而我的一些隐私数据都是存放在国外的云盘(如 Dropbox、Drive 等)上。可这俩在国内都被墙了,而手机翻墙总是显得有些不够方便,与是我就琢磨着自己搭建一个云服务,随后就发现了 Nextcloud 这一开源云服务。而网上的教程都太过复杂了,对新手太过不友好,于是乎——一篇近乎傻瓜式的 Nextcloud 教程诞生了。安装这里采用 Docker 容器方式来安装 Nextcloud,这样就不用担心各种环境依赖了(Nextcloud 的依赖简直多得吓人,而 Dockerfile 会帮你把依赖都配置好)安装 Docker注:Docker 仅支持 64-bit 的系统Docker 现已被各大发行版的仓库收入,采用正常安装命令即可:yum -y install docker随后,启动 Docker 守护进程:# systemctl
systemctl start docker
# Service
service docker start安装 NextCloud自动安装有了 Docker 后,就可以几行代码安装 Nextcloud 了:# clone nextcloud 的 docker 容器
git clone
...继续阅读
(18)
发表于
2018-03-21 10:47:45
没有希望的事儿,还有坚持的必要吗
「你说,没有希望的事,还有坚持的必要吗?」确实是没想到,看国产青春剧也能看出了共鸣。忘记很早之前在哪看到过一句话:人会长大三次。第一次是在发现自己不是世界中心的时候;第二次是在发现即使再怎么努力,终究还是有些事令人无能为力的时候;第三次是在明知道有些事可能会无能为力,但还是会尽力争取的时候。最初看这句话还没什么感觉,最近看了「最好的我们」后,突然就触动了。那种触动,想来就是怎么也绕不开的「成长」了:自己做了想做的事,而生活却没有给自己想要的结果。于是乎,以后再遇见了想做的事,开始犹豫了,开始畏缩了,开始计较得失了,因为有了之前的经历,担心自己做了,却也得不到自己想要的结果。你当然可以说是因为自己长大了,会计较得失了、不会像小时候一样:想干什么就去干什么。是啊,第二次成长的你知道了有些事情即使再怎么努力,也不会得到满意的结果,于是干脆就不去做了。可目前处于不明成长阶段的我啊,又觉得凡事要是都仔细衡量得失后再去想做还是不做的话,那人生想必会少掉许多乐趣、会错过许多事情。我果然还是不适合看电视剧,花了一个月时间才把《最好的我们》看完(小时候那种看电视剧甚至广告时间都不愿意转台生怕错过衔接部分的劲儿都不知道哪去了,以后有时间还是多看看电影和书),听说还有几部青春剧也挺不错(《你好,旧时光》、《一起同过窗》等),就不看了,虽说确实能勾起高中时的那些或苦涩或美好的回忆,可那些回忆却再也不可得了
...继续阅读
(44)
发表于
2018-03-21 10:47:45
没有希望的事儿,还有坚持的必要吗
「你说,没有希望的事,还有坚持的必要吗?」确实是没想到,看国产青春剧也能看出了共鸣。忘记很早之前在哪看到过一句话:人会长大三次。第一次是在发现自己不是世界中心的时候;第二次是在发现即使再怎么努力,终究还是有些事令人无能为力的时候;第三次是在明知道有些事可能会无能为力,但还是会尽力争取的时候。最初看这句话还没什么感觉,最近看了「最好的我们」后,突然就触动了。那种触动,想来就是怎么也绕不开的「成长」了:自己做了想做的事,而生活却没有给自己想要的结果。于是乎,以后再遇见了想做的事,开始犹豫了,开始畏缩了,开始计较得失了,因为有了之前的经历,担心自己做了,却也得不到自己想要的结果。你当然可以说是因为自己长大了,会计较得失了、不会像小时候一样:想干什么就去干什么。是啊,第二次成长的你知道了有些事情即使再怎么努力,也不会得到满意的结果,于是干脆就不去做了。可目前处于不明成长阶段的我啊,又觉得凡事要是都仔细衡量得失后再去想做还是不做的话,那人生想必会少掉许多乐趣、会错过许多事情。我果然还是不适合看电视剧,花了一个月时间才把《最好的我们》看完(小时候那种看电视剧甚至广告时间都不愿意转台生怕错过衔接部分的劲儿都不知道哪去了,以后有时间还是多看看电影和书),听说还有几部青春剧也挺不错(《你好,旧时光》、《一起同过窗》等),就不看了,虽说确实能勾起高中时的那些或苦涩或美好的回忆,可那些回忆却再也不可得了
...继续阅读
(22)
发表于
2018-03-07 12:23:06
QQ 音乐外链解析

发表于
2018-03-07 12:23:06
QQ 音乐外链解析
发表于
2018-02-22 19:38:04
一台 VPS 的正确打开方式

发表于
2018-02-22 19:38:04
一台 VPS 的正确打开方式
发表于
2018-01-26 17:11:29
《黑客与画家》读书笔记
去年年底那会,花了大概一周多时间,阅读完了《黑客与画家》这本书,收获颇丰。可惜当时确实没多少时间整理出读书笔记,期末考试结束后,回到家中,本想着有时间能好好补一下博客,结果回家之后也没有想象中的空闲,看着「搬瓦工」把每年 20$ 的套餐补货了,于是就购置了一台服务器,将博客源码从 GitHub 上转移到了自己的服务器上,还拿 Golang 重写了一下「一言」的 API(扯远了,服务器的事等以后再开一篇博客说说),还补了一部早已加入想看列表却一直没看的番——「反叛的鲁路修」(嘻嘻 😌)。直到今天,才终于有时间能把这篇读书笔记给整理出来了,笔记是直接在 Kindle 上标注的,然后用「Clippings.io」这个工具导出(为什么 Kindle 不能开发一个好用一点的笔记管理系统呢!?)。好在 azw3 版本在 Kindle 上的体验还不错,即使有代码段排版也没有垮掉,所以决定原谅你。(👇以下为文摘)在一个人产生良知之前,折磨就是一种娱乐。程序写出来是给人看的,附带能在机器上运行。(这句话的出处是在《SICP》这本书的卷首语,作者引用了)如果有必要的话,大多数物理学家有能力拿到法国文学的博士学位,但是反过来就不行,很少存在法国文学的教授有能力拿到物理学的博士学位。人们喜欢讨论的许多问题实际上都是很复杂的,马上说出你的想法对你并没有什么好处。小时候,每个人都会鼓励你不断成长,变成一个心智
...继续阅读
(45)
发表于
2018-01-26 17:11:29
《黑客与画家》读书笔记
去年年底那会,花了大概一周多时间,阅读完了《黑客与画家》这本书,收获颇丰。可惜当时确实没多少时间整理出读书笔记,期末考试结束后,回到家中,本想着有时间能好好补一下博客,结果回家之后也没有想象中的空闲,看着「搬瓦工」把每年 20$ 的套餐补货了,于是就购置了一台服务器,将博客源码从 GitHub 上转移到了自己的服务器上,还拿 Golang 重写了一下「一言」的 API(扯远了,服务器的事等以后再开一篇博客说说),还补了一部早已加入想看列表却一直没看的番——「反叛的鲁路修」(嘻嘻 😌)。直到今天,才终于有时间能把这篇读书笔记给整理出来了,笔记是直接在 Kindle 上标注的,然后用「Clippings.io」这个工具导出(为什么 Kindle 不能开发一个好用一点的笔记管理系统呢!?)。好在 azw3 版本在 Kindle 上的体验还不错,即使有代码段排版也没有垮掉,所以决定原谅你。(👇以下为文摘)在一个人产生良知之前,折磨就是一种娱乐。程序写出来是给人看的,附带能在机器上运行。(这句话的出处是在《SICP》这本书的卷首语,作者引用了)如果有必要的话,大多数物理学家有能力拿到法国文学的博士学位,但是反过来就不行,很少存在法国文学的教授有能力拿到物理学的博士学位。人们喜欢讨论的许多问题实际上都是很复杂的,马上说出你的想法对你并没有什么好处。小时候,每个人都会鼓励你不断成长,变成一个心智
...继续阅读
(15)
发表于
2018-01-21 10:24:29
豆瓣电影 Top 250 数据分析
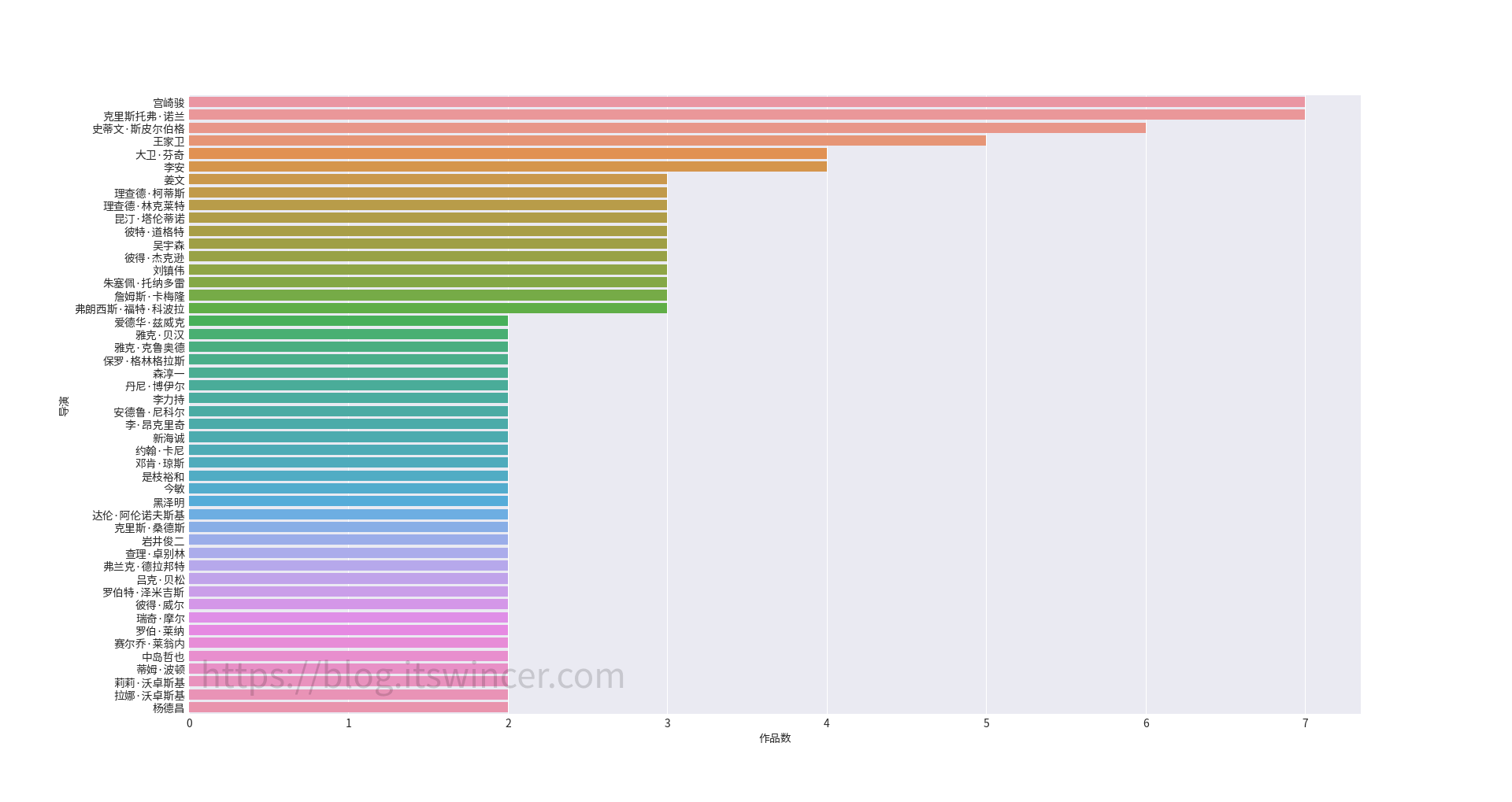
发表于
2018-01-21 10:24:29
豆瓣电影 Top 250 数据分析
发表于
2017-12-29 10:46:06
再见,2017
关于 2017 年,其实还真的有挺多想说的,也早就有想写一篇博客的想法了,差不多到今天才抽得出时间写。前几天和朋友聊天时谈到关于今年最有成就感的一件事,我想了一会,应该是搭建了这样一个博客。当初搭建博客的初衷其实很单纯:就是为了好玩,谁知从此就沉迷于此了。在之后的写博客的过程中甚至产生了一种当一个作家也还不错的想法(当然前提是我的文章还有人看😋),现在想想,与高中时期相比,我的想法是发生了一些转变(在高中时期的我是绝不可能产生这种想法的)。正如开始所说的,现在遇到点什么事就想写下来,在往年,我一直没有写年末总结的习惯。这种「创作欲」,类似作家:将自己内心的想法写成作品,实则是把自己的内心剖析给别人看。也渐渐有些明白卡尔·雅斯贝尔斯的那句「文学和科学相比,的确没什么用处,但文学最大的用处,也许就是它没有用处」的意思了。买了 kpw3 后,我很乐意培养自己的阅读习惯。大学时间其实还是比较宽松的,但我反而不能每天抽出一小时阅读时间。有时候看书没看两分钟,随便手机一个通知消息就能让我转移注意力——这也是我的缺点:当自己没有全神贯注的时候,很容易被其它的事情所吸引注意力(这也算我很迫切想改掉的一个坏习惯),也导致看了近两周才把《黑客与画家》这本书看完(书推过两天会补上)。是太浮躁了,也太焦虑了,或许是因为到了大三,面临找工作的压力,这压力不仅体现在看书上,有时我就莫名想快些完成正在做的事情,
...继续阅读
(59)
发表于
2017-12-29 10:46:06
再见,2017
关于 2017 年,其实还真的有挺多想说的,也早就有想写一篇博客的想法了,差不多到今天才抽得出时间写。前几天和朋友聊天时谈到关于今年最有成就感的一件事,我想了一会,应该是搭建了这样一个博客。当初搭建博客的初衷其实很单纯:就是为了好玩,谁知从此就沉迷于此了。在之后的写博客的过程中甚至产生了一种当一个作家也还不错的想法(当然前提是我的文章还有人看😋),现在想想,与高中时期相比,我的想法是发生了一些转变(在高中时期的我是绝不可能产生这种想法的)。正如开始所说的,现在遇到点什么事就想写下来,在往年,我一直没有写年末总结的习惯。这种「创作欲」,类似作家:将自己内心的想法写成作品,实则是把自己的内心剖析给别人看。也渐渐有些明白卡尔·雅斯贝尔斯的那句「文学和科学相比,的确没什么用处,但文学最大的用处,也许就是它没有用处」的意思了。买了 kpw3 后,我很乐意培养自己的阅读习惯。大学时间其实还是比较宽松的,但我反而不能每天抽出一小时阅读时间。有时候看书没看两分钟,随便手机一个通知消息就能让我转移注意力——这也是我的缺点:当自己没有全神贯注的时候,很容易被其它的事情所吸引注意力(这也算我很迫切想改掉的一个坏习惯),也导致看了近两周才把《黑客与画家》这本书看完(书推过两天会补上)。是太浮躁了,也太焦虑了,或许是因为到了大三,面临找工作的压力,这压力不仅体现在看书上,有时我就莫名想快些完成正在做的事情,
...继续阅读
(19)
发表于
2017-12-11 09:26:16
从 GnuPG 的使用谈谈密码学
前言我是一个很注重隐私的人,所以对密码学也就很感兴趣,这学期本着想进一步了解密码学的念头选了一门应用密码学的选修课(其实是为了混学分),虽说也没去过几次,但总想着这门课都快结束了总不能像没上过一样。这次借着 GnuPG(以下简称 GPG) 软件的使用也聊聊目前现代密码学中以密钥性质进行区分的两大加密方式。对称密钥加密大概半年前,写过一个暴力破解加密压缩文件的程序,说白了就是跑字典,不断的试密码,这只能破解常用密码,一旦用户采用随机生成的密码就无从下手。我们平时所用到的压缩加密大多都是对称性加密,即我们用同一字符串对文件进行加密,又用同一字符串进行解密(此时为了保证安全,密码需越复杂越好)。明文 <–> 密钥 <–> 密文对称加密很方便也很快速,但是也带来了一个很大的缺点,由于加密和解密用的都是同一密钥,在传输的过程中,要求双方取得相同的密钥,这会大大降低加密的安全性(注意:这里所说的不安全不是说对称加密算法不安全,而是从密钥的获取程度来说的,即密钥知道的人越少越安全)。在如今的互联网时代,通信双方分隔异地且素为谋面,则对称加密要求事先交换共同密钥的安全性也无法得到保障。公开密钥加密那么为了解决对称加密的安全隐患,非对称加密诞生了。
与对称加密不同的是,非对称加密的加密和解密所需要的密钥是不同的,而且知道了其中一方,想推导出另一方(需要解决一个数学难题),在量
...继续阅读
(47)
发表于
2017-12-11 09:26:16
从 GnuPG 的使用谈谈密码学
前言我是一个很注重隐私的人,所以对密码学也就很感兴趣,这学期本着想进一步了解密码学的念头选了一门应用密码学的选修课(其实是为了混学分),虽说也没去过几次,但总想着这门课都快结束了总不能像没上过一样。这次借着 GnuPG(以下简称 GPG) 软件的使用也聊聊目前现代密码学中以密钥性质进行区分的两大加密方式。对称密钥加密大概半年前,写过一个暴力破解加密压缩文件的程序,说白了就是跑字典,不断的试密码,这只能破解常用密码,一旦用户采用随机生成的密码就无从下手。我们平时所用到的压缩加密大多都是对称性加密,即我们用同一字符串对文件进行加密,又用同一字符串进行解密(此时为了保证安全,密码需越复杂越好)。明文 <–> 密钥 <–> 密文对称加密很方便也很快速,但是也带来了一个很大的缺点,由于加密和解密用的都是同一密钥,在传输的过程中,要求双方取得相同的密钥,这会大大降低加密的安全性(注意:这里所说的不安全不是说对称加密算法不安全,而是从密钥的获取程度来说的,即密钥知道的人越少越安全)。在如今的互联网时代,通信双方分隔异地且素为谋面,则对称加密要求事先交换共同密钥的安全性也无法得到保障。公开密钥加密那么为了解决对称加密的安全隐患,非对称加密诞生了。
与对称加密不同的是,非对称加密的加密和解密所需要的密钥是不同的,而且知道了其中一方,想推导出另一方(需要解决一个数学难题),在量
...继续阅读
(16)
发表于
2017-11-30 15:09:34
Web 性能优化(一)——使用 localStorage

发表于
2017-11-30 15:09:34
Web 性能优化(一)——使用 localStorage
发表于
2017-11-02 13:56:40
Poker 机械键盘开箱与简评

发表于
2017-11-02 13:56:40
Poker 机械键盘开箱与简评
发表于
2017-10-30 10:44:41
构建一言 API 踩坑记录

发表于
2017-10-30 10:44:41
构建一言 API 踩坑记录
发表于
2017-10-17 11:35:19
Linux 与 Windows 10 用 GRUB 引导教程
前言去年暑假的时候,写了一篇如何装 Linux 和 Windows 10 双系统的文章发在了简书上,我写这篇文章的原因是当初装双系统确实是折腾了许久,网上也找不到一篇详尽的教程。由于去年对于写教程还不是熟练,而这一年多的使用过程也遇到了一些问题,所以就准备「Refactoring」这篇文章。EFI 分区在教程正式开始之前,先花一点时间说明 EFI 分区的组成和作用。
首先,在你装了 Windows 之后,Windows 在装机过程中会将硬盘划分出一个约 100m 大小的分区,称为 EFI 分区这个分区就是起引导作用的。在资源管理器中是看不到的这个分区的,可以在磁盘管理中看到,管理则需要借助DG 工具。便于说明,在装好了 Linux 之后,我将 EFI 挂载至 boot 分区截图:可以看到,该分区包含 3 个文件夹(如果你没有装 Linux 的话,就只有两个),分别是 Boot、Microsoft 和 Manjaro,其中 Boot 文件夹就是 UEFI 引导所必需的文件。
我们继续打开Microsoft/Boot文件夹:这些文件就是启动 Windows 10 所必需的,包含了语言包、字体等,BCD 包含了 Windows 引导开始以后的信息。其中,bootmgfw.efi 是 Windows 默认引导文件。EFI/Boot/bootx64.efiEFI/Microsoft/Boot
...继续阅读
(45)
发表于
2017-10-17 11:35:19
Linux 与 Windows 10 用 GRUB 引导教程
前言去年暑假的时候,写了一篇如何装 Linux 和 Windows 10 双系统的文章发在了简书上,我写这篇文章的原因是当初装双系统确实是折腾了许久,网上也找不到一篇详尽的教程。由于去年对于写教程还不是熟练,而这一年多的使用过程也遇到了一些问题,所以就准备「Refactoring」这篇文章。EFI 分区在教程正式开始之前,先花一点时间说明 EFI 分区的组成和作用。
首先,在你装了 Windows 之后,Windows 在装机过程中会将硬盘划分出一个约 100m 大小的分区,称为 EFI 分区这个分区就是起引导作用的。在资源管理器中是看不到的这个分区的,可以在磁盘管理中看到,管理则需要借助DG 工具。便于说明,在装好了 Linux 之后,我将 EFI 挂载至 boot 分区截图:可以看到,该分区包含 3 个文件夹(如果你没有装 Linux 的话,就只有两个),分别是 Boot、Microsoft 和 Manjaro,其中 Boot 文件夹就是 UEFI 引导所必需的文件。
我们继续打开Microsoft/Boot文件夹:这些文件就是启动 Windows 10 所必需的,包含了语言包、字体等,BCD 包含了 Windows 引导开始以后的信息。其中,bootmgfw.efi 是 Windows 默认引导文件。EFI/Boot/bootx64.efiEFI/Microsoft/Boot
...继续阅读
(17)
发表于
2017-10-05 12:33:46
Kindle Papwerwhite 开箱 & 简评

发表于
2017-10-05 12:33:46
Kindle Papwerwhite 开箱 & 简评